正好手头有个demo,这里尽量用最简单的思路介绍一下。
说明,这个是给零基础的同学看的,不需要任何计算机基础。
同样,这个处理思路忽略了非常多的细节,只是为了让大家更好地理解原理而已。
1。首先看下如何提取特征,看这么多数字,眼睛都花了。
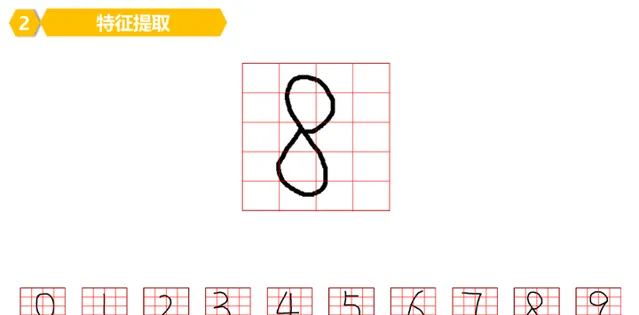
2。简单说就是把数字划分成很多很多的小块,比如下图这样:
每个数字被划分成了4*5=20个小块。
分好了小块以后,其实我们要知道每个小块是由很多个像素构成的。
或者这样理解,每个小块其实可以划分为更多的小块,即每个小块是由很多个更小的块构成的。
比如每个小块可能是100*100个更小的小块构成的。
为了叙述上的方便,把小块记为B(Bigger),更小的块记为S(Smaller)。
因此,比如数字8,是由5行4列共计:5*4=20个小块B构成。
每个小块B内其实是由100*100=100000个像素(更小块S)构成的。
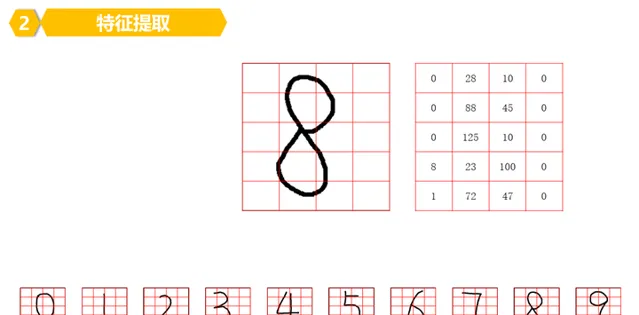
3。数一下每个小块B内,有多少个黑色的像素。
或者这样理解,每个小块B内有多少个更小块S是黑色的。
比如第一行:
以此类推,可以计算出每一行的每一个小块B的数字是多少,写好就好了。
这就是数字的特征,如果仔细观察,每个数字的特征是不一样的。
因为他们的每个小块B内的数字是不一致的。
4。为了方便,我们把得到的特征,排成一排(数组)就好了。
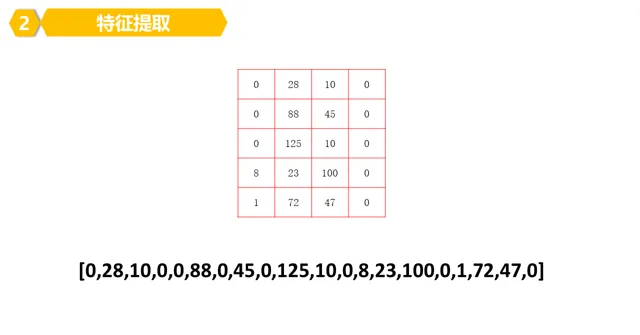
5。所以,我们可以看看数字8的特征,其实就是一堆数字(数组)构成的。
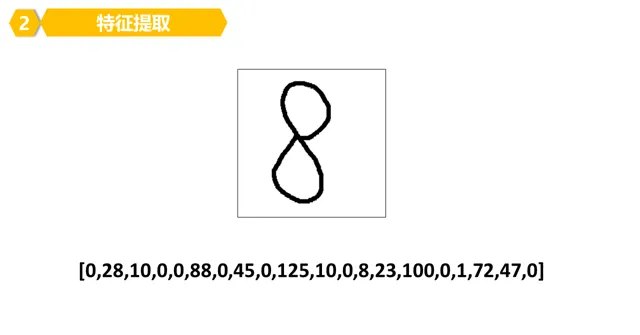
6。照着葫芦画瓢,每个数字的特征其实都是一堆数字构成的。
这个数字类似于我们的身份证号码,一般来说,是独一无二的。

7。那识别是怎么回事呢?
就是比较要识别的数字特征和步骤6中的哪个数字的特征最接近就好了。
这里为了方便,假设要识别数字「8」,然后看看怎么从一堆(为了方便只有两个)数字里面选出来他到底应该是几?
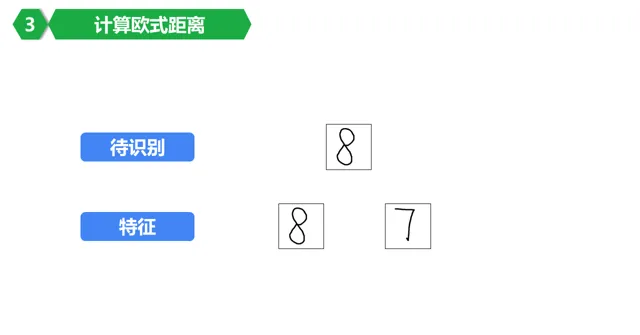
8。当然,为了方便,特征简化了,我们假设每个数字只有4个特征值了。
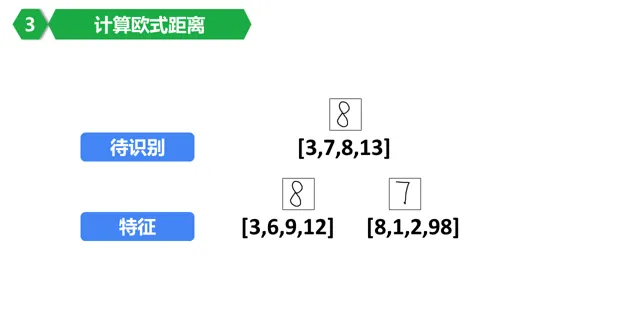
9。这里要用到一个欧氏距离的概念。
简单点说,就是有一个罪犯,经过警察叔叔的缜密侦查,发现他的身高 约 是175cm(通过脚印就可以判断出身高,大家自己百度一下)。
警察过来抓人了,两个已知嫌疑人,一个A身高176cm,另外一个B身高168厘米。
那我计算一下,取绝对值就好了:
那当然,罪犯就是身高176cm的A了。
当然,由于当前不仅仅有身高,还有体重,那就要综合计算身高和体重了。
为了更好地计算,就用到公式:
看起来很复杂,简单说就是把所有的差值取平方和后开根号。
这就是一种计算方法,不理解原理其实也没有关系,总之就是计算一下,知道怎么计算就行了。

10。看看罪犯和嫌疑人的相似程度。
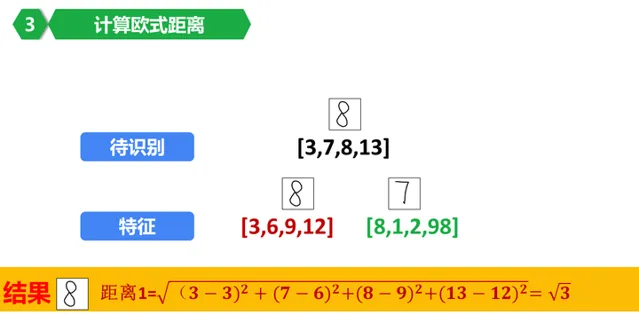
好了,计算一下要识别的这个图像(图中待识别右侧的8,这里我们假装不认识他)和数据库里面保存的数字8的欧式距离吧!

恩,计算就是把每个对应的特征值相减,取平方,计算和,开根号。
得到结果,当前结果是根号3.
11。再次计算罪犯和另外一个嫌疑人的相似程度。
好了,计算要识别的图像和数据库里面的数字7的特征值进行比较。
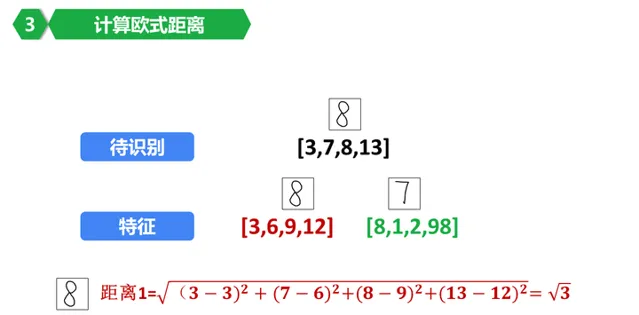
恩,绿色部分是我们的计算结果,根号7322.
12。识别
罪犯和嫌疑人的计算差异值,一个是根号3,另外一个是根号7322.
距离小的是识别结果。
这里,根号3是识别结果,所以,要识别的图像是数字8.
这就是识别过程了。
可以用图表示一下:
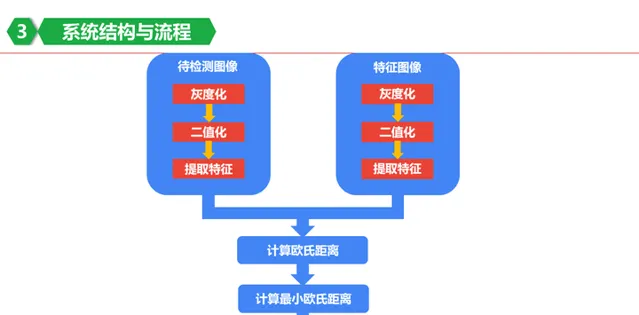
在提取特征前,图像可能是彩色的,就先把他处理为二值的,这样好方便计算其中黑色小块的个数。
写得比较匆忙,欢迎大家对细节提出改进意见。谢谢。
版权所有,转载请私信联系。
本文已经写入【OpenCV轻松入门】(电子工业出版社,2019)、【计算机视觉40例】(电子工业出版社,2022)。











