朋友们,我的书【PyTorch自动驾驶视觉感知算法实战】终于上架了,大家赶紧买买买,刷刷好评啥的:
TL;DR:
为了这本书:
做了一个七千多帧的连续帧数据集。可以用来训练单目深度模型。疫情期间采集的,几乎没有动态物体,想用来玩SLAM,NeRF也是可以的。标注了目标检测和语义分割两个任务的真值。
整理了一个代码库方便学习,实现了目标检测,语义分割,无监督单目深度学习,多任务学习,可微网络压缩,模型导出,模型量化,直至部署到LibTorch和TensorRT的C++代码。代码允许商用,除了TensorRT部分,没有GPU也能跑,我用的是1080Ti,但6GB显存应该也是够的。
各种环境配置都录了讲解视频,全是都是基于空白的Ubuntu系统从零配置的,通通录屏。
为了让人一眼秒懂,减少废话和篇幅,画了无数图 。。。
我入行遇到的痛点
刚入行无人驾驶的时候找书看,发现市面上居然没有一本像样的书,基本都是内容特别详细庞杂,过于基础,稍微高阶点的内容都没有涉及,感觉注水严重。所以搞得浓缩了一点。
学习的时候没有像样的数据集,自动驾驶数据集都是巨大无比,非常不方便。这个领域急需一个方便学习和把玩,随便一个笔记本都能跑得动,而且覆盖的任务多,不需要写多个接口的小规模数据库。尤其是还要是连续帧的,能玩SLAM,NeRF之类的。所以就按照这个需求做了一个。
工作了一段时间发现很多日常使用的工具,比如Linux,Docker,显卡驱动,cuda,Anaconda,CMake,VSCode之类的东西都要靠自己摸索,非常费时间。会用之后发现其实并没什么大不了的。所以把用的多的都写了一下。
另外就是很多边边角角但是很重要的知识没有人总结,比如batch size和learning rate的关系啦,L1正则化和L2正则化的区别啦,多任务损失平衡之类的。反正能想到的边边角角都写了。
最后一个很重要的方面就是模型部署,疫情期间工作的时候接过某德国大厂项目,居然就是把一个模型压缩和部署到某小众硬件上,弄完之后得知这个项目的价格我惊呆了,呵,原来我这么值钱啊。。。后来从其他同行的经历中也多多少少听说了,光是部署模型居然就是一个非常大的市场,还特么有创业公司。。。真的太离谱了朋友们,这个东西实在很简单啊。所以专门把模型压缩,模型量化到C++部署这一条龙都写了一下,其实代码直接拿去商用估计比很多公司的都好了。。。
总之,我在这本书里把这些痛点都解决了。平时我甚至还需要经常查自己的书,别说还挺方便的23333
内容
下面就分章节介绍一下:
- 卷积神经网络的理论基础。 其实很多书一本书就相当于这一章。。。把神经网络的基础知识全部介绍了一遍,结合公式和图片高度浓缩的过一遍。
- 深度学习开发环境及常用工具库。 顾名思义,就是Anaconda,Nvidia驱动,cuda,PyTorch之类的东西。像OpenCV和PyTorch的一些库函数,直接一张cheatsheet表格解决问题,没废话。
- 神经网络的特征编码器——主干网络。 除了主干网络的结构,还讲了对比学习无监督预训练,如何魔改TorchVision模型之类的事情。
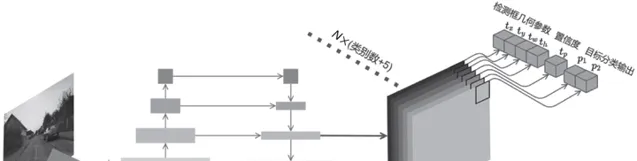
- 目标检测。 两阶段,一阶段,基于Anchor的,Anchor-Free的,几个有代表性的都讲了讲。
- 语义分割与实例分割。 语义分割还专门讲了几种常用的信息融合方法,实例分割介绍了半监督实例分割模型BoxInst。最后还花了一小节介绍了MMDet的框架构成和用法,没办法,用的多,痛点要解决。
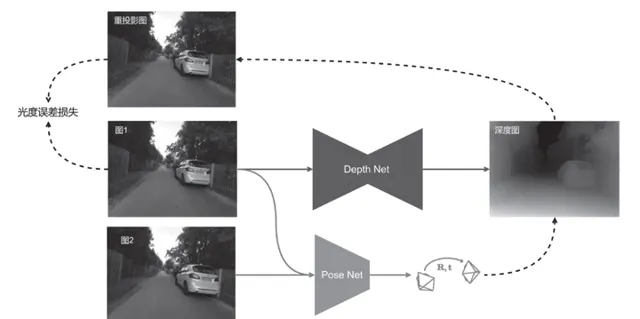
- 无监督单目深度模型。 很多学深度学习的同学可能对三维视觉不太了解,但搞无人驾驶,三维视觉还是要知道的。这一章等于是通过无监督单目深度模型,即学习了这个任务,又顺便学了三维视觉。有代码,直接用我提供的数据集就能训练出来。
- 多任务和网络压缩。 多任务主要讲了多任务学习中损失平衡的重要性。网络压缩我还自己实现了一个可微网络压缩的方法,从NAS那边抄过来的,效果居然非常好,也不知道有相关论文发表没有,谁如果要魔改啊发论文啊啥的别忘了cite我啊!主要是让大家认识到网络压缩的威力。
- 导出和部署神经网络模型。 这一章都是C++的东西,先是教了一下Docker,CMake,给VSCode配置环境,配置LibTorch和TensorRT啥的。部署的代码都有实现,Docker也提供了,照理照着一步步做不会出任何问题。LibTorch的CPU版本在任何设备都能跑,TensorRT代码要GPU。
数据集
长这样,随便看看,代码里名叫慕尼黑数据集,就在家附近经常散步的社区骑着自行车用从前公司离职的时候同事们送的GoPro录的:
 慕尼黑数据集
https://www.zhihu.com/video/1731914250044592129
慕尼黑数据集
https://www.zhihu.com/video/1731914250044592129
2D检测真值是用CenterNet2标注的,基本很精确了。语义分割是用MaskFormer标注后手动微调获得的,这个没办法完美,现在可能有更厉害的网络了,哪位有兴趣的可以帮我重新标一版。
图多
其实写书花的时间远远不如画图多,从视觉上说,我觉得我画的图还是比较好看的,可惜不是全彩。。。
遗憾
所有深度学习的书籍肯定都有相同的遗憾:过时。写的时候我就预料到,书里的模型肯定会过时。所以尽量选择了有代表性的,经典的模型。即便过时了,和sota的做法也不会有本质区别。同时大部分的篇幅都是和工具和基础理论相关的内容,具体模型占的篇幅反而少,主打一个授之以渔的意思。
还有一个遗憾是BEV相关的内容没有。不过也不算遗憾,因为报提纲的时候BEV还处于婴儿期。。。即便是现在,也不太好写,变化太快了,谁也不知道BEV的最终形态是怎么样的。不过最后为了弥补这个遗憾,录了个BEV感知的视频。
错误应该也是不少的,大家都知道,我喜欢大放厥词。。。知乎上可以改,这写书可不行。。。所以尽量都找到论文佐证,不乱说话,但最终肯定还是会有错误的。大家看到错误了可以私信我,到时候出第二版可以改。
总之,买就完事了!










