「大清早我还没睡醒,无人车就把我送到了公司,然后它自己去跑滴滴了」——啊,一切浑然天成,我们都过上了告别996的幸福生活,关键是无人车还能帮我搞钱(手动狗头)~

说实话,自动驾驶的蓝图很美好,但自动驾驶不是某类单点突破的技术,要实现真正意义上的自动驾驶,那可不是一般的难——难就难在它的不确定性和复杂度。
自动驾驶从L1到L5,有个简单粗暴的说法——L1:不用脚,L2:不用手,L3:不用眼,L4:不用脑;L5:不用人。每一个级别的提升,背后都是一大堆的黑科技,不过,要说到自动驾驶的最黑的黑科技,得从它的核心技术说起——
一、自动驾驶中的硬核科技:感知和规划
自动驾驶作为一个交叉学科领域,和人工智能技术紧密相联,你想在自动驾驶上「快乐地吃着火锅」,那就需要你的车能在逻辑、感知、融合、预测、规控方面形成一个完整的行为闭环。

同时,由于自动驾驶需要确保100%的安全性,又无形中推高了传统汽车的固有标准,比如自动驾驶中的「感知」和「规划」,就是两个有着非常多「黑科技」的核心技术模块:
1.智能感知:
自动驾驶能成为「智能的车」,靠的就是传感器这一双双眼睛。
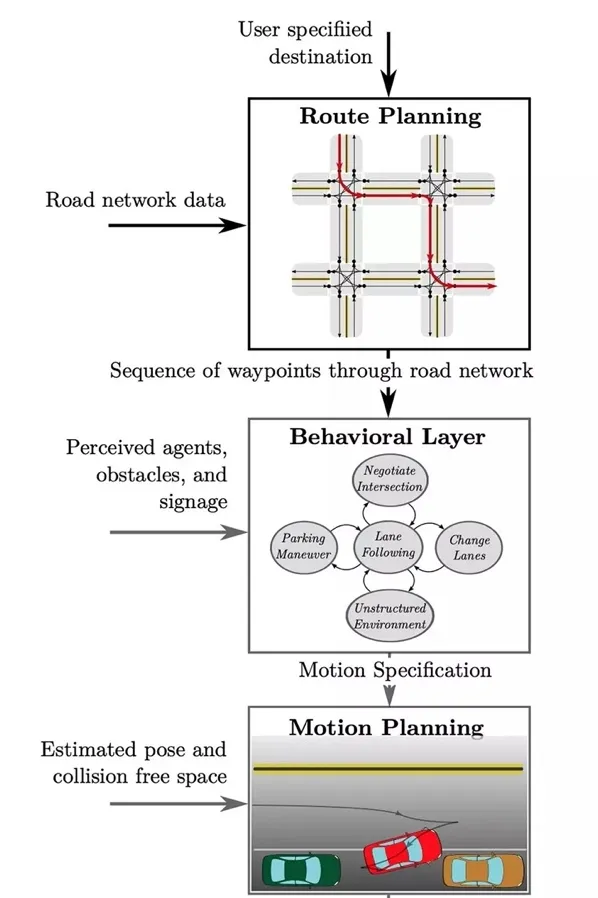
自动驾驶汽车的感知分为环境感知和状态感知,既要看清楚周围有什么——这儿是车道,红灯还是绿灯,右边突然来了辆车,还要对自己的状态心里有数——我在哪里,车速多快。传感器「眼睛」感受外部环境,采集到足够的信息,再去上报给「大脑」。这是实现自动驾驶最关键的一步,是最重要的环节。
通过「单车智能」,也就是依靠车载传感器可以做到对道路的「平视」,获取自动驾驶汽车行驶过程中的车速、轮速、档位等信息,探测到汽车周围的障碍物信息,比如车辆、行人以及路肩的情况,这就有了」智能的车「。
然而仅仅依靠「平视」所搜集的有限信息,显然是不足以应对一些意料之外的道路情况,比如令无数老司机闻风丧胆的「鬼探头」,和前方大车带来的视野盲区,都会成为道路上的不稳定因素。

这个时候就需要依靠车路协同系统,做到对整个街区路况的「俯视」,这是」智慧的路「。

举个例子,自动驾驶汽车之所以能够超丝滑地完成自动泊车,或是在环岛中完成一些列的动作,是因为无人车在研发阶段,对道路进行过N多次的测试,生成了毫厘不差的高精地图,再加以车路协同系统准确定位地形、物体和道路轮廓,才能让自动驾驶汽车做到许多驾考人做不到的完美动作。
2. 智能决策
自动驾驶汽车采集到的上文说的这些数据之后,需要经过它的「大脑」——计算单元,才能转化为控制信号,实现智能行驶。简单来说,计算单元就是「下任务」的——保持车距、车道偏离预警、有障碍物、该转向了……大脑给出决策,交由下一环节执行。
说实话,在L2及以下的时代,这个「大脑」的存在感并不是很强,但是L3及以上,智能决策模块是衡量和评价自动驾驶能力的最核心指标之一。
比如在极其复杂的真实驾驶场景中,如何基于历史信息和传感器收集的实时数据的态势,进行判断和预警,比驾驶员快一步做出决策;如何做到对行车路径的整体和局部规划,并肩负着「副机长」的角色,根据实时预测做出动态决策和瞬时响应。
所以严格地说,今天自动驾驶的关键技术已经发展得相当不错了(已经不是这个行业的最大挑战),要说 自动驾驶面临的最主要的挑战,还是来自于自动驾驶研发的核心——在智能决策的过程中,无人车的「大脑」需要对数据进行快速的计算分析、处理,由此带来的算力、存储、网络以及工具链环境等方面的问题。
特别是随着视觉感知的技术突破,推动了其他传感器(比如激光雷达和毫米波雷达)的感知算法以及多传感器融合算法的进步,同时也加速了自动驾驶数据湖的形成,自动驾驶等级和算力需求也随着数据量的提高逐渐增加。
二、自动驾驶研发过程中的挑战——「四座大山」
如上文所说,数据以及基于数据的AI计算和AI算力,是决定自动驾驶量产能力的胜负手。自动驾驶所形成的海量数据池带来的计算能力、数据存储、网络带宽和工具链环境的挑战,成为压在自动驾驶研发过程中的「四座大山」。
众所周知,AI计算是一个软硬件高度绑定的应用,对于车路协同的自动驾驶汽车来说,车载网络传感器和高精度地图的紧密配合,加之V2X车用无线通信技术的加成,固然会极大拓展自动驾驶汽车的感知范围,让自动驾驶汽车站在「上帝视角「看路况,可以解决大部分的风险问题。
但是一个无可避免的问题就是边缘设备实时产生的大量数据的问题。众所周知,自动驾驶汽车上搭载的传感器和摄像头,大约每秒钟就可以收集1GB左右的路况信息,且如何解决数据泛化问题,也是自动驾驶业界一直在探索的课题。
事实上,不仅仅是自动驾驶,当前这一波AI商业化浪潮的主要技术推动力是深度学习,深度学习的最大优势就是基于多层神经网络的自学习特征,它可以对像是语音、图像和文本这些非结构化数据有一个非常好的处理效果,但是这也意味着我们需要提供更高的芯片计算能力。
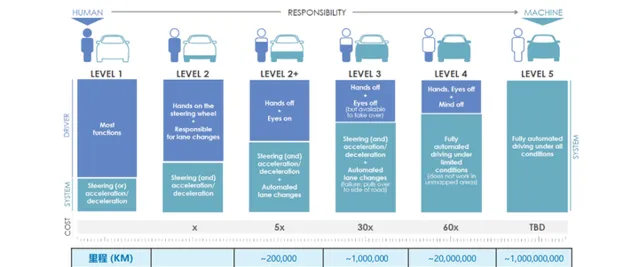
而对于自动驾驶而言,它本身就是一个天然的多模态,自动驾驶汽车搭载的多种传感器收集了不同类型的数据,突破了以往单一模态模型的数据形式。与此同时,对算力的挑战又上了一个台阶。
对于需要车路协同的自动驾驶汽车来说,如果不能在毫秒间完成计算并将计算结果迅速反馈,很容易造成交通事故。而传统的云计算模型,显然不适合对低延时和高可靠性具有较高要求的应用场景。这也是为什么像自动驾驶的车车、车路协同系统,往往都需要将计算推向网络边缘,利用边缘算力减少数据的传输延迟,从而保证数据的实时性和安全性。
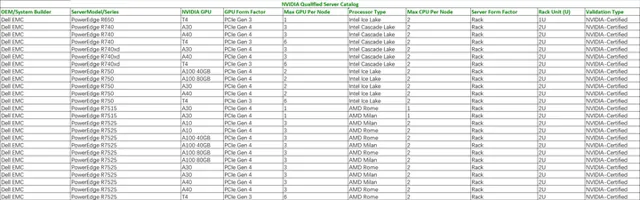
作为边缘计算的典型场景,自动驾驶研发对于算力的要求,实际上是对于企业级边缘服务器的要求。 可以看到目前NVIDIA认证的企业级边缘服务器一共有51款,在这其中仅戴尔一家就占据了31款。 (更多信息可点击: NVIDIA认证的企业级边缘服务器列表 )
随着AI算力需求的快速增长,AI算法模型越来越朝着大模型、多模态的方向发展,最初的单主机多进程和后来的CPU并行计算都显得有些力不从心,AI计算需要更大规模并行性的计算技术。
2011年,Andrew Ng将GPU引入到谷歌大脑,GPU开始成为强化学习、深度学习的主流计算技术,也因此许多专门支持高密集GPU工作负载的服务器就应运而生了,比如戴尔的PowerEdge R750xa 和XE8545。

(链接奉上,感兴趣可以进入官网了解):
在自动驾驶训练过程中,数据呈现指数级增长。小到十万级别,大到百万、千万甚至上亿级别,给元数据管理、存储效率和访问性能带来了巨大挑战,以及存储」IO墙「的出现。势必会导致更长的AI模型开发周期,使GPU处于饥饿状态,影响到数据采样的范围和精度,最终影响分析的准确性。
尤其是而对于数据处理模型的训练,需要频繁在存储设备中读写数据,因此,存储的分布式文件系统就极其关键,尤其是元数据处理的能力。
随着自动驾驶训练时间、网络数据量和应用程序暴涨等情况,自动驾驶对网络带宽的需求也开始水涨船高。原有存储网络没办法支撑大规模、并发式的访问,因此性能问题频繁发生。
除了上述几点,自动驾驶开发中还有一个最大的痛点——工具链的相互分割和数据孤岛现象。
在行业发展之初,可以说是各自为营的局面,传统的工具链公司大都会聚焦于某一个环节,做到垂类发展。然而对于实际生产过程而言,工具链的使用并不是单一的,而是要打好配合。此时二者的弊端就开始显现了。
三、自动驾驶研发背后的技术支持
AI领域的不断突破,为自动驾驶发展提供了强有力的内生动力,但种种现实情况表明,自动驾驶若想达到L5以上级别,显然不能脱离强大的IT基础设施的支持,这就需要通信方案提供商、终端服务商等众多环节的共同参与,肩负起行业推动器的角色,发挥平台作用,将孤岛资源串联在一起。
比如在人工智能方面,戴尔科技构建了面向自动驾驶汽车的基础架构解决方案,这一方案基于采用了AMD EPYC处理器的PowerEdge服务器构建,通过更高的计算资源集成度、更多的PCIe链路以及内存通道,能够显著提高数据密集型工作负载的计算能力,满足人工智能训练苛刻的算力需求。
同时,针对AI GPU分布式训练,从IT系统工程角度,结合计算、网络、存储硬件优化及框架软件层面优化,从端到端为用户提供整体的AI GPU集群架构设计与分布式训练最佳实践。
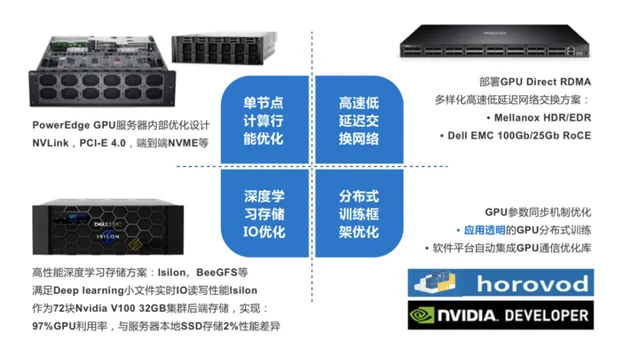
而在车路协同的落地方面,为了减少数据在「路上」的时间,给自动驾驶决策带来影响,戴尔科技针对数据在跨边缘、核心、云之间的传输提供极高的I/O性能。
所谓「软件决定自动驾驶的下限,而硬件则决定了自动驾驶的上限」。如果说在自动驾驶研发中真的有哪些「黑科技」,那应该就是非AI基础设施的支持莫属了,它的发展程度,决定了我们是否能真正实现「出行的乐趣」。
一步一步来吧。











