#机器人编程实战
#人工智能图像分割
#自动驾驶机器人DIY
我所在的小区的水站比较远,每次饮用完桶装水后,都得扛着约19升的水往回跑,最近我甚至用儿童乘用车来解决这个费力的事情。但这也不是长久之计,近几天我又萌生了DIY一辆自动驾驶机器人,能识别道路,能进出楼电梯。尽管这看起来很遥远,但我仍然决定行动,当我想象着机器人拉水并进楼的场景,我激动的竟然笑了起来。
设计方案
区的户外场景假设如图所示:

需要解决和构成挑战的问题有:
从单元门出来后的上下坡问题,既刹得住车又有足够的动力上去;
能在小区道路行驶避免撞到石砖和两边停的汽车;
经过1公里的行驶最后安全到达水站;
假设第一个问题先暂时搁置,先解决路上行驶和避障问题。
这里选择考虑图像视觉中的道路识别来解决在正确上的道路上行驶的问题。如果小区没有轿车避障可能也不需要考虑,但现实中道路是有轿车存在的,可以加雷达等测距传感器增加避障功能,或许也可以通过增加机器人和识别出来的道路边界之间的距离以避免碰撞,第二种方案的要求就是对道路识别的准确性有很高的要求了。
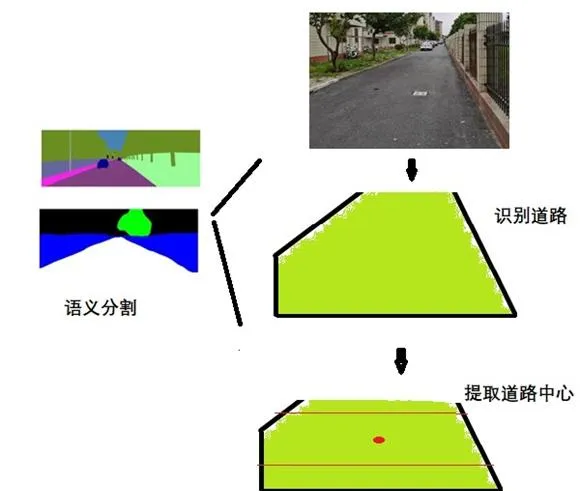
最后使用语义分割将从摄像头读取的图片中对道路识别,去掉干扰的背景。然后提取识别道路的中心,机器人要不断的调整姿态以便使镜头中心和道路中心在一条线上,这样可以最大程度的避免碰撞并安全行驶。
道路的行驶需要标记数据,这属于有监督学习的一种,所以接下来的工作就是收集特定的道路数据并标记了。
准备硬件
我们的硬件机器人需要足够大的负载和动力,这里选择之前DIY好的童车改装机器人,使用4轮共计120W功率的电机驱动。

收集数据和标注数据
由于在特殊的场景下完成功能,仿真在此类情况下应该不考虑,最终还是需要运行机器人实体采集图片数据。为了达到预期的实时性,摄像头采集的图片大小为640x480,这里裁剪成512x256。
编写collect_image.py完成摄像头采集视频。
import cv2
#是否保存为AVI视频
if args.savevideo:
out = cv2.VideoWriter("road" + ".avi", cv2.VideoWriter_fourcc('M','J','P','G'),10,(512,256))
#开始捕获摄像头视频流
cap = cv2.VideoCapture('/dev/video0')
print("camera connected!")
while True:
client.loop()#1s钟的阻塞
#img = get_video()
ret, img = cap.read()
if not ret:
break
#重新裁剪大小
img = cv2.resize(img,(512,256))
if _switch == 0:#如果为0 直接重头开始
continue
#cv2.imshow("IN", img)
#是否写入保存的文件
if args.savevideo:
out.write(img)
#每1秒钟采集一次
cv2.imwrite("img/%d.jpg"%framecount, img)
framecount += 1
程序中加入mqtt 实现远程启动采集功能。
from paho.mqtt import client as mqtt_client
#MQTT相关
broker = '127.0.0.1'
port = 1883
topic = "/camera/collect"
client_id ='python-mqtt-{}'.format(random.randint(0, 1000))
#接收开关
_switch =0
def on_connect(client, userdata, flags, rc):
print("Connected with result code "+str(rc))
client.subscribe("test")
def on_message(client, userdata, msg):
global _switch
#print(msg.topic+" "+msg.payload.decode("utf-8"))
_switch = ord(msg.payload.decode("utf-8"))-48
print("%d"%_switch)
def publish(client):
msg_count = 0
while True:
time.sleep(1)
msg = f"messages: {msg_count}"
result = client.publish(topic, msg)
# result: [0, 1]
status = result[0]
if status == 0:
print(f"Send `{msg}` to topic `{topic}`")
else:
print(f"Failed to send message to topic {topic}")
msg_count += 1
client.on_connect = on_connect
client.on_message = on_message
client.connect(broker, port, 60)
# 订阅主题
client.subscribe(topic)
完整的程序:
import os
import sys
import argparse
import cv2
import datetime
from paho.mqtt import client as mqtt_client
import random
#MQTT相关
broker = '127.0.0.1'
port = 1883
topic = "/camera/collect"
client_id ='python-mqtt-{}'.format(random.randint(0, 1000))
#接收开关
_switch =0
#参数相关
parser=argparse.ArgumentParser(description='collect data')
parser.add_argument('--savevideo',type=str,default='', help='save incoming video')
args = parser.parse_args()
print(args)
#定义mqtt的client
client = mqtt_client.Client(client_id)
def on_connect(client, userdata, flags, rc):
print("Connected with result code "+str(rc))
client.subscribe("test")
def on_message(client, userdata, msg):
global _switch
#print(msg.topic+" "+msg.payload.decode("utf-8"))
_switch = ord(msg.payload.decode("utf-8"))-48
print("%d"%_switch)
def publish(client):
msg_count = 0
while True:
time.sleep(1)
msg = f"messages: {msg_count}"
result = client.publish(topic, msg)
# result: [0, 1]
status = result[0]
if status == 0:
print(f"Send `{msg}` to topic `{topic}`")
else:
print(f"Failed to send message to topic {topic}")
msg_count += 1
client.on_connect = on_connect
client.on_message = on_message
client.connect(broker, port, 60)
# 订阅主题
client.subscribe(topic)
#client.loop_forever()
framecount = 0
#是否保存为AVI视频
if args.savevideo:
out = cv2.VideoWriter("road" + ".avi", cv2.VideoWriter_fourcc('M','J','P','G'),10,(512,256))
#开始捕获摄像头视频流
cap = cv2.VideoCapture('/dev/video0')
print("camera connected!")
while True:
client.loop()#1s钟的阻塞
#img = get_video()
ret, img = cap.read()
if not ret:
break
#重新裁剪大小
img = cv2.resize(img,(512,256))
if _switch == 0:#如果为0 直接重头开始
continue
#cv2.imshow("IN", img)
#是否写入保存的文件
if args.savevideo:
out.write(img)
#每1秒钟采集一次
cv2.imwrite("img/%d.jpg"%framecount, img)
framecount += 1
最后,简单的再编写一个html的web小程序用于实现手机的网页控制和查看。
手机的控制界面如图:

最终控制机器人采集路面道路情况,行驶1圈后,总共采集1200张图片。

通过筛选去除一些模糊的,再进行7:3的训练和验证分类。
如图

最终整理完毕,下一步就该标注了。
这里使用基于Ubuntu的labelme标注。如果系统中m没有安装可以使用指令安装
pip install pyqt5 labelme
在标记之前为了避免大量工作量,选择使用Pascal VOC 2012 的格式文件,这样省去时间提高效率。首先在文件路径下新建2个文件,文件分别是Colors.txt和 classes.txt.
Colors.txt隔行放的内容是 RGB颜色的数值。
0 0 0
0 255 0
而 classes.txt放的是识别的物体标签。这里只有两类分别是路和背景。
background
road
这样,路识别为绿色,背景识别为黑色。
接着在shell中通过指令打开labelme,
labelme --labels classes.txt
接在shell中打开 labelme ,选择左侧的【open Dir】将所有的文件导入,然后使用左侧【create polygons】创建多边形选项,标记道路,标记完成后弹出的窗口中选择‘road’完成。
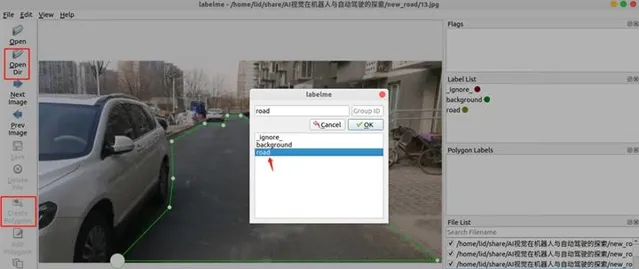
单击【ok】后并保存为相应的json文件,继续下一张。

然后需要通过脚本将json文件转换为png格式的掩码。
注意:pip install -U labelme 刷新labelme 最新版本为labelme-5.1.1
使用指令:
pytorch-segmentation$ python3 labelme2voc.py ../new_road../new_road_mask/--labels ../ classes.txt --noviz
最后按照第3章节的标注工具数据集中,无论Pascal VOC 2020 数据集还是注释自己的图像然后需要转换为 Pascal VOC 数据集格式,都会自动产生两个目录文件夹:
JPEGImages和Segmentation class。
lid@LAPTOP-85KPM8J9:/mnt/e/AI视觉在机器人与自动驾驶的探索/new_road_mask$ tree -L 1
.
├── JPEGImages
└── Segmentation class
2 directories, 0 files
JPEGImages应该包含图像,Segmentation class应该包含.png格式的注释/掩码。

接下来,我们会将这些数据拆分为训练和验证拆分。同样使用pytorch-segmentation文件夹下的split_custom.py脚本将数据拆分成ADE20K的数据集格式。
pytorch-segmentation$ python3 split_custom.py
--masks=../new_road_mask/Segmentation class/ --images=../new_road_mask/JPEGImages/ --output=../road_datas --keep-original
#开始执行
SPLIT: 39 train and 10 validation images!
Writing images to the training and validation folders...
…
Writing masks to the training and validation folders...
…
Done!
最后生成的文件目录为
/road_datas$ tree -L 3
.
├── annotations
│ ├── training
│ │ ├── 1.png
...
│ │ └── 97.png
│ └── validation
│ ├── 104.png
...
│ └── 446.png
└── images
├── training
│ ├── 1.jpg
...
│ └── 97.jpg
└── validation
├── 104.jpg
...
└── 446.jpg
Annotations文件夹下有trainning的掩码文件PNG,validation则是需要验证的文件。
Images下存放的是原始文件。该结构目录属于MIT的ADE20K数据集格式。
到这里,收集数据和标注基本完成了。
开发程序并训练模型
有了数据开始编写一个神经网络模型,使用现有的语义分割主干网络resnet系列,resnet系列有resnet18、resnet50 、resnet101,考虑到要将模型部署到嵌入式jetson nano中,根据其性能建议使用resnet18.
Pytorch支持分割模型segnet、pspnet、enet、deeplab v3 、u-net、fcn等。可以根据需要选择合适的使用。
事实上,PyTorch 提供了四种不同的语义分割模型。它们是 FCN-ResNet50、FCN -ResNet101、DeepLabV3- ResNet50 和 DeepLabV3- ResNet101。
英伟达提供了fcn-resnet18 、fcn-alexnet等图像分割的预训练模型。由于最终在jetson nano上运行可以将fcn-resnet18 预训练模型直接用来训练数据集。
第一个基于pytorch图像分割的包:
https:// github.com/yassouali/py torch-segmentation#config-file-format
pytorch 训练文件trainer.py 的核心部分如下:
#训练
def _train_epoch(self, epoch):
self.logger.info('\n')
#初始化
self.model.train()
if self.config['arch']['args']['freeze_bn']:
if isinstance(self.model, torch.nn.DataParallel): self.model.module.freeze_bn()
else: self.model.freeze_bn()
self.wrt_mode = 'train'
tic = time.time()
self._reset_metrics()
tbar = tqdm(self.train_loader, ncols=130)
for batch_idx, (data, target) in enumerate(tbar):
self.data_time.update(time.time() - tic)
#data, target = data.to(self.device), target.to(self.device)
self.lr_scheduler.step(epoch=epoch-1)
# 优化器清零
self.optimizer.zero_grad()
output = self.model(data)#获取输出
if self.config['arch']['type'][:3] == 'PSP':#区分PSPnet 架构不一样
assert output[0].size()[2:] == target.size()[1:]
assert output[0].size()[1] == self.num_ classes
loss = self.loss(output[0], target)#获取输出预目标值的损失值
loss += self.loss(output[1], target) * 0.4
output = output[0]
else:#其他net
assert output.size()[2:] == target.size()[1:]
assert output.size()[1] == self.num_ classes
loss = self.loss(output, target)#获取输出预目标值的损失值
if isinstance(self.loss, torch.nn.DataParallel):
loss = loss.mean()
loss.backward()#bp逆传播
self.optimizer.step()#优化器步进迭代
self.total_loss.update(loss.item())
该工程使用config.json完成配置。无论我们提供什么图像作为输入,我们都必须使用mean = [0.485, 0.456, 0.406] 和 对 std = [0.229, 0.224, 0.225]。如果你是一名普通的深度学习从业者,那么你一定知道这一点。每当我们使用预训练模型进行评估时,我们都必须使用训练过的数据集的均值和标准差。
Config.json文件如下:
{
"name": "PSPNet",
"n_gpu": 1,
"use_synch_bn": false,
"arch": {
"type": "PSPNet",
"args": {
"backbone": "resnet18",
"freeze_bn": false,
"freeze_backbone": false
}
},
"train_loader": {
"type": "ADE20K",
"args":{
"data_dir": "../road_datas",
"batch_size": 8,
"augment": false,
"shuffle": false,
"scale": false,
"flip": false,
"rotate": false,
"blur": false,
"split": "training",
"num_workers": 1
}
},
"val_loader": {
...
Split要和实际文件一致,
和ADE20k解析文件要一致。
class ADE20KDataset(BaseDataSet):
"""
ADE20K dataset
http://groups.csail.mit.edu/vision/datasets/ADE20K/
"""
def __init__(self, **kwargs):
self.num_ classes = 2
self.palette = palette.ADE20K_palette
super(ADE20KDataset, self).__init__(**kwargs)
def _set_files(self):
if self.split in ["training", "validation"]:
self.image_dir = os.path.join(self.root, 'images', self.split)
print(self.image_dir)
self.label_dir = os.path.join(self.root, 'annotations', self.split)
print(self.label_dir)
self.files = [os.path.basename(path).split('.')[0] for path in glob(self.image_dir + '/*.jpg')]
else: raise ValueError(f"Invalid split name {self.split}")
def _load_data(self, index):
image_id = self.files[index]
image_path = os.path.join(self.image_dir, image_id + '.jpg')
label_path = os.path.join(self.label_dir, image_id + '.png')
image= np.asarray(Image.open(image_path).convert('RGB'), dtype=np.float32)
label = np.asarray(Image.open(label_path), dtype=np.int32) #- 1 # from -1 to 149
return image, label, image_id
使用指令训练
python train.py --config config.json
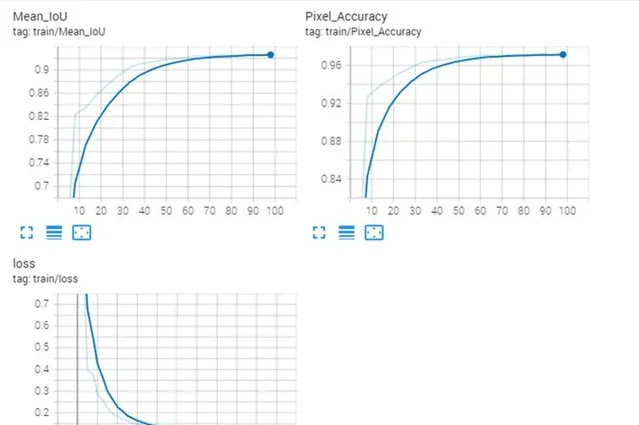
经过一段时间完成训练,并保存pth模型文件。
## Info for epoch 20 ##
val_loss : 0.08958
Pixel_Accuracy : 0.96
Mean_IoU : 0.9169999957084656
class_IoU : {0: 0.894, 1: 0.939}
Saving a checkpoint: saved/PSPNet\02-23_16-48\checkpoint-epocp0.pth ...
Saving current best: best_model.pth
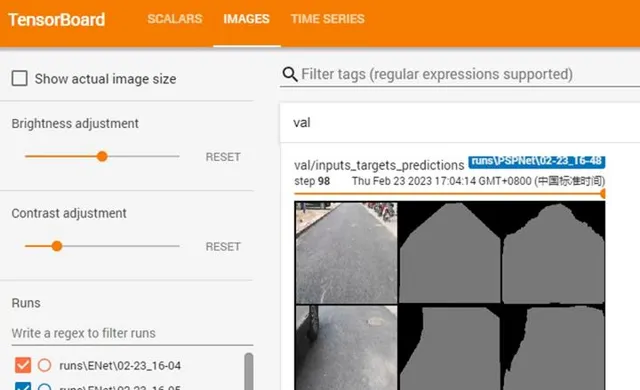
使用tensorboard 可视化训练结果并分析总结
tensorboard --logdir saved
浏览器输入
http://localhost:6006/
测试和验证
通过比较训练几种模型现总结表现如下
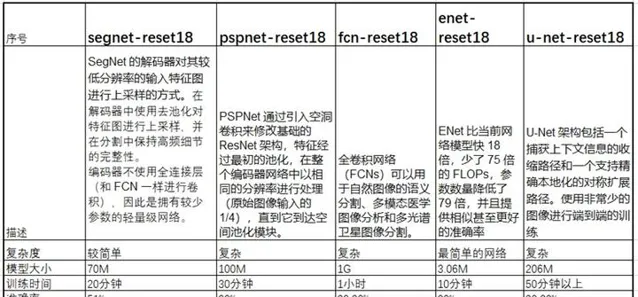
该表总结了训练的一些结果,fcn-resnet18的模型文件将近1G,有些不可思议。英伟达优化后的仅有40M。
部分训练的效果如下图:

原图

ENET结果

PSPNET结果

UNET结果
通过结果来看,PSPnet是相对较好的,UNET存在斑点,ENENT边界模糊。另外在训练机推理时间秒级以上,达不到实时性。
训练机的环境如下:
(PYTORCH) C:\Users\by>
(PYTORCH) C:\Users\by>pip list
Package Version Location
----------------------- ------------------- ------------------
absl-py 0.13.0
antlr4-python3-runtime 4.8
appdirs 1.4.4
black 21.4b2
cachetools 4.2.2
certifi 2021.5.30
cffi 1.15.1
charset-normalizer 2.0.4
click 8.0.1
cloudpickle 1.6.0
colorama 0.4.4
cycler 0.10.0
Cython 0.29.24
future 0.18.2
fvcore 0.1.5.post20210730
google-auth 1.34.0
google-auth-oauthlib 0.4.5
graphviz 0.20.1
grpcio 1.39.0
hiddenlayer 0.3
hydra-core 1.1.0
idna 3.2
imageio 2.25.1
importlib-metadata 4.6.3
importlib-resources 5.2.2
iopath 0.1.9
joblib 1.2.0
kiwisolver 1.3.1
Markdown 3.3.4
matplotlib 3.4.2
mkl-fft 1.3.0
mkl-random 1.2.2
mkl-service 2.4.0
mypy-extensions 0.4.3
networkx 2.6.3
numpy 1.20.3
oauthlib 3.1.1
olefile 0.46
omegaconf 2.1.0
opencv-python 4.5.3.56
packaging 23.0
pathspec 0.9.0
Pillow 9.4.0
pip 21.1.3
portalocker 2.3.0
protobuf 3.17.3
pyasn1 0.4.8
pyasn1-modules 0.2.8
pycocotools 2.0.2
pycparser 2.21
pydot 1.4.2
pygame 2.1.2
pymunk 6.4.0
pyparsing 2.4.7
python-dateutil 2.8.2
PyWavelets 1.3.0
pywin32 301
PyYAML 5.4.1
regex 2021.7.6
requests 2.26.0
requests-oauthlib 1.3.0
rsa 4.7.2
scikit-image 0.19.3
scikit-learn 1.0.2
scipy 1.7.3
setuptools 52.0.0.post20210125
six 1.16.0
sklearn 0.0
tabulate 0.8.9
tensorboard 2.5.0
tensorboard-data-server 0.6.1
tensorboard-plugin-wit 1.8.0
termcolor 1.1.0
threadpoolctl 3.1.0
tifffile 2021.11.2
toml 0.10.2
torch 1.8.1
torchaudio 0.8.1
torchvision 0.9.1
torchviz 0.0.2
tqdm 4.62.0
typed-ast 1.4.3
typing-extensions 3.10.0.0
urllib3 1.26.6
Werkzeug 2.0.1
wheel 0.36.2
wincertstore 0.2
yacs 0.1.8
zipp 3.5.0
Jetson nano 机器人终端移植
通过上一节的工作,已经生产了多个模型文件,现在需要将这些模型文件放到机器人终端上。
这个过程称为模型部署。
虽然model_best.pth文件可以在jetson中使用pytorch运行。但这应该不是最佳的方式,通常在嵌入式中,c/c++ 的程序是比较符合实时运行的。jetson-inference 库在后台运行 TensorRT,利用它使模型 与TensorRT 兼容,可以将其转换为ONNX格式。
ONNX 是微软与 Facebook 共同开发的一种开放格式,允许开发人员轻松地在不同框架之间移动他们的机器学习模型。
接下来将尝试pytorch 和onnx、及opencv dnn接口探索他们的推理时间。
Jetson-inference提供fcn-resnet18的预训练模型,所以从官网下载该模型和相关的训练库。
使用指令
python train.py ../road_datas --dataset=custom
生成best_model.pth
该路径下使用指令转换成onnx.
python onnx_export.py
使用segnet.py 推理使用
lid@lid-desktop:~/jetson-inference/python/examples$ ./segnet.py --network=fcn-resnet18-cityscapes --visualize=mask "img/*.jpg" img/test/%i.jpg
结果符合预期,道路显示为绿色

cuda速度为38ms.
[TRT] ------------------------------------------------
[TRT] Timing Report /usr/local/bin/networks/FCN-ResNet18-Cityscapes-512x256/fcn_resnet18.onnx
[TRT] ------------------------------------------------
[TRT] Pre-Process CPU 0.06755ms CUDA 1.45417ms
[TRT] Network CPU 62.30220ms CUDA 60.65453ms
[TRT] Post-Process CPU 0.07073ms CUDA 0.07016ms
[TRT] Visualize CPU 0.07052ms CUDA 7.91490ms
[TRT] Total CPU 62.51100ms CUDA 70.09375ms
[TRT] ------------------------------------------------
[image] loaded 'img/217.jpg' (512x256, 3 channels)
[image] saved 'img/test/5.jpg' (512x256, 3 channels)
[TRT] ------------------------------------------------
[TRT] Timing Report /usr/local/bin/networks/FCN-ResNet18-Cityscapes-512x256/fcn_resnet18.onnx
[TRT] ------------------------------------------------
[TRT] Pre-Process CPU 0.06828ms CUDA 1.18714ms
[TRT] Network CPU 32.22916ms CUDA 30.79021ms
[TRT] Post-Process CPU 0.29073ms CUDA 0.28557ms
[TRT] Visualize CPU 0.75038ms CUDA 6.22443ms
[TRT] Total CPU 33.33856ms CUDA 38.48734ms
[TRT] ------------------------------------------------
下一步,实车验证中......
【轮式自主移动机器人编程实战】图书作者,专注人工智能与机器人的基础应用









