如果目的是为了快速发论文,那么RL好;如果是为了好找工作,那么SLAM好。
从工业角度,RL距离落地还有很远的距离,或者说基本在实际系统上没用。如果看未来五年的「钱」景,果断SLAM。SLAM虽然成熟,但是还是有很多点可以挖掘,比如里程计的精度提升、多传感器融合机制、更有效的闭环检测、长航城的地图拼接融合等。这些问题在学术上没有完美的解决方案,但是在工程上可以创造很大的商业价值。从学术角度,两者的意义一样大。这篇论述,我会从我在CMU的实际经历带大家感受一下SLAM和RL各自的魅力,不一定会帮各位决定以后要研究的方向,但可能在一定程度上回答大家的部分疑惑。
前言
此份总结可能会有点长,分别涵盖我们过去5年在卡内基梅隆大学从事过的一些前沿工作,也包含在SLAM和RL领域的几篇IEEE T-RO,IJRR和若干IEEE RAL工作,我会慢慢更新。2023年6月起,我开始入职香港城市大学,长期从事SLAM,RL,Multi-agent工作。MetaSLAM是我们成立的一个非盈利组织,致力于提供最前沿的机器人相关(SLAM,RL,Multi-agent等)研究工作,我们的核心成果也会在里面有所展示。
官网:MetaSLAM
Github:https:// github.com/MetaSLAM
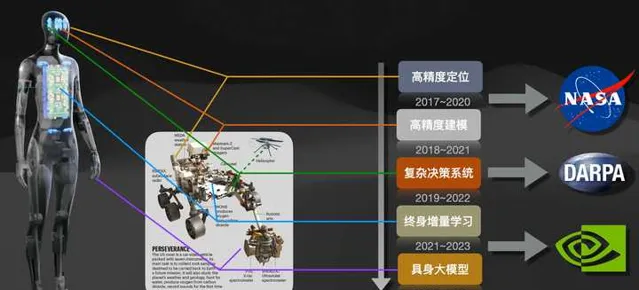
如上图所示,是我们在过去5年多所从事的工作,时间跨度从2017年9月到2023年5月,涵盖了SLAM、Planning、Lifelong Learning和Embodied AI的相关研究。长期以来我们一直在寻找RL和SLAM最融洽的结合点,随着2023年大模型ChatGPT的火爆和Tesla 人形机器人的发展,这个思路似乎也在变得越来越清晰。关于机器人与大模型之间的意义,请参考我最近更新的下面文章。
在本篇文章中,我们会先从SLAM和RL两个领域分别出发探讨其在机器人领域的价值。需要指出的是,因为篇幅有限,本篇所涉及的SLAM和RL工作,仅从可以在实际机器人系统中实用的相关工作进行探讨。最后,我们也会进一步分析一把,如何把SLAM和RL跟大模型系统LLM紧密耦合起来。
1. SLAM&RL的内在关联
从本质上讲,SLAM和RL本来就应该是绑定在一起的。SLAM的初衷是帮助机器人实现定位导航,但是他的作用并不仅仅只是定位导航。我们当前在做SLAM的时候,只关心定位的效率、建图的精度等,但是这些只是SLAM的外部表现。SLAM的最大作用实际上是一个巨大的数据关联中心,他可以把所遇到的场景、事物、地点、时间等要素关联起来(虽然听起来没啥用),因此他本身是一个数据库。当我们在做重定位的时候,Loop Closure Detection会尝试克服环境的视角变化、光照天气变化而提取初相互管理的场景信息,这其实就是在触发SLAM的关联能力。在这种关联作用下,SLAM其实有办法把发生的「事物」和特定的「场景」、「时间」关联起来,也就构成了我们在强化学习里面经常提到的「记忆」。而在强化学习领域,我们可以很多学习任务的Model-based或者Model-free学习策略,但是我们却往往忽略「位置」信息。这一点跟动物或者人完全不同,我们不会在打游戏的时候考虑「一会做饭的时候应该如何控制刀具的角度」,或者工厂里加工零件的时候回调「4岁学舞蹈课的时候腿的步调顺序」。因为我们有一些特殊的功能区「Working Memory",而这些区域的最大特点就是-> (把发生的「事物」和特定的「场景」、「时间」关联起来)。 有意思的是,对于人或者动物,SLAM中所涉及的定位问题、记忆问题和我们的行为的优化都跟一个模块直接相关,那就是 Hippocampus。
严格意义的讲,现在我们常见到的只是SLAM的一个分支,metric-SLAM,这一类方法追求定位精度。但是SLAM还有另一个分支,那就是topological-SLAM->拓扑SLAM,这种方式在10年前的概率机器人时代比较火,后来随着metric-slam的普及被人淡忘了。之前跟着Howie Choset大哥混的时候,就是被他一篇20年前的工作吸引过去的,哈哈。拓扑SLAM追求对于地图的高层次抽取,追求地图信息的融合和hierarchy层次的表达,由于过于抽象,难以在工程中达到厘米级定位而被放弃,但是拓扑SLAM却是最早模仿人和动物的感知行为而建立的。下面我会从SLAM和RL两个角度分析当前的进展,和两者合并的必要性。
2. 我们先来讲一讲SLAM
关于当前SLAM的文章或者书籍一堆,我就不展开了,这里做简化处理。一般意义中的SLAM中包括什么模块主要为以下三个:
- 里程计 : 包括常见的视觉、激光、毫米波里程计,实现连续帧间的姿态估计。
- 闭环检测 :loop closure detection, 也叫place recognition,根据传感器信息在视角变化、环境变化情况下,重识别出历史轨迹。
- 后端优化 :图优化的各类算法,iSAM系列,Factor Graph结点合并剪枝等等。
当前SLAM技术在里程计和后端优化方面已经诞生了很多杰出的的成果,在 里程计 方面,视觉里程计中的ORB-SLAM系列,VINS-mono系列,激光里程计中的LOAM系列、Livox-LOAM系列、Catographer系列,都构建了相对比较完备的里程计系统。在 后端优化 方面,gtsam,ceres,g2o也基本把大部分的后端优化问题处理的比较妥当。但是,不管是基于视觉还是基于激光的SLAM系统,在现实中用的时候都无法实现large-scale和long-term下的定位导航,这是为什么呢?这里面的工程问题和理论问题背后又有什么耐人寻味的秘密呢?
( 2023年6月13 日更)
时隔约一年,让我们继续这个话题。让我们先继续完成对于SLAM的论述,我将会从一个亲历者视角,回答为什么SLAM技术依旧是非常重要的存在。如在前文中所提到的,SLAM技术的关键技术中,闭环检测是非常关键的一环,因为它能直接决定移动机器人在大尺度(Large-scale)和长航程(Long-term)环境下的鲁棒性。这一点尤其在无人驾驶领域,特种机器人领域,服务机器人领域等有着重要的作用。如果配以高性能的视觉/激光里程计,以及鲁棒的后端优化操作,SLAM可以发挥出巨大的潜力。下面我就从我自己相关的三个项目,带大家一起感受一下。
2.1 NASA火星登陆项目中的SLAM定位问题 (2019~2022年)
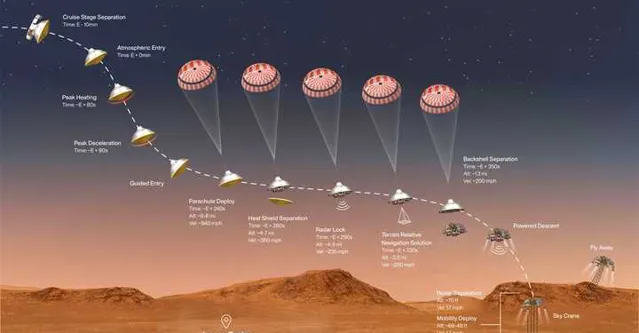
大概是在2019年时,我当时在CMU跟Ji Zhang大哥(LOAM & V-LOAM鼻祖)拉到一个NASA的项目,那就是设计一套辅助NASA火星车精确降落的方案。这件事的原因很简单,在火星上不比地球,因此一般飞行器只能粗略的落在一个指定的区域,但是精度就完全指望不上了,离谱的话有可能会偏出去几公里(毕竟安全降落就已经不容易了,哈哈)。但这样不好地方在于,机器人往往单个行动,而很难与其他前期的机器人协同工作。因此我们经常听到新闻,哪个火星车又陷在沙子里出不来了,或者翻车了在尝试自救。因此很多人都在想,如果给登陆机器人提供高性能抗造能力强的定位系统,那么后来的机器就可以精准的降落到指定的规划区,一方面可以辅助前期的机器人,另一方面也可以进行多机协作,甚至可以推进人造基地这种高端的设计了:)。

理想是美好的,但是现实是打脸的:
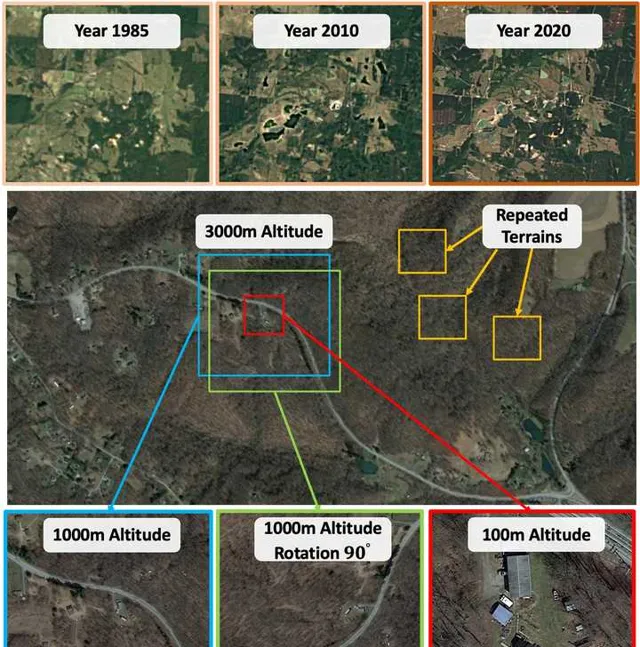
因此如何在这种情况下,实现稳定的定位能力(降落定位精度控制在20m内),是我们面临的核心问题。这个问题放在SLAM里面,其实也就是:「如何在 视角未知 、 外观变化 、 场景重复 的条件下,实现稳定的场景识别(或者闭环检测)。」 其复杂程度可以用下图表示,假设我们将要把机器人降落到图中红色的框区域:1)此图上面一栏描述的是一块区域在不同年代下的Google地图信息;2)第二栏显示的是这个区域包含多种重复的区域;3)而且如第三栏所示,即便对于相同的区域,在不同高度(Altitude)和视角下(Yaw,Pitch,Roll)其外观也会不同。
对于这个问题我们初期尝试了很多当时SOTA的Matching策略,例如SuperPoint以及Superpoint系列的衍生物HLoc,最终发现都不太理想,因为这类方法都只能在局部进一步提升图片识别的能力, 而且泛化能力极差,在实际中压根用不了 。因此我们经过为期一年的实验,提出来一套广泛适用于场景识别的方法,iSimLoc: Visual Global Localization for Previously Unseen Environments with Simulated Images[1]。那么这个工作里面的核心是什么呢,就是那个最不起眼的 场景识别 。

我们设计了一套跟视角、环境条件无关的场景特征信息,确保飞行器可以在不同视角、高度下精确识别同一个地方;同时我们又设计了一套Hierarchical的Coarse-to-fine的重定位机制,使得机器人永远不怕「找不到回家的路」。为了验证这个系统的有效性,我们花了一年的时间做实验,2019~2020年。终于分别在小型无人机和直升机上验证了系统的可靠性:
来,咱们直接上实战视频:
 https://www.zhihu.com/video/1652248911657144320
https://www.zhihu.com/video/1652248911657144320
这些性能指标刚好解决了NASA的需求,如果这个工作可以为以后人类登入出一份力,我们也就很开心啦。那么这个项目给我的直观感受是,SLAM很重要,场景识别确实很重要,哈哈 。后面这个工作也发在今年的IEEE TRO上面,机器人领域的朋友大概也都了解这个期刊干啥的,有兴趣的话可以看看原文。这份工作也是我们在MetaSLAM组织下的第一份大型工作,后续也会陆续开源。
[1] P. Yin, I. Cisneros, S. Zhao, J. Zhang, H. Choset and S. Scherer, "iSimLoc: Visual Global Localization for Previously Unseen Environments With Simulated Images," in IEEE Transactions on Robotics ( T-RO ) , vol. 39, no. 3, pp. 1893-1909, June 2023, doi: 10.1109/TRO.2023.3238201.
2.2 DARPA SubT Challenge中的多机SLAM和众包地图 (2019~2023年)

在2019年,DARPA的地下机器人挑战赛拉开帷幕。Darpa SubT Challenge(2019~2021) 要求在限定的时间内利用不同类型机器人最快速、最精确的识别定位出潜在的对象(书包、手机、人员、阀门等),得分高者优胜。 熟悉DARPA的同学可能还记得,这个机构一直致力于推动机器人事业的前沿发展。如2005年的Darpa Ground Challenge,2007年的Darpa Urben Challenge,这两项赛事开启了美国的无人驾驶热潮,然后这股热浪慢慢席卷全世界,到我们面熟悉的国内公司。Darpa Robotics Challenge (2012~2015)人形机器人比赛,这项赛事也是为期三年,虽然最优以惨淡收场,但是去开启了人形机器人、足式机器人等领域的研究先河。在此基础上诞生了美国的Boston Dynamics和苏黎世的Amymal Robotics等知名企业。SubT比赛的推进,也标志者Darpa开始锁定在地下极端环境或者其他GPS-denied环境(月球、火星)下的多机协作问题。
在这次比赛中,由于没有任何GPS或者其他第三方定位信息,因此机器人需要通过有限带块的Wifi建立彼此之间的协同定位。这对于这个研究热点,MIT,NASA,ETHZ,QUT,CMU(我们)等分别给出了非常出色的解决方案。但是在比赛中,大家基本还是在用一些偏工程的策略,比如:
- 机器人都要在同一点出发以提高彼此之间的识别精度;
- 随着地图复杂度提高,一旦机器人的相对定位误差增加,很难精确估计彼此之间的位置信息。
以上信息导致在实际应用的时候,就必须要求所有机器人必须同时在线。而在实际地下复杂环境或者其他极端环境中,这显然不可能实现。我记得那是在2020年夏天,一次午后在CMU跟Ji Zhang大哥交流的时候,我们想到是否有办法在不依赖任何第三方辅助的条件下,建立分布式的众包地图,其核心思想是:
A. 任何机器人可以在任何地点出发,一旦机器人之间的轨迹有重叠,此众包地图系统会自动解耦出相遇机器人之间的相对关系;B. 此众包地图系统支持所有机器人异步上线,因此地图融合的灵活性得到保障;
C. 多个机器人在不依赖任何第三方定位系统(GPS,UWB)的前提下,实现整套地图的全局建模,规模要大,10~120公里,因为规模太小对于当前的SLAM没有实际落地意义。
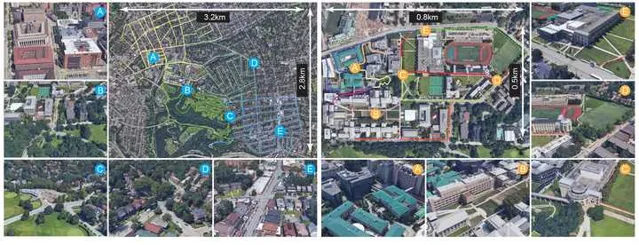
我们聊了一下午,结论是这事儿可行,干吧。因此在当时「疫情」的大背景下,我们采集了一套名为ALITA Dataset[2] (ALITA: A Large-scale Place Recognition Dataset for Long-term Autonomy)的数据集paper,覆盖了包括CMU校园内部和匹兹堡部分街区的120km数据,用于我们 验证场景识别 的能力和 众包地图的效果。 然后用了一年多的时间,搭建了一套可用于针对于园区、城市级别的众包地图系统, AutoMerge[2] (Automerge: A framework for map assembling and smoothing in city-scale environments), 他可以分布式的的完成地图的获取、上传,并可以在云端自动完成地图的拼接整合,而跟得到地图的先后顺序无关;于此同时由于其高效的匹配特性,使得AutoMerge可以同时支持10~20个以上Agent的联合建模。这一点对于后续多节协作的任务比较重要。
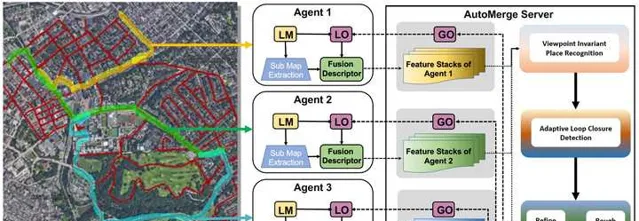
这一方法算是首次帮助多机器人系统在城市规模的大尺度环境下,不依赖任何外部的GPS等定位系统,实现多机器人之间的联合建模、定位。这份工作让我们意识到,真正鲁棒的大型SLAM系统确实需要大量的工程优化,需要长时间的反复实验(为期三年),但其中也蕴含着很多的科研潜力,而且对于现实生活中的很多问题可以提供完全新颖的思路。正如前面所提,对于地下和太空等没有其他参考定位信息的极端环境,AutoMerge可以辅助多机器人系统建立大范围的相对定位信息,方便多机器人之间复杂的任务调度等。
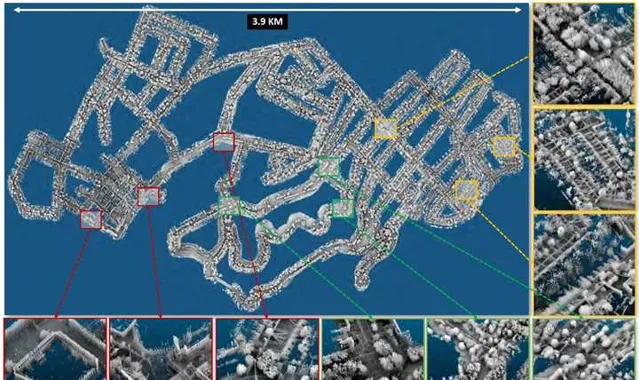
最后来两段视频给大家感受一下众包地图的视觉冲击感,以下视频是由AutoMerge为匹兹堡建立的众包地图效果,数据采用ALITA Dataset(只有VLP-16和IMU,无GPS),50相对独立的机器人各自进行数据采集,最终完成整体的众包地图。也正因为这套方法可以支持多个机器人进行联合建模,从而为后续的多机协作打开了一个新的窗口。
 https://www.zhihu.com/video/1652250181218295808
https://www.zhihu.com/video/1652250181218295808
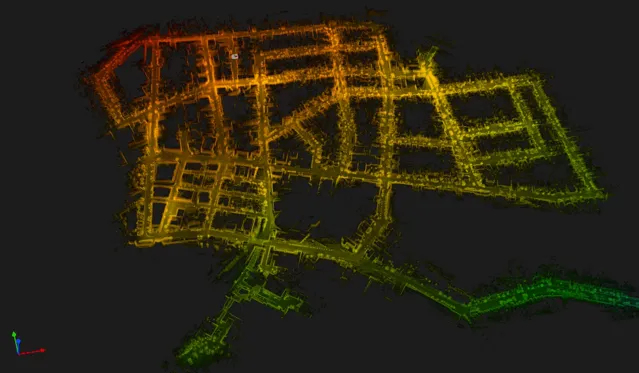 https://www.zhihu.com/video/1652242448024776704
https://www.zhihu.com/video/1652242448024776704
[2] P. Yin, S. Zhao, et al. "ALITA: A large-scale incremental dataset for long-term autonomy." International Journal of Robotics Research ( IJRR ) (2023), preprint arXiv:2205.10737.
[3] P. Yin, S. Zhao, H. Lai, R. Ge, R. Fu, I. Cisneros, J. Zhang, H. Choset and S. Scherer, "Automerge: A framework for map assembling and smoothing in city-scale environments," in IEEE Transactions on Robotics ( T-RO ) (2023) , arXiv preprint arXiv:2207.06965.
[4] S. Zhao, P. Yin, G. Yi, & S. Scherer. SphereVLAD++: Attention-Based and Signal-Enhanced Viewpoint Invariant Descriptor. IEEE Robotics and Automation Letters ( RAL ) (2022).
2.3 Lifelong 终身学习式的SLAM定位导航问题 (2021~2023年)
对于这个部分的工作,我会基于此前的这篇人工智能是不是走错了方向?的基础上进行整合。从2021年开始,我们在做机器人定位导航中所涉的数据量开始与日俱增。
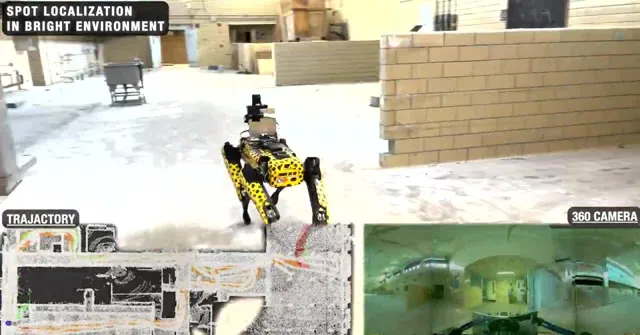 室内复杂环境中的360视觉定位
https://www.zhihu.com/video/1653377165294157824
室内复杂环境中的360视觉定位
https://www.zhihu.com/video/1653377165294157824
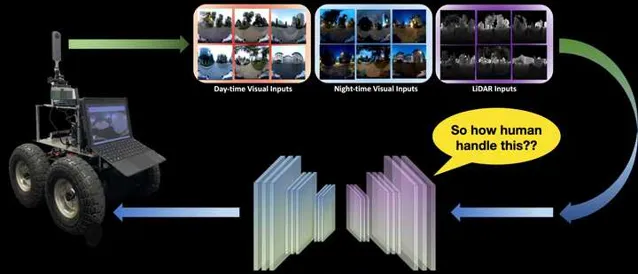
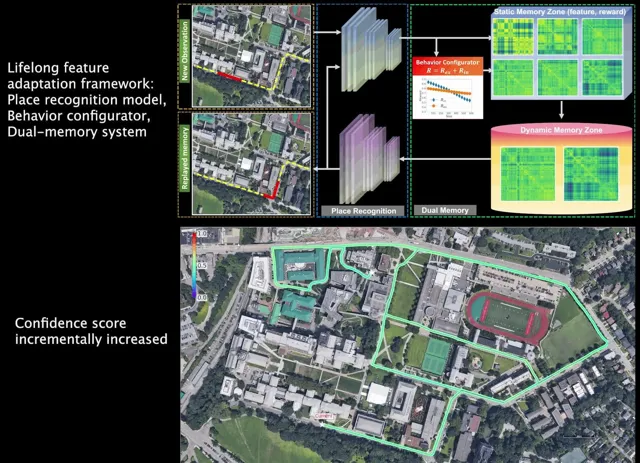
在以上视频中,当我们让狗子尝试在不同条件下进行定位导航任务时,狗子需要克服多种环境的干扰,比如视角变化、光照变化、动态障碍物变化等,如果采用一般的SLAM和场景识别方法进行重定位,那么我们一般会采集多种环境条件下的数据对「定位模型」进行Refine,以期望提高模型的泛化能力。然而。。。这不太可能啊。大千世界万万千,基本是以上视频中这个简单的场景,在不同的条件下也会有不同的模态。而对于人也好,动物也好,昆虫也罢,这些物种却可以相对轻松的平衡自己的日常生活中的定位能力。比如,你每天都要去学校、公司,你所穿过的街道在不同的动态障碍物环境下、光照条件下、季节条件下,都可以重新帮你识别出自己的位置。但是 定位 这个问题对于人类来说却不怎么占「CPU」,我们往往可以 一边打电话、聊天、看手机,一边去往目的地 ,因此人的这种能力就是「 智能 」的一种体现。但是反观现在的 机器人 - 人工智能 技术,我们往往需要高精度建模、高精度定位识别,这些内容就能占掉一大半CPU实用率,而且环境一旦变化,之前的先验信息大部分都会失效。因此我们开始意识到,想实现长久的定位导航且具备比较好的泛化能力和鲁棒性,就必须引入一套额外的机制, Lifelong Learning(终身学习) 。这一类方法在机器学习领域、脑科学领域研究的非常火热,而且目前的LLMs大模型系统系统也实现了基于Transformer和Long-short-term Memory的终身学习方法,取得了ChatGPT这样的大型成果。但是在现实生活中的机器人领域,Lifelong Learning似乎依旧停留在一些Toy Example上,或者纯仿真环境中。因此如下图中展示的真实机器人long-term定位导航中,实现切实可用的Lifelong终身学习,是我们在2021年面临的一个核心问题。
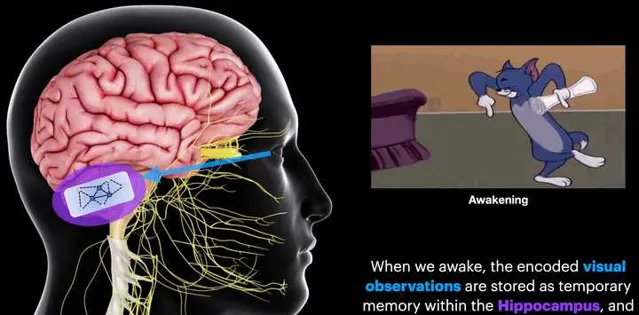
在本文最开始的地方,我们提到过:哺乳动物的大脑有一块区域叫做 Hippocampus (这个词后面出现的频率会越来越多),这个区域会把 定位信息 和 记忆信息 耦合起来。而Hippocampus有一个很独特的功能就是 Memory Consolidation(记忆整合)。 这一步骤其实非常关键,他可以帮助人从每天繁多的事情中萃取出最核心的Memory信息,用于优化人的行为。因此我们经常有以下这种感受,
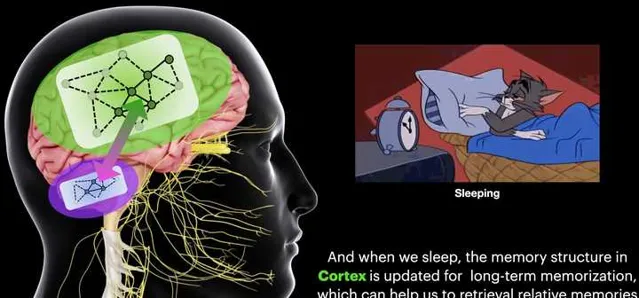
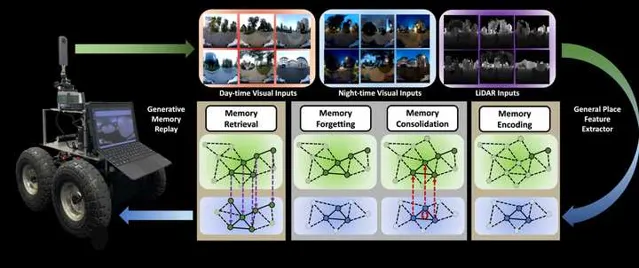
在这种「记忆反刍」的机制下,我们的记忆和学习行为可以得到持续提升(因此每天睡够8个小时至关重要, )。也是在这种机制的牵引之下,我们设计出了专门针对于机器人Long-term定位导航的BioSLAM: A Bio-inspired Lifelong Memory System for General Place Recognition[5]。这一方法在我们此前的iSimLoc和AutoMerge基础上,继续为SLAM中的定位问题赋予了Lifelong 学习的能力:
- 采用了一套固定的模型系统实现了机器人在多模态环境中的定位导航问题;
- 设计了双记忆块机制(Long-Short-term Memory),使得BioSLAM可以 实现类似于Hippocampus的Memory Consolidation能力;
- 提供了一套Reward机制,使得本系统可以据真实环境的数据模态变化,自行决定应该如何在记忆区筛选数据,应如何根据外部奖励强化不同模块的适应能力。
通过这套方法,我们实现了在真实复杂的城市环境、园区环境等,多模态输入的前提下的长航程定位导航任务。下面直接上视频结果:
- 初始状态下机器人的定位模型从未有在CMU的园区训练过,也就是一个仅仅做了初始化的模型;
- 随着BioSLAM自动更新机器人的Long-term Short-term记忆区,对于提高「学习」能力有价值的信息被不断筛选出来,同时我们也能看到保存新样本的Reward在不断降低;
- 随着时间的推移,机器人的定位能力(场景识别)也在不断提升(轨迹的颜色所示)。
 BioSLAM Performance
https://www.zhihu.com/video/1653401925335887872
BioSLAM Performance
https://www.zhihu.com/video/1653401925335887872
[5] P. Yin, A. Abuduweili, S. Zhao, etc. "BioSLAM: A Bio-inspired Lifelong Memory System for General Place Recognition." in IEEE Transactions on Robotics ( T-RO ) (2023), preprint arXiv:2208.14543 .
为了验证这套系统的可行性,我们在2021到2022年利用已有的数据和新采集的数据做了为期一年的实验,证明Lifelong Leanring确实可以在Long-term navigation中进一步提高 SLAM的鲁棒性和泛化能力。当然,聪明的朋友们可能已经注意到,其实我们在BioSLAM里面引入了很多类似于RL的机制,比如说Memory Replay,Reward机制(Intrinsic and Extrinsic)。在这个环节下,我们意识到,SLAM和RL之间明确的界限已经在慢慢消失了。。。关于SLAM的问题,我先写到这里,后面有其他有趣的工作我再更新到这个地方。
2.4 多模态机器人主动协作建模(2022~2024年)
( 2023年8月14日更 )
再开始RL之前,我再插一条我们在多机协作问题的考虑。回顾我们此前的工作,分别解决了大规模、长航程和终身学习的基本能力,但是我们发现:仅仅用单台机器人其实很难实现大规模环境的规划决策。而且在很多情况下,单一模态机器人的应用其实非常受限,就比如一下无人机、移动机器人的例子:
(1) 如下视频所示的无人机系统,可以实现在复杂室外环境的快速探索,这一能力使得机器人系统可以迅速在超大规模环境中进行全局自主无人建模,无需人为干预。但是无人机系统却无法进入复杂的室内环境、地下室环境等,其安全性也是我们在实际应用中需要考虑的问题。
 在CMU RI园区的无人机自主探索
https://www.zhihu.com/video/1674449167849013248
在CMU RI园区的无人机自主探索
https://www.zhihu.com/video/1674449167849013248
(2) 与之相对的,移动机器人系统却可以轻松进入复杂的室内外环境(当然这个工作也没有想象的轻松,Ji Zhang大哥和Chao Cao做了3年多才有了现在丝滑的效果),目前移动机器人已经可以实现在极端复杂的室内场景进行大规模的探索工作。但是移动机器人也有短板,一个是无法看到外部建筑物的高空环境信息,同时轮式机器人也不具备在非平坦区域运行的能力。
 移动机器人在CMU RI室内外探索
https://www.zhihu.com/video/1674450906878799872
移动机器人在CMU RI室内外探索
https://www.zhihu.com/video/1674450906878799872
因此我们可以看到,单一模态机器人虽然具备某一些方面的优势;但在真实环境中,针对大规模环境的探索+决策,单体机器人的能力就会收到诸多限制。其实这个原因也是此前Darpa Subt比赛中采用多模态机器人的原因。但是如果进行大规模的多机协作工作,机器人之间的协同定位又是一个绕不开的问题:因为 不同机器人之间的视角、光线、动态信息都会不同 ,因此此前我们并没有找到太多在大规模环境进行多机协作的有效算法。不过在2022年后,我们意识到这个问题是可以解决的了,那就是采用我们此前已经开发出来的AutoMerge系统辅助机器人进行超大规模地图协同定位,并在此基础上进一步巩固多机协作的能力。
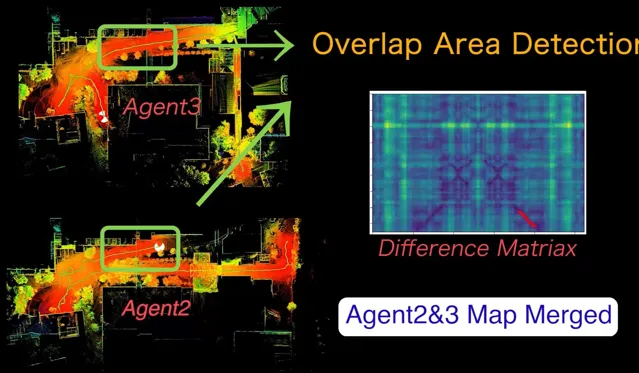 基于AutoMerge的多机协作系统
https://www.zhihu.com/video/1674453615619059712
基于AutoMerge的多机协作系统
https://www.zhihu.com/video/1674453615619059712
为了方便理解,我们可以定义任意单体机器人为「个体」,而多个「个体」构成的合集我们成为「集体」,而多机协作的目的就是「最大化集体利益」。因此在这种背景下,我们的方法具备如下优势:
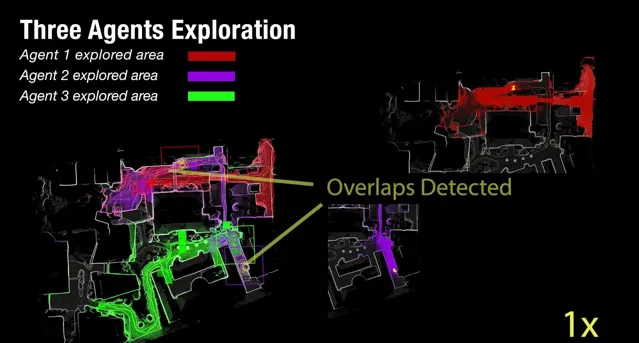 三个智能体在未知环境中的探索
https://www.zhihu.com/video/1674461743542693888
三个智能体在未知环境中的探索
https://www.zhihu.com/video/1674461743542693888
因此其实我们这个系统多少有点像虫族的决策机制,单个个体所具备的能力虽然有限,但是作为一个集体却可以完成很多了不起的事情,哈哈。我们聊到这里,其实大家就会发现,SLAM已经不再单单是SLAM了,它可以向主动SLAM的方向拓展,向多机协同的方向发展,甚至向更有趣的集体智能领域拓展,似乎SLAM跟RL的关系又进了一层。

3. 我们再来说一说RL
有空再写。。。
4. SLAM和RL在大模型时代下的结合体
有空再写。。。











