在全球,有關數據私密及安全的保護運動已經沸沸揚揚地開展了一段時間。早在2018年,號稱「史上最嚴」及「三十年來數據安全最大變動」的歐盟GDPR(【通用數據保護條例】)已經引發了全球廣泛關註,並推動了各國和地區對數據私密及安全的重視。
2021年6月10日,中華人民共和國第十三屆全國人民代表大會常務委員會第二十九次會議正式透過並公布【數據安全法】,並將於2021年9月1日施行。它將與已經頒布的【網絡安全法】及正在審議中的【個人資訊保護法】一起代表中國對數據私密及安全的重視,共同構建起中國數碼時代有關資訊的法律體系。
在這種背景下,數據私密和安全得到空前重視,且在未來將毫無疑問地趨於嚴格。醫療AI模型開發叠代必須的醫療數據獲取變得愈發困難。以聯邦學習為代表的私密計算為這一問題提供了全新的解題思路,並在最近兩年獲得了廣泛關註。兩年過去了,以聯邦學習為代表的私密計算如今有什麽進展呢?動脈網對此進行了梳理。
簡要回顧一下聯邦學習是什麽?
簡單來說,聯邦學習是一種加密的分布式機器學習框架,目標是在保證數據私密安全及合法合規的基礎上對AI模型進行訓練的手段。這一技術最早由谷歌提出,並在Google I/O 2019大會上首次展示了實際落地的套用場景。
谷歌當時展示的G-Board輸入法使用了這種新的模型訓練方式,將整個模型學習過程分發到使用者手機,在本地完成分配的模型訓練任務,隨後將訓練完成的數據上傳匯總幫助模型訓練。因為訓練過程在本地完成,且上傳數據只涉及模型訓練所需的必要數據,從而防止了數據泄露。
醫療AI模型的完善同樣需要大量數據的訓練。放射科醫生通常需要工作15年時間,平均每年經手至少15000個病例才算小有所成。這意味著人工智能需要對同等規模病例(22.5萬)的學習才能達到放射科專家水平。遺憾的是,目前最大的開放數據庫僅有10萬病例的規模,離滿足人工智能訓練的要求尚有一定距離。
事實上,各個醫療機構可能擁有包含數十萬條記錄和影像的檔案,但因為私密和法規的原因,這些數據完全是彼此孤立無法使用的。無論是人工智能企業,或是正在使用人工智能的醫療機構都只能依賴手頭僅有的數據來源。高質素訓練數據的嚴重匱乏,嚴重阻礙了醫療AI的更進一步。
此外,完全依賴開放數據庫訓練的模型,很有可能缺乏真正的臨床價值。2021年,劍橋大學對公開釋出的有關醫療AI的2212篇論文進行篩選,從中選出62篇可以達到研究人員設定的較高的入選標準的論文。然而,研究人員最終發現所有62篇實際上都沒有潛在的臨床套用價值。
數據集質素和規模嚴重不足是導致這一問題的重要原因;此外,僅僅采用來源於開放數據庫的公共數據集也是原因之一。隨著時間的推移,公共數據集不斷發展並融合新的數據,很可能導致最初的結果無法復現。
劍橋大學的研究人員提出了三個觀點:第一,公共數據集可能導致嚴重的偏差風險,謹慎使用。第二,為了使模型適用於不同的群體和獨立的外部數據集,訓練數據應該保持多樣性和適當的規模。第三,除了更高質素的數據集外,還需要可復現和外部驗證的證明,這樣才能增加模型被推進並整合到未來臨床試驗中的可能性。
然而,醫療封包含了大量患者私密。醫療機構或者患者絕對不會因為模型訓練願意承擔私密泄露的風險。聯邦學習則可以讓多個機構利用自己的數據進行多次叠代訓練模型,隨後將訓練完成的模型上傳共享。這個過程並不會涉及到敏感的臨床數據或病人私密,從而解決了大眾的擔憂。
假設三家醫院決定聯合起來建立一個中心深度神經網絡用於幫助自動分析腦腫瘤影像,並選擇使用客戶機-伺服器的聯邦學習。在整個架構中,中心伺服器將維護全域深度神經網絡。每個參與的醫院將獲得一個這個神經網絡模型的副本,以便使用自己的數據進行訓練。
一旦在本地對模型進行了幾次叠代訓練,參與者就會將模型的更新版本發送回中心伺服器。這個過程只發送訓練完成的模型及其參數,而不會像以往的方式發送病例數據。同時,傳輸數據經過特殊加密,具有很好的保護效果。
在收到各地上傳的更新模型後,伺服器將匯總各地上傳的、更新後的局部模型,並對全域模型進行更新。隨後,伺服器會與參與機構共享更新後的模型,以便它們能夠繼續進行本地訓練。
不難看出,在整個過程中,共享模型接觸到的數據範圍比任何單個組織內部擁有的數據範圍都要大得多,訓練也更為有效。與此同時,因為只需要傳輸模型數據,其對網絡傳輸頻寬的要求也降低了很多。
此外,全域模型的訓練並不依賴於特定的數據。因此,如果其中一家醫院離開模型訓練團隊也不會停止模型的訓練。同樣,一家新醫院可以隨時選擇加入該計劃以加速模型訓練。
聯邦學習使幾個組織能夠在模型開發上進行協作,但不需要彼此共享敏感的臨床數據及病人私密。業界希望這種新的方式能夠解決目前AI遇到的數據困境。相比傳統的模式,聯邦學習還可以鼓勵不同的機構合作建立一個可以使所有人受益的模型。
兩年來,聯邦學習在醫療上做了哪些探索?
自推出以來,業界就高度重視聯邦學習,並釋出了數個開源框架。這些開源框架分別由谷歌(Tensorflow Federated)、OpenMined(Pysyft)、百度(PaddleFL)和微眾銀行(Fate)等牽頭。與此同時,輝達Clara和微眾銀行也推出了聯邦學習的商業化產品。目前,聯邦學習已經在各行各業開花結果,醫療套用也是其中之一。
> >>>醫療影像上的套用
2019年10月,輝達(NVIDIA)將聯邦學習技術引入了旗下專門針對醫療影像領域的Clara平台,並與英國倫敦國王學院合作釋出了用於醫學影像分析且具有私密保護能力的聯邦學習系統。
透過支持聯邦學習的Clara平台,研究人員可以極大地簡化這一系統的部署難度,並能安全方便地對聯邦學習中心伺服器和協作客戶端進行配置,提供啟動聯邦學習專案所需的一切,包括應用程式容器和初始AI模型。
參與這一專案的醫院使用與醫院影像器材協作的Clara AI輔助註釋工具來標記自家患者的影像數據。使用預先訓練的模型和遷移學習技術,Clara能夠幫助放射科醫生進行標記,將復雜的3D研究時間從幾小時減少到幾分鐘。
各家醫院將利用這些數據,在本地EGX伺服器上訓練模型。本地訓練結果透過安全連結共享回聯邦學習中心伺服器,並由中心伺服器對全域模型進行更新。隨後,更新後的模型會與各醫院伺服器同步,以便各醫院對新模型進行進一步訓練。
全球領先的醫療健康機構——包括美國放射學院(簡稱ACR ,American College of Radiology)、麻省總醫院(Massachusetts General Hospital)和加州大學洛杉磯分校醫療中心(UCLA Medical Center)——都在搶先采用該技術,致力於為自己的醫生、患者和醫療設施開發個人化的AI套用,他們的醫療數據、應用程式和器材都在增加,同時患者私密必須得到保護。
ACR在其國家醫療成像平台AI-LAB中引入了NVIDIA Clara聯邦學習,從而幫助ACR的38000名醫療成像會員安全地構建、共享、調整並驗證AI模型。
2020年9月,由輝達、ACR、巴西DASA(拉丁美洲最大的第三方醫學實驗室)、美國麻省總醫院、妙佑醫療集團、史丹福大學、麻省理工學院上線了合作專案,透過聯邦學習在真實世界協作環境中訓練醫療影像AI模型,用於乳腺BI-RADS分類輔助診斷。
放射科醫生在分析乳房X光結果時,會一邊嘗試尋找腫瘤一邊評估乳房組織密度。所謂乳房組織密度是指女性乳房X光檢查中出現的纖維和乳腺組織量度。根據影像特征,被分為四大類別:脂肪類、散在纖維腺體類、不均勻致密類和極度致密類。
醫生進行乳房組織密度分類的原因很簡單——乳房密度高的女性患乳癌的風險要高4-5倍。根據統計,這類人群在美國40-74歲女性中占大約一半。因此,為醫生提供高質素的乳房密度分類輔助分類工具可以更好地評估患者的癌癥風險。
盡管所有參與專案機構共享的數據集(乳腺學系統、類分布和數據集大小)存在巨大差異,但AI模型訓練依然獲得成功,並展示了較好的效果。比較而言,使用聯邦學習訓練的模型比只接受各機構本地數據培訓的模型平均效能好6.3%,模型的可概括性相對提高了 45.8%。
> >>>新冠肺炎患者氧氣用量預測
聯邦學習在新冠病毒肆虐全球之際也做出了自己的貢獻——輝達和美國聯盟醫療體系(麻省總醫院和布列根和婦女醫院共建)的研究人員開發了一個AI模型。該模型可以透過胸部X光片、患者生命體征和化驗結果,來預測急診室內的新冠肺炎患者是否需要在初步檢查後的幾小時或幾天中吸氧,進而預測急救室需要的氧氣量,及判斷患者是否需要轉入ICU。
為了開發一種可靠的AI模型,並將其推廣到盡可能多的醫院,輝達和美國聯盟醫療體系啟動了名為EXAM(EMR CXR AI Model)的計劃。這項計劃與來自全球的20家醫院合作,是目前規模最大、最多樣化的聯邦學習計劃之一。
這些醫院分布在北美洲、南美洲、亞洲和歐洲,數據涵蓋了不同人種患者的數據集。每家醫院都使用NVIDIA Clara來訓練其本地模型並參與EXAM。在整個過程中,各家機構無需將患者的胸部X光片和其他保密資訊統一匯總,而是使用安全的內部伺服器來儲存其數據。
全域深度神經網絡模型則托管在亞馬遜AWS獨立伺服器上,每家參與合作的醫院都可獲得一份副本用於在自有數據集上進行訓練。
基於模型對各種分布式數據進行訓練,最終專案開發完成AUC值為0.94(目標為1.0)的模型僅僅耗時兩周,其預測住院病人所需氧氣量的能力非常出色。由於吸氧對於新冠肺炎患者來說至關重要,這一技術平台已被整合至Clara NGC之中,將挽救不少生命。
> >>>可穿戴醫療健康器材
在醫療健康領域有著重要用途的可穿戴器材也在引入聯邦學習。可穿戴器材可以準確記錄使用者的日常活動及體征資訊,對於部份疾病的預防和早篩極有價值。同時,可穿戴器材在心理健康領域、用於患者或老人的跌倒檢測以及健身鍛煉監控上也有套用價值。全球可穿戴醫療健康器材在近年得到了突破,出貨量屢創新高,積累了海量的數據。
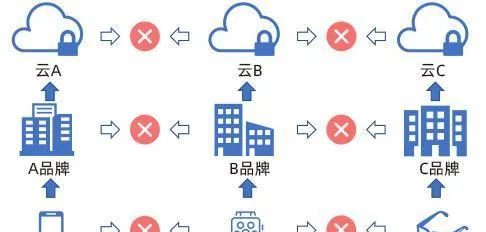
傳統的方法對於可穿戴器材來說是個巨大的難點(圖片來自IEEE Intelligent Systems , Volume: 35 Issue: 4:FedHealth: A Federated Transfer Learning Framework for Wearable Healthcare)
然而,如何套用這些數據有兩大難點。首先,這些數據各自為政。假設使用者使用了兩款來自不同品牌的可穿戴器材,這些數據即使上傳至雲端也是彼此隔離無法分享的。更進一步來說,隨著各國或地區加強數據安全立法,對數據儲存的地理位置也提出要求。同一品牌器材商要想獲取儲存在世界各地的數據也非常困難。這將導致訓練模型所用的數據無論在質素還是數量上都很難達到標準。
其次,傳統的模型訓練方法是通用的,缺乏個人化和針對性。然而,不同的使用者其實有著不同的體征特點,基於通用模型的可穿戴器材並不能最好地匹配他們的需求。
2020年,中科院泛在計算系統研究中心、中國科學院大學、深圳鵬城實驗室和微軟亞洲研究院聯合提出了FedHealth架構,也是首個針對可穿戴醫療健康器材的聯邦遷移學習框架。
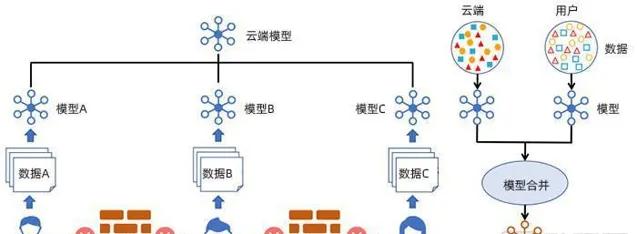
聯邦學習可以有效地將分散的可穿戴器材數據予以利用(圖片來自IEEE Intelligent Systems , Volume: 35 Issue: 4:FedHealth: A Federated Transfer Learning Framework for Wearable Healthcare)
透過聯邦學習和同態加密,FedHealth得以在保證使用者數據私密和安全的前提下為訓練強勁模型提供源源不斷的數據。在全域模型完成訓練後,它又可以透過引入遷移學習來實作個人化需求。此外,這一可以增量升級的框架還可以進一步擴充套件並部署到多種醫療健康套用上以進一步在真實世界中增強學習能力。
透過對30位實驗參與者采集的總計10299組數據進行的實驗,FedHealth對於可穿戴器材行為辨識的準確率有一定提升。相比未采用聯邦學習方式的深度學習,FedHealth訓練模型的準確率提升了5.3%。
> >>>腦卒中預測
作為公認最早研究「聯邦學習」的國際人工智能專家之一,微眾銀行首席人工智能官楊強教授推動了微眾銀行AI團隊成為國行內邦學習技術的引領者,並將其套用於實際業務。目前,微眾銀行已經在金融、醫療等行業領域落地套用聯邦學習。
2018年12月,微眾銀行更是發起了關於【聯邦學習架構和套用規範】的標準立項,並獲得了IEEE標準委員會的立項批準。來自國內外的多位知名學者和技術專家紛紛加入標準工作群組,參與到聯邦學習IEEE標準的建設中。
2019年,騰訊天衍實驗室和微眾銀行在醫療大數據、醫學影像輔助診斷等領域展開合作,並聯合開發了基於醫療聯邦學習框架的「腦卒中發病風險預測模型」。模型利用NLP技術對電子病歷進行處理,透過分析辨識與腦卒中高度關聯的癥狀來預測病人腦卒中發病風險。
中國中部某市五家醫院(其中三家為該市頭部三甲醫院)參與了研究,並利用各自的電子病歷數據對模型進行了訓練。結果顯示,利用聯邦學習訓練的模型預測準確率高達80%。同時,大型三甲醫院數據資源可幫助醫療服務匱乏病例少小型醫院在模型預測指標上提升10-20%。
2020年8月,騰訊醫療健康與微眾銀行成立聯合實驗室,結合騰訊天衍實驗室在醫療影像、醫療機器學習與自然語言處理的技術積累,以及微眾銀行AI團隊在聯邦學習上的領先技術,聯合實驗室將進一步攻堅聯邦學習在醫療領域的套用。
> >>>藥物發現
基於AI在藥物發現上的巨大潛力,聯邦學習也已經在這一場景有所進展。2020年12月,同濟大學生物資訊系與微眾銀行合作,透過聯邦學習模擬多個制藥機構之間的藥物協同開發,助力制藥機構在保障自身藥物數據私密安全的前提下進行協同藥物發現。
AI藥物發現面臨的最大痛點在於該領域復雜的知識產權和相關的經濟利益使得制藥機構之間進行數據直接共享和合作幾乎不可能。透過在藥物小分子領域引入聯邦學習進行藥物協同開發,可以在保護藥物小分子結構私密的前提條件下,獲得與直接整合多機構小分子數據進行QSAR建模相同或者類似的模型預測效果。這或許能夠幫助實作合作「破冰」。
研究首次嘗試在藥物小分子領域探索使用聯邦學習範式進行藥物協同開發的可行性,結合微眾銀行的聯邦學習開源平台FATE,開發了基於聯邦學習的協作藥物發現平台FL-QSAR。
研究團隊透過對於包含了15個藥靶的QSAR 基準數據來構建深度學習模型,進行QSAR建模以及多制藥機構環境下的協同藥物開發模擬。研究結果顯示了將聯邦學習用於藥物發現具有兩方面的優勢。
首先,多個制藥機構透過FL-QSAR進行協同QSAR建模,效果顯著優於單機構僅使用其私有數據本地QSAR建模。其次,透過特定的模型最佳化,FL-QSAR可以在保護藥物小分子結構私密的前提條件下,獲得與直接整合多機構小分子數據進行QSAR建模相同或者類似的模型預測效果。
這是一種有效的藥物協同發現的解決方案,打破了傳統QSAR建模時不同制藥機構之間的數據無法直接共享的壁壘,有助於在私密保護的前提條件下進行協同藥物發現,並得到了國家專項專案基金資助。
私密計算的未來——更優的聯邦學習及去中心化的蜂群計算
盡管問世時間不長,但聯邦學習架構本身也一直在得到改進。比如,2020年,商湯科技就攜手美國羅格斯大學電腦系計算生物醫學成像和建模研究中心,發表了一項新的研究成果——利用基於分布式生成對抗網絡(GAN)的結構來實作聯邦學習。
該研究透過將位於多個彼此分離機構的分布式異步鑒別器和一個中心生成器組成對抗網絡,讓中心生成器在不接觸原始私密數據的情況下,也能進行合成訓練,從而能夠生成與各機構原始數據相近似的合成數據樣本,供下遊任務使用。
在此基礎上,這一方案還采用了2種損失函數,使得中心生成器具備一定的終身學習能力,可以在動態變化(比如學習過程中有新的機構加入或某些原有機構結束的情況)的環境中持續訓練模型。
經試驗模擬,這套學習方法能夠從不同的機構中漸進地學習到同類數據甚至不同類數據的近似分布,並在醫學影像分割任務中,取得了理想效果。
與傳統的聯邦學習相比,商湯科技的方案可以有效減少中心與各機構之間的通訊數據量,僅需傳輸合成影像數據和反饋誤差,而非整個模型的所有參數數據,而且各機構之間無需交換任何數據或參數,可顯著降低醫療機構部署聯邦學習的成本,加快研究效率和AI模型的生產速度。
除了對聯邦學習進行改進,業界也在開發新的解決方案。不久前的2021年5月,德國研究人員在Nature上釋出了論文,提出了一種去中心化的機器學習方法Swarm Learning(蜂群學習),將邊緣計算和基於區塊鏈的對等網絡結合,用於不同醫療機構之間醫療數據的整合。
聯邦學習雖然解決了數據私密,但是全域模型及參數調節仍然由特定機構的中心伺服器處理,必然造成了權力集中。此外,這種星形結構容錯性較低。相比之下,蜂群學習不再需要中心伺服器交換數據或全域建模,允許參數合並,從而實作所有成員權利平等,並透過去中心化很好地保護機器學習模型免受攻擊。
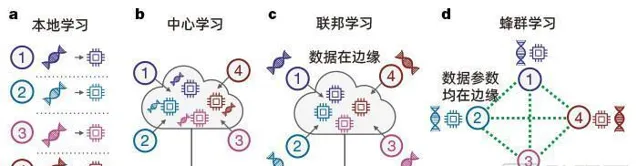
在本地學習(a)中,數據和計算是分別在不同的機構且彼此隔離的情況下實作。在中心學習(b)中,來自不同機構的數據和參數被集中到雲上實作模型訓練。在聯邦學習(c)中,數據和訓練仍然位於本地,但全域模型的參數設定和模型共享在中心實作。在蜂群學習(d)中,數據和參數去中心化,且彼此互聯,不需要中心。(圖片來自Nature:Swarm Learning for decentralized and confidential clinical machine learning)
這個蜂群學習的研究選擇了結核病、新冠肺炎、白血病和肺部病變這四種異質性疾病來說明使用蜂群學習基於分布式數據開發疾病分類系統的可行性。
研究嘗試了利用蜂群學習從外周血單核球數據中預測白血病,從血液轉錄組數據中辨識結核病患者或肺部病變患者,以及辨識和檢測新冠肺炎患者。訓練所需的數據集包括來自127項臨床研究中的16400多個血液轉錄組,以及95000多張胸部X光影像。這些數據集的病例和對照分布並不均勻,存在大量偏差。
結果表明經過蜂群學習訓練的分類模型效能優於基於本地數據訓練的分類模型。此外,蜂群學習還引入了區塊鏈技術,結合了去中心化的硬件基礎設施,防止數據被篡改;同時,成員自主權大幅提升,可以安全加入、動態選舉領導者乃至合並模型參數。
總的來說,研究認為蜂群學習有可能比聯邦學習更能改變當前的格局,去中心化的數據模型有可能成為處理、儲存、管理和分析任何種類的大型醫療數據集的首選。
寫在最後
全球對數據私密及安全的重視程度日益增加,在醫療領域更是如此。聯邦學習及蜂群學習所代表的私密計算因其可保證數據私密且具有更好的效能等特性,將在未來決定醫療AI是否能夠進一步向前發展。不少研究團隊都在從事相應的探索,並將其套用到具體的醫療套用場景中。
盡管如此,目前真正將聯邦學習實施落地的具體醫療場景仍然屈指可數。這一先進架構仍然面臨一些具體的問題,包括醫療機構數據質素普遍較差、模型訓練缺乏醫生參與使其難以說服醫生使用、缺乏足夠激勵措施吸引數據方參與、具有個人化的模型訓練難度較大以及應對復雜場景的模型精度不足等。
好訊息是,在標準建設上聯邦學習已經取得了進展——2021年3月,IEEE正式完成了標準制定工作,形成了正式標準檔IEEE P3652.1。與此同時,備受關註的【個人資訊保護法】草案也在今年提請全國人大常委會二次審議,即將正式實施。這就為之後各細分領域的進展提供了依據。要不了多久,我們就將看到私密計算在實際套用場景中大顯身手。
參考資料
MICCAI Workshop on Domain Adaptation and Representation Transfer & MICCAI Workshop on Distributed and Collaborative Learning:Federated Learning for Breast Density classification: A Real-World Implementation
Medical Image Analysis, Volume 70, May 2021, 101992:Federated semi-supervised learning for COVID region segmentation in chest CT using multi-national data from China, Italy, Japan
IEEE Intelligent Systems , Volume: 35 Issue: 4:FedHealth: A Federated Transfer Learning Framework for Wearable Healthcare
Nature: Common pitfalls and recommendations for using machine learning to detect and prognosticate for COVID-19 using chest radiographs and CT scans
http:// arXiv.org :Privacy-Preserving Technology to Help Millions of People: Federated Prediction Model for Stroke Prevention
Nature:Swarm Learning for decentralized and confidential clinical machine learning
http:// arXiv.org :Learn distributed GAN with Temporary Discriminators
Bioinformatics doi: 10.1093/bioinformatics/btaa1006:FL-QSAR: a federated learning based QSAR prototype for collaborative drug discovery
雷鋒網:【聯邦學習首個國際標準正式釋出!】
第一財經:【銀行紮堆聯邦學習,大規模落地還有多遠?】











