這裏是「
王喆的機器學習筆記
」的第三十八篇文章。今天我們聊一聊推薦、廣告、搜尋演算法的區別。我自己在推薦系統和計算廣告這兩個方向分別工作了4年和5年的時間,對兄弟團隊的搜尋演算法也有比較多的了解,再加上近來陸續有不少同行邀請過回答類似問題,所以這裏就寫一篇文章總結一下自己的思路。
作為互聯網的核心套用「
搜廣推
」,三個方向基本都是互聯網公司的標配。各頭部公司的搜廣推系統也都各自發展成了整合了多種模型、演算法、策略的龐然大物,想一口氣講清楚三者的區別並不容易。不過萬事總有一個頭緒,對於一個復雜問題,直接深入到細節中去肯定是不明智的,我們還是要回到問題的本質上來,回到搜廣推分別想解決的根本問題上來,才能一步步的把這三個問題分別理清楚。
根本問題上的區別
廣告:一個公司要搭建廣告系統,它的商業目的非常直接,就是要解決公司的收入問題。所以
廣告演算法的目標就是為了直接增加公司收入
。
推薦:推薦演算法雖然本質上也是為了增加公司收入,但其
直接目標是為了增加使用者的參與度
。只有使用者的參與度高了,才能讓廣告系統有更多的inventory,進而增加公司營收。
搜尋:搜尋要解決的關鍵問題全部是圍繞著使用者輸入的搜尋詞展開的。雖然現在搜尋越來越強調個人化的結果,但是一定要清楚的是,推薦演算法強調的個人化永遠只是搜尋演算法的補充。「
圍繞著搜尋詞的資訊高效獲取問題「才是搜尋演算法想解決的根本問題。
正是因為三者間要解決的根本問題是不同的,帶來了三者演算法層面的第一個區別,那就是最佳化目標的區別。
最佳化目標的區別
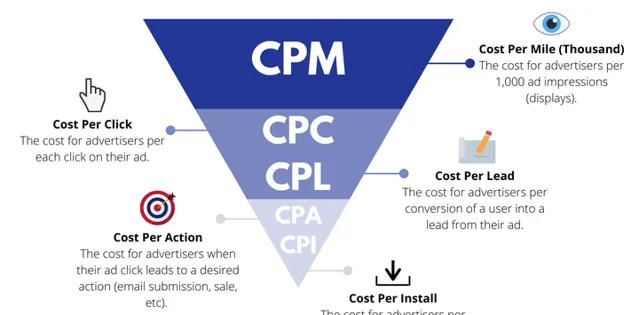 廣告系統的各種計費方式
廣告
:各大公司廣告演算法的預估目標非常統一,就是
預估CTR和CVR。
這是跟當前效果類廣告的產品形態密切相關的。因為CPC和CPA計價仍是效果類廣告系統的主流計價方式。所以只有預估出CTR和CVR,才能反向推匯出流量的價值,並進一步給出合理的出價。所以針對這樣的目標,廣告演算法非常看重把
預估偏差
當作首要的評價指標。
推薦
:推薦演算法的預估目標就不盡相同,影片類更多傾向於預測觀看時長,新聞類預測CTR,電商類預估客單價等等這些
跟使用者參與度最相關的業務指標
。而且由於推薦系統的推薦場景是生成一個列表,所以更加關註item間的相對位置,因此評估階段更傾向於用AUC,gAUC,MAP這些指標作為評價標準。
搜尋
:搜尋的預估目標又有所不同,因為相比廣告和推薦,搜尋某種意義上說是存在著「正確答案」的。所以
搜尋非常看重能否把這些正確答案給召回回來
(廣告和推薦也關註召回率,但重要性完全不同)。所以搜尋系統往往會針對召回率,MAP,NDCG這些指標進行最佳化。
廣告系統的各種計費方式
廣告
:各大公司廣告演算法的預估目標非常統一,就是
預估CTR和CVR。
這是跟當前效果類廣告的產品形態密切相關的。因為CPC和CPA計價仍是效果類廣告系統的主流計價方式。所以只有預估出CTR和CVR,才能反向推匯出流量的價值,並進一步給出合理的出價。所以針對這樣的目標,廣告演算法非常看重把
預估偏差
當作首要的評價指標。
推薦
:推薦演算法的預估目標就不盡相同,影片類更多傾向於預測觀看時長,新聞類預測CTR,電商類預估客單價等等這些
跟使用者參與度最相關的業務指標
。而且由於推薦系統的推薦場景是生成一個列表,所以更加關註item間的相對位置,因此評估階段更傾向於用AUC,gAUC,MAP這些指標作為評價標準。
搜尋
:搜尋的預估目標又有所不同,因為相比廣告和推薦,搜尋某種意義上說是存在著「正確答案」的。所以
搜尋非常看重能否把這些正確答案給召回回來
(廣告和推薦也關註召回率,但重要性完全不同)。所以搜尋系統往往會針對召回率,MAP,NDCG這些指標進行最佳化。
總的來說,
廣告演算法是要「估得更準」,推薦演算法是要整體上「排的更好」,搜尋演算法是要「搜的更全」
。
演算法模型設計中的區別
最佳化目標有區別,這就讓它們
演算法模型設計
中的側重點完全不一樣:
廣告:由於廣告演算法要預測「精準」的CTR和CVR,用於後續計算精確的出價
,因此數值上的「精準」就是至關重要的要求,僅僅預估廣告間的相對位置是無法滿足要求的。這就催生了廣告演算法中對calibration方法的嚴苛要求,就算模型訓練的過程中存在偏差,比如使用了負采樣、weighted sampling等方式改變了數據原始分布,也要根據正確的後驗概率在各個維度上矯正模型輸出。此外,因為廣告是很少以列表的形式連續呈現的,要對每一條廣告的CTR,CVR都估的準,
廣告演算法大都是point wise的訓練方式
。
推薦:推薦演算法的結果往往以列表的形式呈現,因此不用估的那麽準
,
而是要更多照顧一個列表整體上,甚至一段時間內的內容多樣性上對於使用者的「吸重力」,讓使用者的參與度更高
。因此現在很多頭部公司在演算法設計時,不僅要考慮當前推薦的item的吸重力,甚至會有一些list level,page level的演算法去衡量整體的效果進行最佳化。也正因為這一點,推薦演算法有大量不同的訓練方式,
除了point-wise,還有pair-wise,list-wise等等
。此外為了增加使用者的長期參與度,還對推薦內容的
多樣性,新鮮度
有更高的要求,這就讓探索與利用,強化學習等一些列方法在推薦場景下更受重視。
搜尋
:對於搜尋演算法,
我們還是要再次強調搜尋詞的關鍵性,以及對搜尋詞的理解
。正因為這樣,搜尋詞與其他特征組成的交叉特征,組合特征,以及模型中的交叉部份是異常重要的。對於一些特定場景,比如搜尋引擎,我們一定程度上要抑制個人化的需求,更多把質素和權威性放在更重要的位置。
 推薦系統中的探索與利用問題占有非常重要的地位
推薦系統中的探索與利用問題占有非常重要的地位
輔助策略和演算法上的區別
除了主模型的差異,跟主模型配合的
輔助策略/演算法
也存在著較大的區別。
廣告系統中,CTR等演算法只是其中關鍵的一步,估的準CTR只是一個前提,
如何讓廣告系統盈利,產生更多收入,還需要pacing,bidding,budget control,ads allocation等多個同樣重要的模組協同作用,才能讓平台利益最大化
,這顯然是比推薦系統復雜的。
推薦系統中,由於需要更多照顧使用者的長期興趣,需要一些補充策略做出一些看似「非最優」的選擇,
比如探索性的嘗試一些長尾內容,在生成整個推薦列表時要加入多樣性的約束,等等
。這一點上,廣告系統也需要,但遠沒有推薦系統的重視程度高。
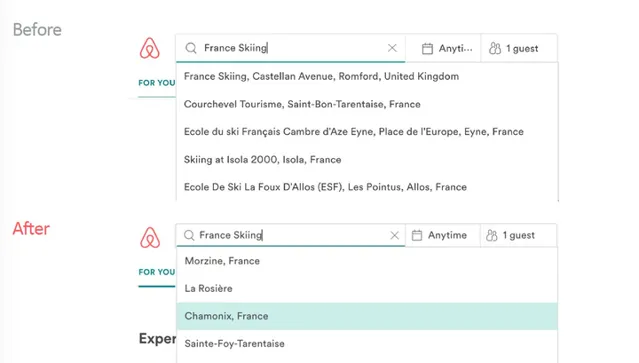
搜尋系統中,
大量輔助演算法還是要聚焦在對搜尋詞和內容的理解上
。因此搜尋系統往往是套用NLP模型最重的地方,因為需要對大量內容進行預處理,embedding化,進而生成更理解使用者語意的結果。比如最典型的例子就是airbnb對搜尋詞embedding化後,輸入滑雪skiing,會返回更多滑雪勝地的地點,而不是僅僅是字面上的匹配。
模型本身的差異
最後才談到
模型本身的差異,
因為相比上面一路走來的關鍵問題,模型本身的差異反而是更細節的問題,這裏從模型結構的層面談一個典型的差異:
在廣告模型中,使用者的興趣是不那麽連貫的,因此容易造成sequential model的失效,attention機制可能會更加重要一些。
推薦模型中,如果不抓住使用者興趣的連續變化,是很難做好推薦模型的,因此利用sequential model來模擬使用者興趣變化往往是有收益的。
搜尋模型中,搜尋詞和item之間天然是一個雙塔結構,因此在模型構建的時候各種交叉特征,模型中的各種交叉結構往往是搜尋類模型的重點。當然,在構建良好的交叉特征之後,使用傳統的LTR,GBDT等模型也往往能夠取得不錯的結果。
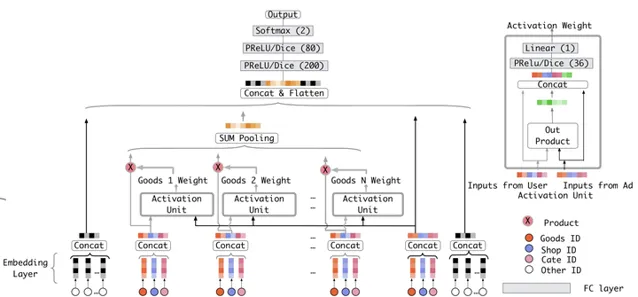 經典的Attention推薦模型DIN
經典的Attention推薦模型DIN
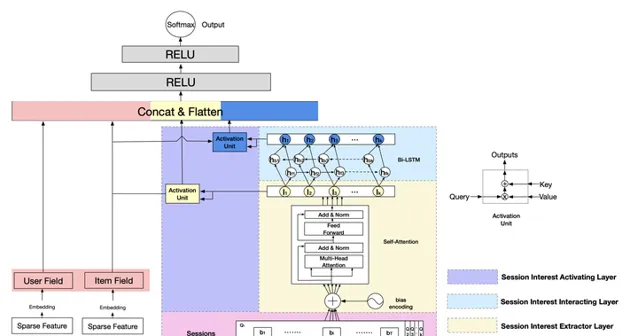 融合了序列結構的推薦模型DSIN
融合了序列結構的推薦模型DSIN
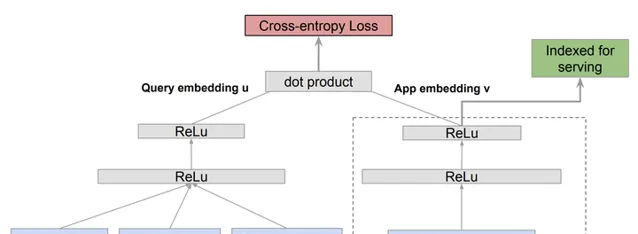 Google play的搜尋雙塔模型
Google play的搜尋雙塔模型
系統層面的痛點
總體感覺上,廣告演算法的問題更加瑣碎,
各模組協同工作找到平台全域利潤最大化方法的難度非常大
,系統異常復雜到難以掌控的地步,這是廣告演算法工程師的痛點;
而推薦演算法這邊,
問題往往卡在長期利益與短期利益的平衡上
,在模型結構紅利消失殆盡的今天,如何破局是推薦演算法工程師們做夢都在想的問題。
搜尋演算法則往往把重心放在
搜尋詞和item的內容理解上
,只要能做好這一點,模型結構本身反而不是改進的關鍵點了,但是在多模態的時代,圖片、影片內容的理解往往是制約搜尋效果的痛點。
最後歡迎大家關註我的
微信公眾號:王喆的機器學習筆記
(
wangzhenotes
),跟蹤計算廣告、推薦系統等機器學習領域前沿。想進一步交流的同學也可以
透過公眾號加我的微信
一同探討技術問題。











