編輯:桃子
【新智元導讀】合成數據2.0秘訣曝光了!來自微軟的研究人員們提出了智能體框架AgentInstruct,能夠自動建立大量、多樣化的合成數據。經過合成數據微調後的模型Orca-3,在多項基準上重新整理了SOTA。
全世界高質素數據幾乎枯竭。
AI科學家們為了解決這一難題,可謂是絞盡腦汁。

目前來看,合成數據或許就是大模型的未來,也成為業界公認的解決之法。
就連輝達科學家Jim Fan曾發文表示,合成數據將提供下一萬億個高質素的訓練token。

但是,用合成數據,並非完全對LLM訓練有幫助。
前段時間,Nature封面研究顯示,合成數據叠代9次後,會讓大模型崩潰。而且,類似的研究比比皆是。
那麽,我們該怎麽辦呢?
最近,微軟團隊提出了可延伸的智能體框架——AgentInstruct,可自動建立大量多樣化、高質素的合成數據。
它最大的優勢在於,僅只用原始資料來源,就能建立完整的提示和回應。

論文地址:https://arxiv.org/pdf/2407.03502
對此,研究人員使用AgentInstruct,建立了2500萬對「後訓練」數據集,涵蓋了多種使用技能,如文本編輯、創意寫作、工具使用、編碼、閱讀理解等。
然後,他們利用這些數據對Mistral-7b進行後訓練,得到了Orca-3模型。
與原始的Mistral-7b-Instruct相比,Orca-3在多個基準測試中,都顯示出顯著的效能提升。
而在數學方面上的表現,效能直接暴漲168%。

當「合成數據」遇上智能體
過去一年,我們見證了智能體的興起。
智能體可以生成高質素的數據,透過反思和叠代,其能力反超了底層基礎大模型。
在這個過程中,智能體可以回顧解決方案,自我批評,並改進解決方案。它們甚至可以利用工具,如搜尋API、小算盤、程式碼解釋,來擴充套件大模型的能力。

此外,多智能體還可以帶來更多的優勢,比如模擬場景,同時生成新的提示和響應。
它們還可以實作數據生成工作流的自動化,減少或消除某些任務對人工幹預的需求。
論文中,作者提出了「生成式教學」的概念。
這是說,使用合成數據進行後訓練,特別是透過強大的模型建立數據,來教另一個模型新技能或行為。
AgentInstruct是生成式教學的一個智能體解決方案。
總而言之,AgentInstruct可以建立:
- 高質素數據:使用強大的模型如GPT-4,結合搜尋和程式碼直譯器等工具。
- 多樣化數據:AgentInstruct同時生成提示和回應。它使用多智能體(配備強大的LLM、工具和反思流程)和一個包含100多個子類別別的分類法,來建立多樣化和高質素的提示和回應。
- 大量數據:AgentInstruct可以自主執行,並可以套用驗證和數據過濾的流程。它不需要種子提示,而是使用原始文件作為種子。

生成式教學:AgentInstruct
我們如何建立海量數據?如何保證生成的數據具有多樣性?如何生成復雜或微妙的數據?
為此,研究人員概述了解決這些挑戰的結構化方法:

具體來說,AgentInstruct定義了三種不同的自動化生成流程:
內容轉換流程:將原始種子轉換為中間表示,簡化了針對特定目標建立指令的過程。
種子指令生成流程:由多個智能體組成,以內容轉換流程的轉換後種子為輸入,生成一組多樣化的指令。
指令改進流程:以種子指令流程的指令為輸入,叠代地提升其復雜性和質素。
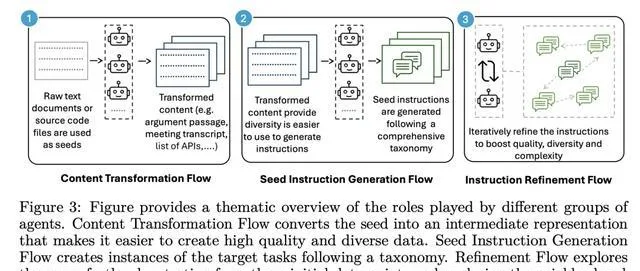
接下來,研究人員為為17種不同的技能實作了這些流程,每種技能都有多個子類別別。
這些技能包括閱讀理解、問答、編碼、檢索增強生成、創意寫作、工具/API使用和網絡控制。
完整列表,如下表1中所示。

接下來,研究人員透過以下三種技能的案例研究,來解釋這些工作流是如何運作的。



實驗結果
正如開頭所述,研究人員使用2580萬對指令,微調Mistral-7b-v0.1模型,然後得到Orca-3。
那麽經過使用AgentInstruct數據訓練Orca-3,效能究竟如何?
AgentInstruct的目標是合成一個大型且多樣化的數據集,其中包含不同難度級別的數據。
在這個數據集上,像Orca-2.5、Mistral-Instruct-7b和ChatGPT這樣的基準模型得分遠低於10分,顯示出它們相對於GPT-4(被指定為基準,得分為10)的劣勢。
圖4中描繪的效能比較展示了基準模型與Orca-3之間的對比分析。
這個圖顯示了在AgentInstruct數據的支持下,後訓練過程中各種能力的顯著提升。
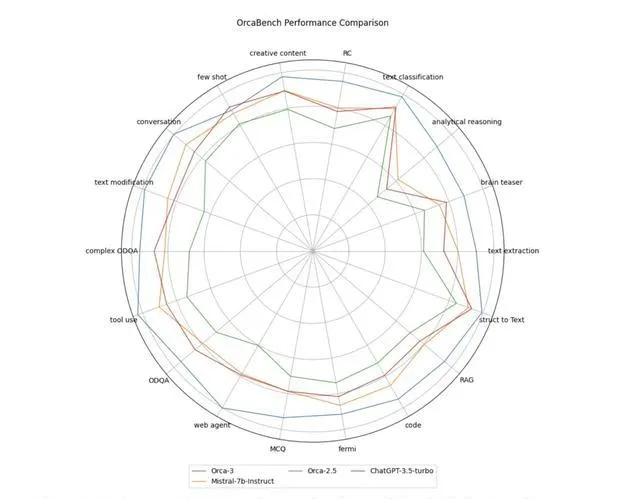
表2概括了所有評估維度的平均得分。
平均而言,包括每輪訓練輪後的Orca-3,AgentInstruct數據的引入使效能相比Orca 2.5基準提高了33.94%,相比Mistral-Instruct-7B提高了14.92%。

重新整理多項基準SOTA
表3中給出了每個基準的所有基線的結果。
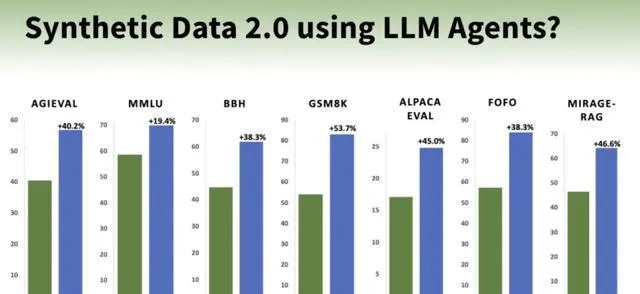
比如,在AGIEval提升40%,在MMLU上提升19%,在GSM8K上提升54%,在BBH上提升38%,在AlpacaEval上提升45%。
此外,它在效能上持續超過其他模型,如LLAMA-8B-instruct和GPT-3.5-turbo。

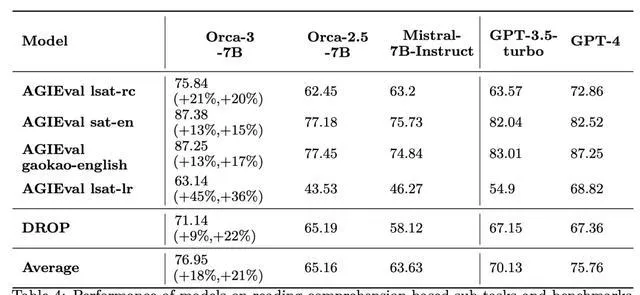
就閱讀理解任務來說,對於LLM至關重要。對於小模型來說,也更為重要。
透過使用AgentInstruct進行針對性訓練,可以觀察到Mistral的閱讀理解能力有了實質性的提升(見表4)——相比Orca 2.5提高了18%,相對於Mistral-Instruct-7b提高了21%。
此外,透過利用這種數據驅動的方法,研究人員將一個7B參數的模型在LSATs的閱讀理解部份的表現,提升到了與GPT-4相匹配的水平。
再拿數學來說,透過AgentInstruct,成功提升了Mistral在從小學到大學水平的各種難度數學問題上的熟練程度,如下表5所示。
在各種流行的數學基準測試上,改進振幅從44%-168%不等。
應當強調的是,生成式教學的目標是教授一種技能,而不是生成數據來滿足特定的基準測試。AgentInstruct在生成式教學方面的有效性透過在各種數學數據集上的顯著改進得到了證明。
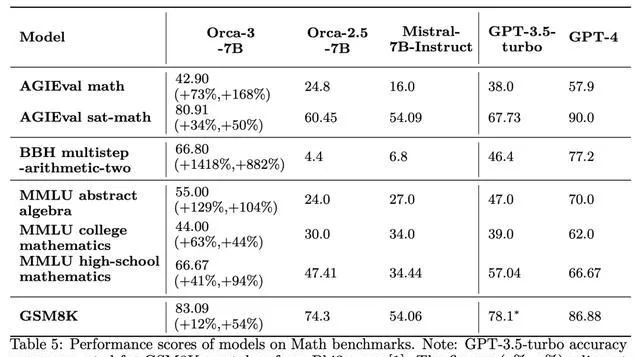
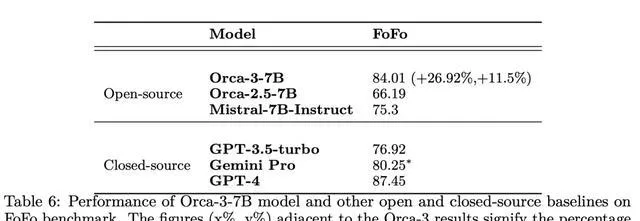
表6顯示了,Orca-3-7B模型和FoFo基準上,其他開源和閉源基準的效能。
另外,透過 AgentInstruct 方法,成功地將模型幻覺減少31.34%,同時達到了與GPT-4(教師)相當的質素水平。

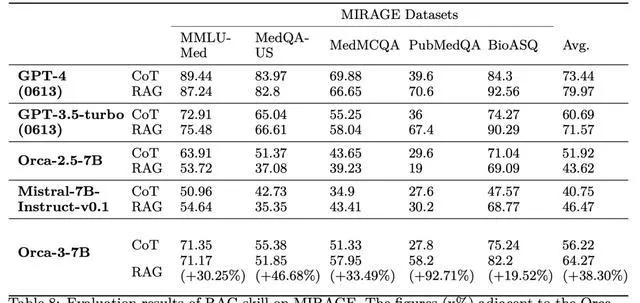
表8顯示了使用/不使用RAG的MIRAGE上所有模型的結果。
總之,AgentInstruct生成教學方法,為模型後訓練生成大量多樣化和高質素數據的挑戰,提供了一個有前途的解決方案。











