編輯:LRS
【新智元導讀】研究人員透過案例研究,利用大型語言模型(LLMs)如GPT-4、Claude 3和Llama 3.1,探索了思維鏈(CoT)提示在解碼移位密碼任務中的表現;CoT提示雖然提升了模型的推理能力,但這種能力並非純粹的符號推理,而是結合了記憶和概率推理的復雜過程。
「推理」是非常能展現「人類智能」的一項能力,需要結合現有證據和過去的經驗,以邏輯和系統的方式思考某件事情,進而做出決策。
大型語言模型(LLMs)以其通用性,在多項任務上都取得了出色的效能,雖然思維鏈(CoT)提示已經證明了大模型具備多步推理能力,但這種能力到底來自於「抽象泛化」(abstract generalization)還是「淺層啟發式」(shallow heuristics),仍然沒有定論。
為了深入理解影響 CoT 推理的因素,普林斯頓大學、耶魯大學的研究人員最近釋出了一項案例研究,使用三個大模型(GPT-4、Claude 3 和 Llama 3.1)利用CoT提示來執行解碼移位密碼(decoding shift ciphers)的符號推理任務。

論文地址:https://arxiv.org/abs/2407.01687
文中只關註這一個簡單的任務,能夠系統地分析出影響 CoT 效能的三個因素:任務的預期輸出(概率)、模型在預訓練期間隱式學習的內容(記憶),以及數量推理中涉及的中間操作(雜訊推理)。
實驗結果顯示,這些因素可以極大地影響模型的準確率,並且可以得出結論,CoT提示帶來的效能提升,既反映了模型在推理過程中有記憶的因素,也有真實推理的概率因素。
研究方法
以往的方法在研究模型推理能力時,往往在一系列復雜的推理任務上進行評估,其中任務的多樣性和復雜性可能會掩蓋CoT推理背後的影響因素,所以這篇論文只關註一個相對簡單的任務:使用移位密碼編碼的文本進行破譯(deciphering text encoded with a shift cipher)。
使用移位密碼(shift cipher)來編碼訊息的過程為,將每個字母替換為在字母表中向前移動一定數量位置(shift_level)的另一個字母;解碼則為相反的操作,即向後移動。
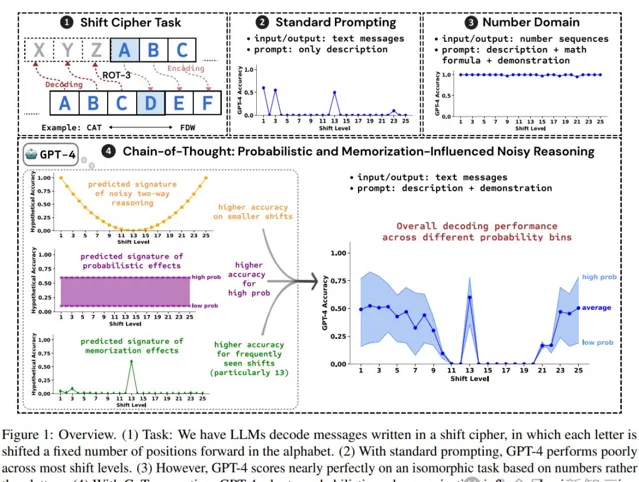
這種密碼也可以稱為旋轉密碼(rotation ciphers),過程等價於將字母表向前旋轉一定數量的步rot-k,其中k對應於shift_level
例如,給定測試詞「FDW」並使用rot-3加密(shift_level = 3),解碼需要將每個字母向後移動3步,即F → C,D → A,W → T,最後獲得解碼輸出「CAT」。
在實驗設計時,研究人員給大模型輸入一個使用移位密碼編碼的單詞,並要求模型對文本進行解碼以恢復原始單詞。
任務動機
研究人員使用移位密碼任務的主要出發點在於「任務復雜性」和「任務頻率」之間存在明顯的分離。
解密任務的復雜性也可以動態變化,移位級別(shift level)更高的密碼,需要更多中間步驟,也更復雜;不同的移位級別在互聯網文本中的頻率也不同,在大型語言模型的訓練數據中也是如此。
比如rot-13在互聯網論壇中廣泛用於隱藏文本,如謎題解答和劇透,而rot-3和rot-1通常用在解密教程中(rot-3也被稱為凱撒密碼)。
此外,移位密碼有助於研究概率的影響,因為正確答案可以是任意字串,可以很容易地調節字串的概率,並且生成樣本和正確性驗證也很容易。
最重要的是,解碼資訊時,每個字母都是一個獨立的步驟,更容易分析。
CoT在移位密碼上的影響
數據
研究人員構建了一個數據集,每個單詞包含7個字母(從詞表中組合3個字母和4個字母的單詞),用GPT-4分詞器後為2個token,以控制與分詞器無關的因素。
使用GPT-2計算對數概率,用句子「The word is "WORD"」的對數概率減去「The word is」的對數概率,然後把單詞按其對數概率評分,並按降序排列。
透過選擇等距的對數概率值作為中心,形成了五個區間,其中區間1具有最高的概率,區間5具有最低的概率,再手動檢查了數據集中的單詞,並進行了篩選,以確保沒有使用不恰當的單詞,其中每個區間包含150個單詞。
數據集中總共包含150個樣本,劃分為兩個子集:1)包含100個單詞以評估GPT-4;2)包含50個單詞,用於評估擬合到GPT-4在100個單詞子集上表現的邏輯回歸模型。
最後在1-25移位級別上生成來自5個概率區間的單詞的移位密碼編碼版本,作為模型的輸入;評估只執行一次,基於100個樣本報告準確率。
評估提示
研究人員使用多種不同的提示對數據集的效能進行了評估:
1. 標準(standard)提示 ,只有任務描述和演示但沒有推理步驟的提示;
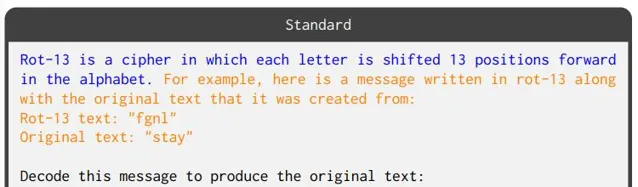
2. 文本思維鏈(Text-CoT) ,使模型逐個字母解碼訊息。

要想正確得到推理步驟,模型必須在預訓練期間學會字母表。
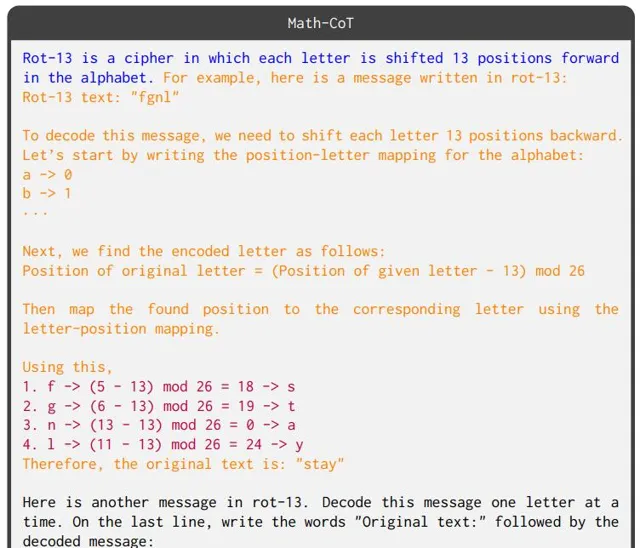
3. 數學思維鏈(Math-CoT) ,模型需要將每個字母轉換為數碼,然後透過數碼套用算術來執行移位,再將結果轉換回字母;提示中還指定了字母和位置之間的對映。
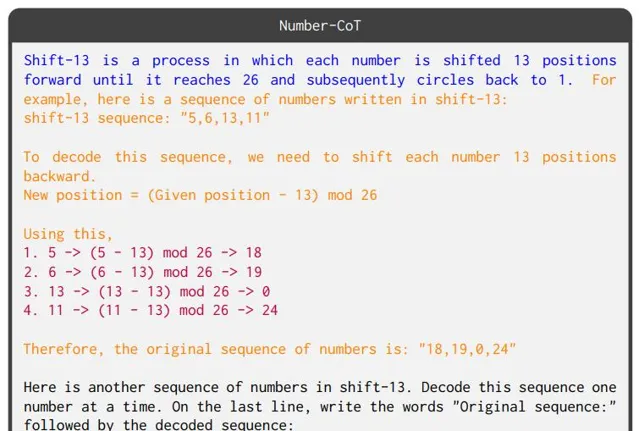
4. 數碼序列思維鏈(Number-CoT) ,該任務基於數碼域(即輸入和輸出是數碼序列),與移位密碼同構;推理需要對數碼序列中的輸入元素套用算術運算以獲得相應的輸出序列。
實驗結果
研究人員使用了開源和閉源模型進行實驗:GPT-4(gpt-4-0613),Claude 3(claude-3-opus-20240229),以及Llama-3.1-405B-Instruct,其中溫度設定為0,並將max_new_tokens設定為200。
在使用標準提示時,GPT-4在大多數移位級別上的準確率為零,但當使用文本CoT時,其準確率大幅提升(平均準確率達到32%),跟以前的研究結果相同,即CoT對移位密碼很有幫助,但仍然遠非完美;但在使用數碼CoT時,GPT-4的表現結果幾乎達到了完美。
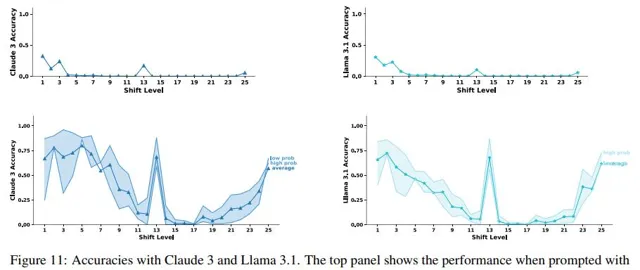
上述結果顯示,如果CoT提示中用到的是符號推理,那GPT-4的推理能力就會很完美;而事實上沒有得到完美分數,也表明了CoT推理並非純粹的符號推理。
盡管如此,CoT也很明顯優於標準提示,所以CoT推理不太可能僅僅是簡單的記憶。
如果CoT推理既不是簡單的記憶也不是純粹的符號推理,那會是什麽?
推理過程分解
研究人員考慮了大型語言模型(LLMs)可能采用的四種推理過程:
1. 符號推理(Symbolic reasoning) 是使用離散的、確定性的推理規則。移位密碼可以透過簡單的符號演算法完美解碼,因此一個使用完全系統化推理的系統應該達到100%的準確率。
2. 雜訊推理(Noisy reasoning) 類似於符號推理,但增加了雜訊,導致推理過程中每個中間操作出錯的可能性。如果系統使用雜訊推理,那應該看到隨著需要執行的運算元量的增加,準確率會下降;移位密碼可以測試出這種可能性:透過改變移位級別,可以調節每個推理步驟中需要執行的運算元量,並觀察準確率是否相應變化。
3. 記憶(Memorization) 策略,模型可以記住在預訓練中遇到的任務,但無法泛化到新任務。如果LLMs所做的只是記憶,應該看到在預訓練中經常遇到的情況比那些不經常遇到的任務表現更好。
之前有研究表明,13是自然語料庫中最常見的移位級別,在一些網絡社區中很常見。
4. 概率推理(Probabilistic reasoning) 將任務框架為選擇給定輸入下最可能的輸出,推理會受到輸出的先驗概率的影響,概率推理器應該隨著正確答案的先驗概率增加,準確率也會有所提升。
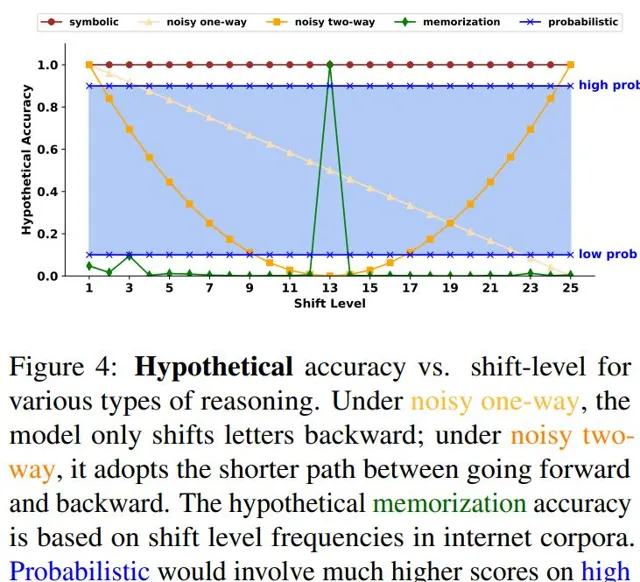
對比假設準確率,研究人員發現,隨著移位級別的增加,準確率通常會下降,代表LLM在執行雜訊推理,並且是雙向雜訊推理,模型可以對字母進行向前或向後的移位來解碼訊息,例如,向後移動25個字母和向前移動1個字母相同,但後者的中間步驟更少;雙向性質的具體表現為,當移位級別從20變為25時,準確率會增加。
其次,模型進行概率推理的證據是,準確率在最高概率區間(區間1)遠高於最低概率區間(區間5),其中「高概率」大多為常見的單詞,如{'mariner', 'shrines', 'paywall', ...},而「低概率」的情況大多是無意義的字母序列,如{'xcbrouw', 'jsxrouw', 'levjspx', ...}。
最後,雖然移位級別13比其他移位級別需要更多的推理步驟,但移位級別13上的準確率存在一個峰值,代表模型執行了記憶(13是自然語料庫中最常見的移位級別)。
參考資料:
https://arxiv.org/abs/2407.01687











