編輯:LRST 好困
【新智元導讀】 復旦大學等機構的研究人員最新提出的AI內容檢測器ImBD涵蓋多工檢測(潤色、擴寫、覆寫、純生成),支持英語、中文、西班牙語、葡萄牙語等多種主流語言;僅需500對樣本、5分鐘訓練時間,就能實作超越商用檢測器!
現如今,大語言模型(LLMs)已經在文本生成領域達到了接近人類水平的能力。
然而,隨著這些模型被廣泛套用於文本創作,其在考試、學術論文等領域的濫用引發了嚴重關註。特別是在當前場景下,使用者往往不是完全依賴AI生成內容,而是利用AI對人類原創內容進行修改和潤色,這種混合型的內容給檢測帶來了前所未有的挑戰。
傳統的機器生成文本檢測方法在辨識純AI生成內容時表現良好,但面對機器修訂文本時常常誤判。這是因為機器修訂文本通常只對原始人類文本做出細微改動,同時包含了大量人類創作的特征和領域專業術語,這使得基於概率統計的傳統檢測方法難以準確辨識。
近期,來自復旦大學、華南理工大學、武漢大學以及 UCSD 、UIUC等機構的研究團隊提出了創新的檢測框架ImBD(Imitate Before Detect),從「模仿」的角度切入:透過先學習和模仿機器的寫作風格特征(如特定詞匯偏好、句式結構等),再基於這些特征進行檢測。

論文地址:https://arxiv.org/abs/2412.10432
專案主頁:https://machine-text-detection.github.io/ImBD
程式碼連結:https://github.com/Jiaqi-Chen-00/ImBD

線上演示: https://ai-detector.fenz.ai/
研究團隊創新性地引入了風格偏好最佳化( style Preference Optimization, SPO),使評分模型能夠精確捕捉機器修訂的細微特征。
實驗表明,該方法在檢測GPT-3.5和GPT-4修改的文本時,準確率分別提升了15.16%和19.68%,僅需1000個樣本和5分鐘訓練就能超越商業檢測系統的效能。該成果已被AAAI2025接收(中稿率23.4%)。
問題背景
隨著大語言模型(LLMs)的快速發展和廣泛套用,AI輔助寫作已經成為一種普遍現象。
然而,這種技術的普及也帶來了新的挑戰,特別是在需要嚴格管控AI使用的領域,如學術寫作、新聞報道等。與傳統的純機器生成文本不同,當前更常見的場景是使用者利用AI對人類原創內容進行修改和潤色,這種混合型的內容使得檢測工作變得異常困難。
如圖1(a-c)所示,相比於人類原創文本和純機器生成文本之間的明顯差異,機器修訂文本往往與原始人類文本只有細微的改動。
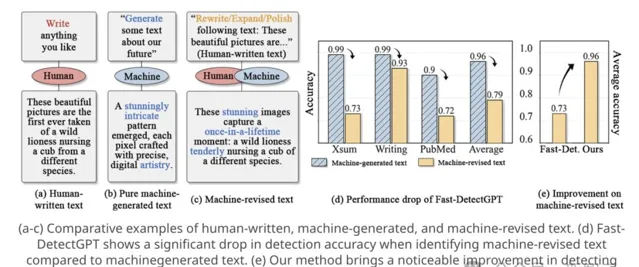
圖1 人類撰寫、機器生成和機器修訂文本的對比分析
傳統的機器生成文本檢測方法主要依賴於預訓練語言模型的token概率分布特征,這些方法假設機器生成的文本通常具有更高的對數似然或負概率曲率。然而,當面對機器修訂文本時,這些方法的效能顯著下降。
如圖1(d)所示,在檢測機器修訂文本時,即使是最先進的Fast-DetectGPT [1]方法也出現了明顯的效能下降。
這種效能降低主要源於兩個方面:
- 首先,機器修訂文本保留了大量人類創作的內容和領域特定術語,這些特征往往會誤導檢測器將文本判定為人類撰寫;
- 其次,隨著GPT-4等新一代語言模型的出現,機器的寫作風格變得更加微妙和難以捕捉。
特別值得註意的是,機器修訂文本的特征往往體現在一些細微的文體特征上。如圖1所示的例子,這些特征包括獨特的詞語選擇(如傾向使用「stunning」、「once-in-a-lifetime」等詞)、復雜的句子結構(如更多的從句使用)以及統一的段落組織方式。
這些風格特征雖然細微,但卻是區分人類原創和機器修訂文本的關鍵線索。然而,由於這些特征往往與人類創作的內容緊密交織,現有的檢測方法難以有效捕捉和利用這些特征,這就導致了檢測準確率的下降。
因此,如何在保留了人類創作內容的文本上準確辨識機器修訂的痕跡,是當前亟待解決的關鍵問題。這不僅關系到學術誠信的維護,也影響著線上資訊的可信度評估。開發一種能夠有效辨識機器修訂文本的檢測方法,對於維護不同領域的內容質素和可信度具有重要意義。
基於風格模仿的機器修改文本檢測框架ImBD
ImBD的核心創新在於將風格感知機制引入機器修改文本檢測領域,首次提出了結合偏好最佳化和風格概率曲線的雙重檢測框架。
不同於傳統方法僅關註內容層面的概率差異,本文透過精確捕捉機器修改文本的風格特征,有效解決了當前檢測方法在處理部份人工內容場景下的局限性。
問題形式化
在機器修改文本檢測任務中,我們將輸入文本表示為標記序列 ,其中n為序列長度。
核心目標是構建一個決策函數 ,透過評分模型 判定文本是人類撰寫(輸出0)還是經過機器修改(輸出1)。這種形式化將復雜的文本分析問題轉化為可處理的二元分類任務。
基礎理論
傳統檢測方法主要基於一個關鍵觀察:機器生成傾向於選擇高概率標記,而人類寫作則展現更多樣的概率分布。這種差異可以透過如下不等式形式化表達:

其中,原始人類文本記為 ,機器修訂的文本記為 ,等式左端表示機器修改文本的對數概率,透過計算在擾動采樣分布 下的期望值來估計;右端則表示人類寫作文本的對數概率及其對應的擾動期望值。這個不等式反映了機器生成文本在擾動後往往出現更顯著的概率下降,而人類寫作文本則保持相對穩定的概率分布特征。
如圖2(左)所示,在純機器生成文本中,這種差異表現得最為明顯。然而,當涉及機器修改文本時,如圖2(右)所展示的,兩類文本的概率分布會出現顯著重疊,導致傳統檢測方法失效。

圖2 基於概率曲線的人機文本區分效果對比圖
偏好最佳化的風格模仿
為克服上述限制,我們提出透過偏好最佳化來增強模型對機器風格的感知能力。如圖3(b)所示,這一機制的核心是構建文本對之間的偏好關系:將原始人類文本與其機器修改版本配對,透過這種配對可以在保持內容一致的同時突出風格差異。
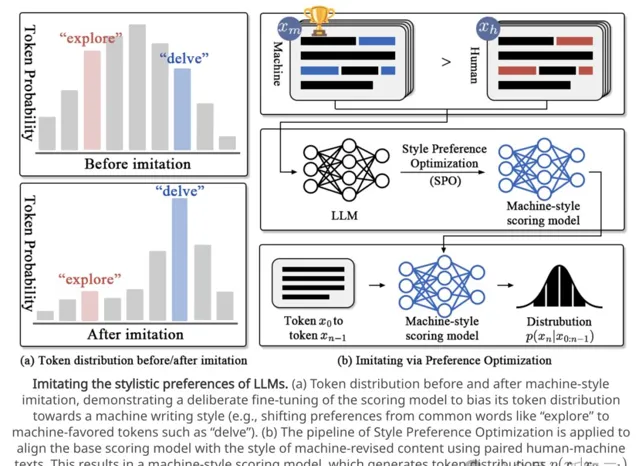
圖3 LLM風格偏好最佳化的模擬過程
基於Bradley-Terry模型,定義偏好分布:
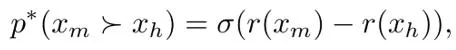
其中,
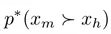 表示偏好機器修改文本而非人類文本的概率,這個概率隨著獎勵差值
的增加而增長。為了實作這一目標,獎勵函數被定義為:
表示偏好機器修改文本而非人類文本的概率,這個概率隨著獎勵差值
的增加而增長。為了實作這一目標,獎勵函數被定義為:

這裏的 代表參考模型(通常是 的初始狀態)。
透過這種獎勵函數的設計,我們用策略模型而非獎勵模型來表達偏好數據的概率。對於一個包含內容等價 對的訓練數據集D,最佳化目標可以表示為:
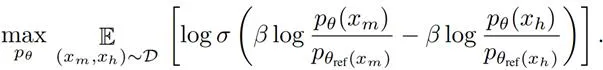
透過最佳化這個目標函數,模型 能夠逐步調整以偏好機器修改文本的風格特征。如圖3(a)所示,這種調整使得模型對機器風格特征(如「delve」這樣的詞)表現出更強的偏好。
最終最佳化後的模型記為 ,代表了一個與機器風格高度對齊的評分模型。
基於風格概率曲線的檢測
在風格對齊的基礎上,研究人員引入風格條件概率曲線( styleconditional probability curvature, style-CPC)作為最終的檢測機制:
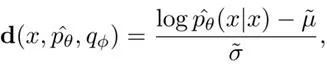
透過這種度量,能夠有效量化文本樣本與機器風格的偏離程度。如圖2對比所示,最佳化後的模型能夠顯著減少人類文本和機器修改文本分布的重疊,最終透過簡單的閾值策略實作準確檢測:
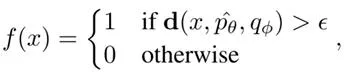
這種基於風格感知的檢測框架不僅提高了對機器修改文本的辨識準確率,更為重要的是,它為解決高級語言模型輸出檢測這一愈發重要的問題提供了新的思路。
透過將註意力從內容轉向風格特征,該方法展現出較強的泛化能力,特別是在處理包含使用者提供內容的復雜場景時表現出明顯優勢。
實驗結果
在GPT系列模型上的檢測效能

在polish任務上,相比Fast-DetectGPT,ImBD在檢測GPT-3.5 [2] 和GPT-4o [3] 修訂的文本時分別提升了15.16%和19.68%的效能;相比有監督模型RoBERTa-large,ImBD在GPT-3.5和GPT-4o的文本檢測上分別提高了32.91%和47.06%的效能。在保持高檢測效能的同時,推理速度仍保持高效,每1000詞僅需0.72秒。

僅使用1000個樣本和5分鐘的SPO訓練,ImBD就達到0.9449的AUROC分數,超過了使用大規模數據訓練的商業檢測工具GPTZero [4] (0.9351)。
在開源模型上的檢測效能

在檢測Qwen2-7B [5] 、Llama-3 [6] 、Mixtral-7B [7] 和Deepseek-7B [8] 四個開源模型修改的文本時,ImBD方法在XSum、SQuAD和WritingPrompts三個數據集上的平均AUROC達到0.9550,顯著優於Fast-DetectGPT的0.8261。
不同任務場景下的檢測魯棒性評估

ImBD方法在rewrite(0.8739)、expand(0.9758)、polish(0.9707)和generate(0.9996)四個任務上全面超越現有方法,平均效能比Fast-DetectGPT提升22.12%,證明了其在不同任務和使用者指令下的穩健性。
消融實驗

與未使用模仿策略的基線模型相比,采用SPO最佳化的ImBD方法在GPT-3.5和GPT-4o的文本檢測上AUROC分別提升了16%和20%;相比使用3倍訓練數據的 SFT (Supervised Fine-Tuning)方法,ImBD的AUROC在GPT-3.5和GPT-4o上分別高出30%和24%。
文本長度敏感性研究

當文本長度從30詞增加到180詞時,ImBD方法始終保持領先優勢,且隨著文本長度增加檢測準確率穩步提升,展現出卓越的長文本處理能力。
多語言檢測能力評估

ImBD在多語言文本檢測中展示出優異的泛化能力,在西班牙語、葡萄牙語和中文的檢測中分別達到0.8487、0.8214和0.8792的AUROC分數,全面超越Fast-DetectGPT等基線方法,且在部份基線方法(如DNA-GPT [9] )失效的中文測試中仍保持穩定效能。
總結
這項工作提出了「模仿後檢測」(Imitate Before Detect)範式來檢測機器修改的文本,其核心是學習模仿LLM的寫作風格。
具體而言,論文提出了風格偏好最佳化方法來使檢測器對齊機器寫作風格,並利用基於風格的條件概率曲率來量化對數概率差異,從而實作有效檢測。透過廣泛的評估實驗,ImBD方法相比現有最先進的方法展現出顯著的效能提升。
作者簡介
論文的主要研究者來自復旦大學、華南理工大學、武漢大學、Fenz.AI以及UCSD、UIUC等機構。

論文一作陳家棋,復旦大學碩士生,史丹福大學存取學生學者。主要研究領域為電腦視覺和智能體。

李祖超,現任武漢大學電腦學院副研究員,在上海交通大學完成博士學位,曾在日本國立資訊通訊技術研究所(NICT)擔任特別技術研究員。

張捷,現任復旦大學類腦智能科學與技術研究院研究員,博士生導師。2008年於香港理工大學獲博士學位。曾獲「香港青年科學家獎」提名獎。為牛津大學「系統建模分析與預測」實驗室榮譽成員。











