前言
每次談到數據庫的事務隔離級別,大家一定會看到這張表。

其中,可重復讀這個隔離級別,有效地防止了臟讀和不可重復讀,但仍然可能發生幻讀,可能發生幻讀就表示可重復讀這個隔離級別防不住幻讀嗎?
我不管從數據庫方面的教科書還是一些網絡教程上,經常看到RR級別是可以重復讀的,但是無法解決幻讀,只有可序列化(Serializable)才能解決幻讀,這個說法是否正確呢?
在這篇文章中,我將重點圍繞MySQL中**可重復讀(Repeatable read)能防住幻讀嗎?**這一問題展開討論,相信看完這篇文章後你一定會對事務隔離級別有新的認識。
我們的數據庫中有如下結構和數據的Users表,下文中我們將對這張表進行操作
長文預警,讀完此篇文章,大概需要您二十至三十分鐘。
什麽是幻讀?
在說幻讀之前,我們要先來了解臟讀和不可重復讀。
臟讀
當一個事務讀取到另外一個事務修改但未送出的數據時,就可能發生臟讀。
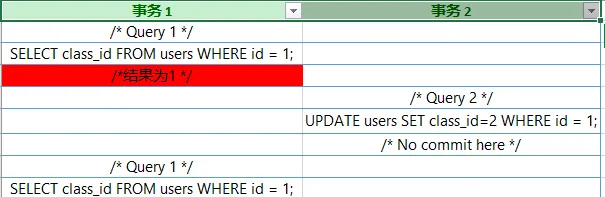
在我們的例子中,事務2修改了一行,但是沒有送出,事務1讀了這個沒有送出的數據。
現在如果事務2回滾了剛才的修改或者做了另外的修改的話,事務1中查到的數據就是不正確的了,所以這條數據就是臟讀。
不可重復讀
「不可重復讀」現象發生在當執行SELECT 操作時沒有獲得讀鎖或者SELECT操作執行完後馬上釋放了讀鎖;另外一個事務對數據進行了更新,讀到了不同的結果。
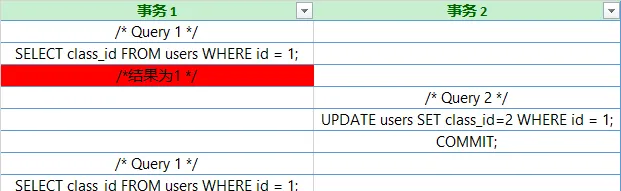
在這個例子中,事務2送出成功,因此他對id為1的行的修改就對其他事務可見了。導致了事務1在此前讀的age=1,第二次讀的age=2,兩次結果不一致,這就是不可重復讀。
幻讀
「幻讀」又叫"幻象讀",是''不可重復讀''的一種特殊場景:當事務1兩次執行''SELECT ... WHERE''檢索一定範圍內數據的操作中間,事務2在這個表中建立了(如[[INSERT]])了一行新數據,這條新數據正好滿足事務1的「WHERE」子句。
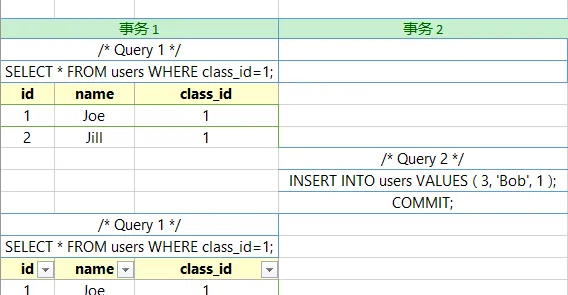
如圖事務1執行了兩遍同樣的查詢語句,第二遍比第一遍多出了一條數據,這就是幻讀。
三者到底什麽區別
三者的場景介紹完,但是一定仍然有很多同學搞不清楚,它們到底有什麽區別,我總結一下。
臟讀 :指讀到了其他事務未送出的數據。
不可重復讀 :讀到了其他事務已送出的數據(update)。
不可重復讀與幻讀都是讀到其他事務已送出的數據,但是它們針對點不同。
不可重復讀:update。
幻讀:delete,insert。
MySQL中的四種事務隔離級別
未送出讀
未送出讀(READ UNCOMMITTED)是最低的隔離級別,在這種隔離級別下,如果一個事務已經開始寫數據,則 另外一個事務則不允許同時進行寫操作 , 但允許其他事務讀此行數據。
把臟讀的圖拿來分析分析,因為事務2更新id=1的數據後,仍然允許事務1讀取該條數據,所以事務1第二次執行查詢,讀到了事務2更新的結果,產生了臟讀。
已送出讀
由於MySQL的InnoDB預設是使用的RR級別,所以我們先要將該session開啟成RC級別,並且設定binlog的模式
SET session transaction isolation level read committed;SET SESSION binlog_format = 'ROW';(或者是MIXED)
在已送出讀(READ COMMITTED)級別中,讀取數據的事務 允許其他事務繼續存取該行數據,但是未送出的寫事務將會禁止其他事務存取該行,會對該寫鎖一直保持直到到事務送出。
同樣,我們來分析臟讀,事務2更新id=1的數據後,在送出前,會對該物件寫鎖,所以事務1讀取id=1的數據時,會一直等待事務2結束,處於阻塞狀態,避免了產生臟讀。
同樣,來分析不可重復讀,事務1讀取id=1的數據後並沒有鎖住該數據,所以事務2能對這條數據進行更新,事務2對更新並送出後,該數據立即生效,所以事務1再次執行同樣的查詢,查詢到的結果便與第一次查到的不同,所以已送出讀防不了不可重復讀。
可重復讀
在可重復讀(REPEATABLE READS)是介於已送出讀和可序列化之間的一種隔離級別(廢話 ),它是InnoDb的預設隔離級別,它是我這篇文章的重點討論物件,所以在這裏我先賣個關子,後面我會詳細介紹。
可序列化
可序列化(Serializable )是高的隔離級別,它求在選定物件上的讀鎖和寫鎖保持直到事務結束後才能釋放,所以能防住上訴所有問題,但因為是序列化的,所以效率較低。

了解到了上訴的一些背景知識後,下面正式開始我們的議題。
可重復讀(Repeatable read)能防住幻讀嗎?
**
**
可重復讀
在講可重復讀之前,我們先在mysql的InnoDB下做下面的實驗。
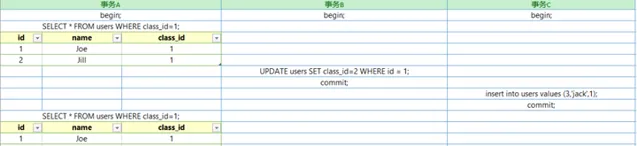
可以看到,事務A既沒有讀到事務B更新的數據,也沒有讀到事務C添加的數據,所以在這個場景下,它既防住了不可重復讀,也防住了幻讀。
到此為止,相信大家已經知道答案了,這是怎麽做到的呢?
悲觀鎖與樂觀鎖
我們前面說的在物件上加鎖,是一種悲觀鎖機制。
有很多文章說可重復讀的隔離級別防不了幻讀,是認為可重復讀會對讀的行加鎖,導致他事務修改不了這條數據,直到事務結束。
但是這種方案只能鎖住數據行,如果有新的數據進來,是阻止不了的,所以會產生幻讀。
可是MySQL、ORACLE、PostgreSQL等已經是非常成熟的數據庫了,怎麽會單純地采用這種如此影響效能的方案呢?

我來介紹一下悲觀鎖和樂觀鎖。
悲觀鎖
正如其名,它指的是對數據被外界(包括本系統當前的其他事務,以及來自外部系統的事務處理)修改持保守態度,因此,在整個數據處理過程中,將數據處於釘選狀態。
讀取數據時給加鎖,其它事務無法修改這些數據。修改刪除數據時也要加鎖,其它事務無法讀取這些數據。
樂觀鎖
相對悲觀鎖而言,樂觀鎖機制采取了更加寬松的加鎖機制。悲觀鎖大多數情況下依靠數據庫的鎖機制實作,以保證操作最大程度的獨占性。
但隨之而來的就是數據庫效能的大量開銷,特別是對長事務而言,這樣的開銷往往無法承受。
而樂觀鎖機制在一定程度上解決了這個問題。樂觀鎖,大多是基於數據版本( Version )記錄機制實作。
何謂數據版本?即為數據增加一個版本標識,在基於數據庫表的版本解決方案中,一般是透過為數據庫表增加一個 「version」 欄位來實作。讀取出數據時,將此版本號一同讀出,之後更新時,對此版本號加一。
此時,將送出數據的版本數據與數據庫表對應記錄的目前版本資訊進行比對,如果送出的數據版本號大於數據庫表目前版本號,則予以更新,否則認為是過期數據。
MySQL、ORACLE、PostgreSQL等都是使用了以樂觀鎖為理論基礎的MVCC(多版本並行控制)來避免不可重復讀和幻讀,MVCC的實作沒有固定的規範,每個數據庫都會有不同的實作方式,這裏討論的是InnoDB的MVCC。
MVCC(多版本並行控制)
在InnoDB中,會在每行數據後添加兩個額外的隱藏的值來實作MVCC,這兩個值一個記錄這行數據何時被建立,另外一個記錄這行數據何時過期(或者被刪除)。
在實際操作中,儲存的並不是時間,而是事務的版本號,每開啟一個新事務,事務的版本號就會遞增。在可重讀Repeatable reads事務隔離級別下:
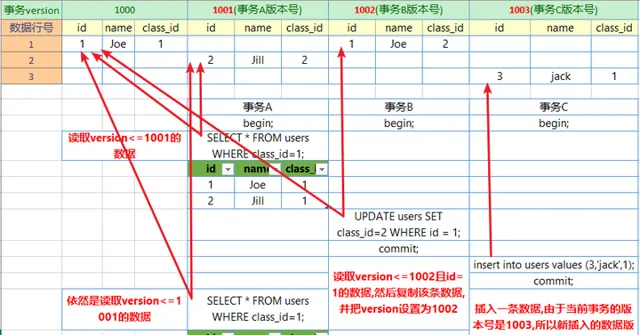
透過MVCC,雖然每行記錄都要額外的儲存空間來記錄version,需要更多的行檢查工作以及一些額外的維護工作,但可以減少鎖的使用,大多讀操作都不用加鎖,讀取數據操作簡單,效能好。
細心的同學應該也看到了,透過MVCC讀取出來的數據其實是歷史數據,而不是最新數據。
這在一些對於數據時效特別敏感的業務中,很可能出問題,這也是MVCC的短板之處,有辦法解決嗎?當然有。
MCVV這種讀取歷史數據的方式稱為快照讀(snapshot read),而讀取數據庫目前版本數據的方式,叫當前讀(current read)。
快照讀
我們平時只用使用select就是快照讀,這樣可以減少加鎖所帶來的開銷。
select * from table ....
當前讀
對於會對數據修改的操作(update、insert、delete)都是采用當前讀的模式。在執行這幾個操作時會讀取最新的記錄,即使是別的事務送出的數據也可以查詢到。
假設要update一條記錄,但是在另一個事務中已經delete掉這條數據並且commit了,如果update就會產生沖突,所以在update的時候需要知道最新的數據。讀取的是最新的數據,需要加鎖。
以下第一個語句需要加共享鎖,其它都需要加排它鎖。
select * from table where ? lock in share mode; select * from table where ? for update; insert; update; delete;
我們再利用當前讀來做試驗。
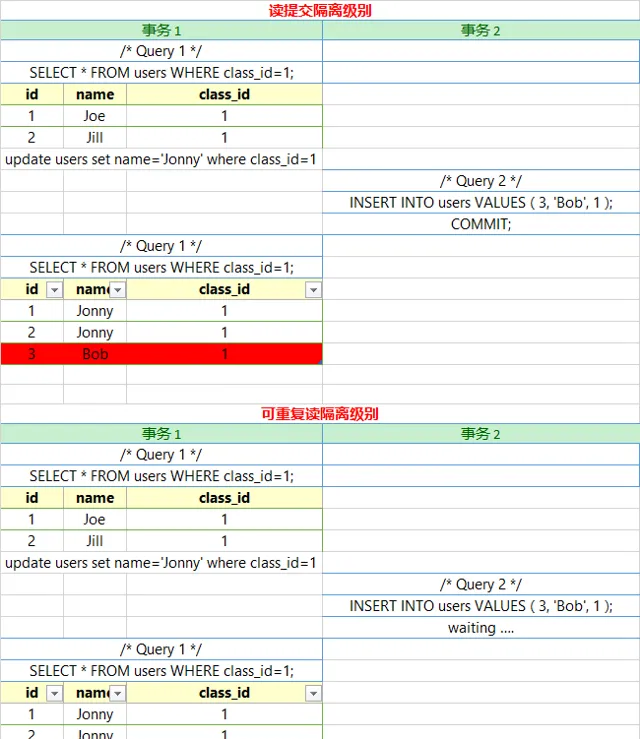
可以看到在讀送出的隔離級別中,事務1修改了所有 class_id=1的數據,當時當事務2 insert後,事務A莫名奇妙地多了一行 class_id=1的數據,而且沒有被之前的update所修改,產生了讀送出下的的幻讀。
而在可重復度的隔離級別下,情況就完全不同了。
事務1在update後,對該數據加鎖,事務B無法插入新的數據,這樣事務A在update前後數據保持一致,避免了幻讀,可以明確的是,update鎖的肯定不只是已查詢到的幾條數據,因為這樣無法阻止insert,有同學會說,那就是鎖住了整張表唄。
還是那句話,Mysql已經是個成熟的數據庫了,怎麽會采用如此低效的方法呢?其實這裏的鎖,是透過next-key鎖實作的。
Next-Key鎖
在Users這張表裏面, class_id是個非聚簇索引,數據庫會透過B+樹維護一個非聚簇索引與主鍵的關系,簡單來說,我們先透過 class_id=1找到這個索引所對應所有節點,這些節點儲存著對應數據的主鍵資訊,即id=1,我們再透過主鍵id=1找到我們要的數據,這個過程稱為回表。
前往學習:https://www. cnblogs.com/sujing/p/11 110292.html
我本想用我們文章中的例子來畫一個B+樹,可是畫得太醜了,為了避免拉低此偏文章B格。所以我想參照上面那邊文章中作者畫的B+樹來解釋Next-key。
假設我們上面用到的User表需要對Name建立非聚簇索引,是怎麽實作的呢?我們看下圖:
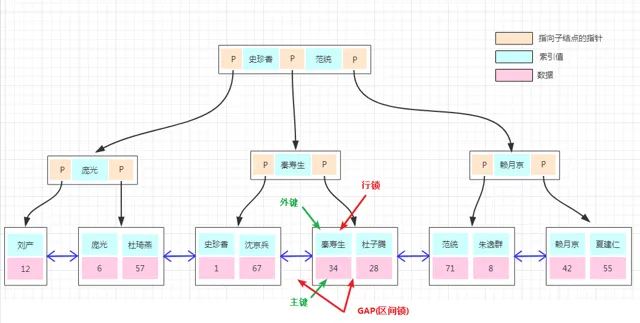
B+樹的特點是所有數據都儲存在葉子節點上,以非聚簇索引的秦壽生為例,在秦壽生的右葉子節點儲存著所有秦壽生對應的Id,即圖中的34。
在我們對這條數據做了當前讀後,就會對這條數據加行鎖,對於行鎖很好理解,能夠防止其他事務對其進行update或delete,但為什麽要加GAP鎖呢?
還是那句話,B+樹的所有數據儲存在葉子節點上,當有一個新的叫秦壽生的數據進來,一定是排在在這條id=34的數據前面或者後面的,我們如果對前後這個範圍進行加鎖了,那當然新的秦壽生就插不進來了。
那如果有一個新的範統要插進行呢?因為範統的前後並沒有被鎖住,是能成功插入的,這樣就極大地提高了數據庫的並行能力。
馬失前蹄
上文中說了可重復讀能防不可重復讀,還能防幻讀,它能防住所有的幻讀嗎?當然不是,也有馬失前蹄的時候。
比如如下的例子:

-
a事務先select,b事務insert確實會加一個gap鎖,但是如果b事務commit,這個gap鎖就會釋放(釋放後a事務可以隨意操作)
-
a事務再select出來的結果在MVCC下還和第一次select一樣
-
接著a事務不加條件地update,這個update會作用在所有行上(包括b事務新加的)
-
a事務再次select就會出現b事務中的新行,並且這個新行已經被update修改了。
Mysql官方給出的幻讀解釋是:只要在一個事務中,第二次select多出了row就算幻讀,所以這個場景下,算出現幻讀了。
那麽文章最後留個問題,你知道為什麽上訴例子會出現幻讀嗎?歡迎留言討論。
參考文章:
來源:http:// cnblogs.com/CoderAyu/p/ 11525408.html











