DolphinDB 集高效能時序數據庫與全面的分析功能為一體,可用於海量結構化數據的儲存、查詢、分析、即時計算等,在工業物聯網場景中套用廣泛。本文以 紐約出租車行程時間預測 為例,介紹如 何使用 DolphinDB 訓練機器學習模型,並進行即時數據的預測 , 為基於智能網聯汽車的車聯網企業提供基於機器學習方法的即時預測方案 。
1. 概要
隨著手機流動應用與網約車平台的迅速發展,網約車出行逐漸成為城市生活中一種重要的出行方式。相較其他出行方式而言,選擇網約車的乘客對出行時效性有更高的要求,本文將基於乘客上車時間及上下車地點等靜態資訊,使用 DolphinDB 機器學習方法訓練模型,預測網約車行程時間。
在此基礎上,本文將介紹如何使用 DolphinDB 流數據處理系統對業務系統產生的持續增長的網約車訂單動態數據進行即時的收集、清洗、統計、入庫,並即時展示行程時間預測結果。
2. 數據介紹
2.1 數據來源及訓練方法
本文訓練和預測采用 Kaggle 提供的來自紐約出租車委員會的數據集,訓練方法參考了獲獎者 beluga 的模型,使用 DolphinDB 對原始數據進行數據預處理,完成位置資訊主成分分析(PCA, Principal Component Analysis)、位置資訊聚類(KMeans)、新特征構建等工作,並使用 DolphinDB XGBoost 外掛程式完成模型訓練及行程時間預測。
為對比 DolphinDB 在機器學習上的效能,本文使用 Python Scikit-Learn 庫及 XGBoost 在同一環境下進行了模型訓練和預測,DolphinDB 在訓練耗時、模型精度等方面均有良好表現。
2.2 數據特征
該數據集預先分為訓練數據集及測試數據集,訓練數據集共包含1458644條數據,測試數據集共包括625134條數據;訓練數據集共包含以下11列資訊。
| 列名 | 列類別 | 說明 | 例項 |
|---|---|---|---|
| id | SYMBOL | 行程的唯一標識 | id2875421 |
| vendor_id | INT | 行程記錄提供商程式碼 | 2 |
| pickup_datetime | DATETIME | 出租車計價器開啟時間 | 2016/3/14 17:24:55 |
| dropoff_datetime | DATETIME | 出租車計價器關閉時間 | 2016/3/14 17:32:30 |
| passenger_count | INT | 乘客數量 | 1 |
| pickup_longitude | DOUBLE | 出租車計價器開啟位置經度 | -73.98215484619139 |
| pickup_latitude | DOUBLE | 出租車計價器開啟位置緯度 | 40.76793670654297 |
| dropoff_longitude | DOUBLE | 出租車計價器關閉位置經度 | -73.96463012695312 |
| dropoff_latitude | DOUBLE | 出租車計價器關閉位置緯度 | 40.765602111816406 |
| store_and_fwd_flag | CHAR | 標識來源是否為儲存的歷史數據 | N |
| trip_duration | INT | 行程時間(按秒計) | 455 |
行程時間預測的目標列為上表中 trip_duration 列,即 dropoff_datetime 與 pickup_datetime 之差。測試數據集用於預測,故其列資訊不包括 dropoff_datetime 及 trip_duration 列,測試數據集中行程標識、位置等列內容同上表。
上表的數據類別中,SYMBOL 類別是 DolphinDB 中一種特殊的字串類別,在系統內部的儲存結構為一個編碼字典,DATETIME 類別為包含了日期和時刻的時間類別。
DolphinDB 支持
loadText
方法讀取 csv 等數據儲存檔到記憶體表,使用者可以
schema
函數獲取表的特征資訊。DolphinDB 也支持使用 SQL 語句完成數據的查詢。
train = loadText("./taxidata/train.csv")
train.schema().colDefs
select count(*) from train
select top 5 * from train
2.3 數據儲存
將數據載入到記憶體表後,可以將訓練數據與測試數據匯入 DolphinDB 數據庫中,便於後續數據的讀取與模型的訓練,數據匯入分布式數據庫的操作詳見 database.md · dolphindb/Tutorials_CN - Gitee。
3. 模型構建
本節介紹行程時間預測模型的構建方法。
行程時間預測模型的構建分多個過程,一是預處理原始數據,對可能存在的空值進行轉換,並將字元等非數值型數據轉換為可用於模型訓練的數值型數據;二是最佳化位置資訊,原始數據中的緯度經度資訊集中在40.70 °N 至40.80 °N 及73.94 °W 至74.02 °W之間,數據間位置特征差異不夠顯著,使用主成分分析、聚類方法處理可以提取到特征更明顯的資訊;三是新特征的構建,位置資訊和時間資訊是訂單數據的兩個關鍵維度,透過計算可以在位置資訊基礎上得到方位、距離資訊,提取更多空間特征,而組合不同類別的位置資訊和時間資訊也可以得到更復雜的特征,有利於模型學習深層次的時空規律。
3.1 數據預處理
在模型訓練過程中,首先需要檢查數據集是否包含空值,本訓練數據集與測試數據集均不包含空值,若存在缺失值,還需要刪除、插補等操作解決缺失數據問題。
其次,需要檢查數據集數據類別,原始數據往往包含文本/字元數據,由1.3節表可知,本數據集中 store_and_fwd_flag 列為字元型數據,pickup_datetime 及 dropoff_datetime 列為日期時間類別數據,為充分利用這些資訊訓練模型,需要將其轉化為數值型數據。
此外,考慮到該數據測試集評價指標為均方根對數誤差(Root Mean Squared Logarithmic Error, RMSLE),同時,最大行程時間接近1000小時,離群值會影響模型訓練效果,對行程時間取對數作為預測值,在評價時(見3.6節)可以直接使用均方根誤差(Root Mean Squared Error, RMSE)指標。

DolphinDB 提供多種計算函數,可以幫助使用者快速實作數據處理。DolphinDB 提供
isNull()
方法用於判斷空值,配合
sum()
等聚合函數使用可以快速完成整表數據的查詢;提供類似於條件運算子的
iif()
方法簡化 if-else 語句;
date()
、
weekday()
、
hour()
等方法可以提取時間、日期數據的不同特征,簡潔高效;類似於 Python 等程式語言,DolphinDB 支持方括弧([])索引,簡化了表的尋找、更新和插入。
sum(isNull(train)) // 0,不含空值
trainData[`store_and_fwd_flag_int] = iif(trainData[`store_and_fwd_flag] == 'N', int(0), int(1)) // 將字元N/Y轉化為0/1值
trainData[`pickup_date] = date(trainData[`pickup_datetime]) // 日期
trainData[`pickup_weekday] = weekday(trainData[`pickup_datetime]) // 星期*
trainData[`pickup_hour] = hour(trainData[`pickup_datetime]) // 小時
trainData[`log_trip_duration] = log(double(trainData[`trip_duration]) + 1)// 對行程時間取對數,log(trip_duration+1)
select max(trip_duration / 3600) from trainData // 訓練集上最大行程時間為979h
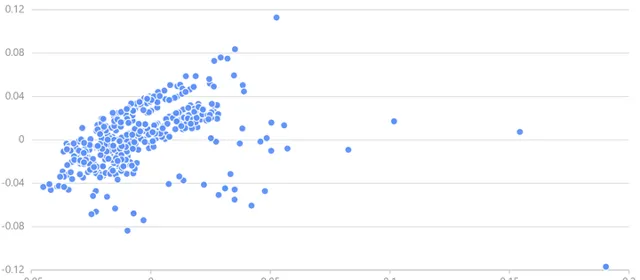
3.2 位置資訊主成分分析(PCA)
原始數據中的緯度經度資訊集中在40.70 °N 至40.80 °N 及73.94 °W 至74.02 °W之間,數據間位置特征差異不夠顯著,使用 PCA 來轉換經度和緯度座標,有助於 XGBoost 決策樹的拆分,DolphinDB PCA 函數使用詳見 pca — DolphinDB 2.0 documentation。
DolphinDB PCA 返回的結果是一個字典,包含 components、explainedVarianceRatio、singularValues 三個鍵,分別代表對應大小為 size(colNames)*k 的主成分分析矩陣、前k個主成分每個特征的變異數貢獻率、主成分變異數(共變異數矩陣特征值)。可透過主成分分析矩陣轉換待處理數據,詳見 Scikit-Learn PCA.transform()。
可從中取若幹數據繪制經度-緯度散點圖觀察 PCA 結果。
經處理,位置座標分散在原點附近。

pca()
接收一個或多個資料來源為參數,對指定列中的數據進行主成分分析,使用者可透過
table()
方法建立記憶體表,用於 PCA;DolphinDB 也提供了
dot()
、
repmat()
等矩陣乘法、矩陣堆疊方法,使用者可使用內建函數快速完成矩陣運算,處理位置資訊。
PCApara = table(trainData[`pickup_latitude] as latitude, trainData[`pickup_longitude] as longitude)
pca_model = pca(sqlDS(<select * from PCApara>)) // 使用PCA計算數據集內容
pca_trainpick = dot((matrix(trainPickPara) - repmat(matrix(avg(trainPickPara)), train_n, 1)), pca_model.components) // transform
trainData[`pca_trainpick_0] = flatten(pca_trainpick[:, 0])
DolphinDB 提供了
plot
函數供數據視覺化。使用者可透過
chartType
指定圖表類別,詳見plot — DolphinDB 2.0 documentation。
x = select top 1000 pca_trainpick_1 from trainData
y = flatten(matrix(select top 1000 pca_trainpick_0 from trainData))
plot(x, y, chartType=SCATTER)
3.3 位置資訊聚類(KMeans)
原始數據位置數據規模龐大,很難挖掘多條數據間的共同特征。KMeans 可以將經緯度相近的數據點歸為同一個簇,有助於更好地歸納組內數據特征。本模型指定要生成的聚類數為100,質心最大叠代次數為100,選擇 KMeans++ 演算法生成模型,DolphinDB kmeans 可選參數及含義詳見 kmeans — DolphinDB 2.0 documentation。
可以使用條形圖觀察聚類後的數據分布。

kmeans()
接收一個表作為訓練集。對於機器學習函數生成的模型,DolphinDB 提供
saveModel
方法將模型保存到本地檔中用於後續預測,使用者可指定伺服器端輸出檔的絕對路徑或相對路徑;DolphinDB 也提供了
predict
方法,呼叫已訓練的特定模型對相同表結構的測試集數據進行預測。
kmeans_set = PCApara[rand(size(PCApara)-1, 500000)] // 隨機選取500000數據用於聚類
kmeans_model = kmeans(kmeans_set, 100, maxIter=100, init='k-means++') // KMeans++
saveModel(kmeans_model, "./taxidata/KMeans.model") // 保存模型訓練結果
trainData['pickup_cluster'] = kmeans_model.predict(select pickup_latitude, pickup_longitude from trainData)
saveModel 和 predict 函數的使用方法可以參考:
3.4 新特征構建
原始數據僅提供了經度及緯度位置資訊,可在此基礎上增加位置特征,如地球表面兩經緯度點之間距離、兩經緯度點之間的 Manhattan 距離、兩個經緯度之間的方位資訊等等。
地球表面兩點間的距離可使用 haversine 公式精確得到,而在本數據集中,網約車實際駛過的往往是水平或豎直的街道所組成的路徑,Manhattan 距離(也稱城市街區距離)標明兩個點在標準座標系上的絕對軸距總和,可能能夠更精確地反映實際的行駛距離。
在此基礎上,考慮到訓練集包含了完整的時間資訊,還可以在訓練集上添加速度特征。訓練集上的速度特征無法直接用於測試集,但在相同的位置聚類內容或相同的時間日期特征下,行程所需時間及平均速度可能存在某些共性(如郊區或淩晨時分網約車車速偏大而城區及早晚高峰時段網約車車速偏小),可以將這種訓練集上發現的經驗套用到測試集上。可將數據按聚類內容或時間特征分組,統計組內數據平均速度等特征,組合生成新特征,合並到測試集的相應分組中。
距離、方位的計算參數不同而方法相同,DolphinDB 支持使用者自訂函數,透過獨立的程式碼模組完成特定的計算任務。而對於不同類別(聚類、時間)內的特征,可使用
groupby
方法在每個分組中計算需要的特征(如平均值)。
groupby
接收三個參數,將根據第三個參數指定的列進行分組,取第一個參數為計算函數,計算第二個參數對應列的特征,並返回行數與分組數相等的表。使用者可透過表連線操作將該組合特征合並入特征數據,本文使用
fj
(full join) 將特征表與 groupby 表合並,
fj()
指定第三個參數為連線列,將前兩個參數所傳入的表合並。
// 兩經緯度點距離、兩個經緯度之間的 Manhattan 距離、兩個經緯度之間的方位資訊
trainData['distance_haversine'] = haversine_array(trainData['pickup_latitude'], trainData['pickup_longitude'], trainData['dropoff_latitude'], trainData['dropoff_longitude'])
trainData['distance_dummy_manhattan'] = dummy_manhattan_distance(trainData['pickup_latitude'], trainData['pickup_longitude'], trainData['dropoff_latitude'], trainData['dropoff_longitude'])
trainData['direction'] = bearing_array(trainData['pickup_latitude'], trainData['pickup_longitude'], trainData['dropoff_latitude'], trainData['dropoff_longitude'])
// 按時間、聚類等資訊處理速度、行程時間,產生新特征
for(gby_col in ['pickup_hour', 'pickup_date', 'pickup_week_hour', 'pickup_cluster', 'dropoff_cluster']) {
for(gby_para in ['avg_speed_h', 'avg_speed_m', 'log_trip_duration']) {
gby = groupby(avg, trainData[gby_para], trainData[gby_col])
gby.rename!(`avg_ + gby_para, gby_para + '_gby_' + gby_col)
trainData = fj(trainData, gby, gby_col)
testData = fj(testData, gby, gby_col)
}
trainData.dropColumns!(`gby + gby_col)
}
3.5 模型訓練(XGBoost)
在進行訓練之前,需要再一次檢查訓練集和測試集的數據,需要剔除 ID、日期、字元等非數值型數據,以及平均速度、行駛時間等僅在訓練集上存在的數據,保證訓練數據與預測數據結構一致。
完成數據處理及特征構建後,可以使用 XGBoost 等機器學習方法訓練模型。為評價模型訓練效果,將訓練數據集劃分為訓練集和驗證集,隨機選取80%的數據作為訓練集訓練模型,使用20%的數據作為驗證集輸出預測結果,使用均方根誤差指標計算驗證集的預測值與真實值的偏差。最終可以在測試集上輸出行程時間的預測結果。
本模型在驗證集上的均方根誤差為0.390,可以繪制預測值-真值散點圖,定性分析模型預測效果。

DolphinDB 提供了 XGBoost 外掛程式實作模型訓練及預測,使用前需要下載外掛程式到指定路徑並載入 XGBoost 外掛程式。DolphinDB XGBoost 外掛程式使用詳見 xgboost/README_CN.md · dolphindb/DolphinDBPlugin - Gitee。
xgb_pars = {'min_child_weight': 50, 'eta': 0.3, 'colsample_bytree': 0.3, 'max_depth': 10,
'subsample': 0.8, 'lambda': 1., 'nthread': 4, 'booster' : 'gbtree', 'silent': 1,
'eval_metric': 'rmse', 'objective': 'reg:linear', 'nthread': 48} // xgb 參數設定
xgbModel = xgboost::train(ytrain, train, xgb_pars, 60) // 訓練模型
yvalid_ = xgboost::predict(xgbModel, valid) // 使用模型進行預測
3.6 模型評價
為實作出租車行程時間的預測,本文使用了三種機器學習方法。首先使用 PCA 對位置資訊進行處理,轉換數據的經緯度特征;使用 KMeans++ 對出租車上下客位置進行聚類,將紐約市區劃分為100個區域進行分析;最後使用 XGBoost 對數據集特征進行訓練。在驗證集上模型均方根誤差為0.390,效果較好。
Python Scikit-Learn 也是主流的機器學習庫之一,本文在相同環境下使用 Python 對同一數據集進行訓練,PCA、KMeans++、XGBoost 訓練耗時如下表所示:
| 模型 | DolphinDB | Python |
|---|---|---|
| PCA | 0.325s | 0.396s |
| KMeans++ | 45.711s | 104.568s |
| XGBoost | 57.269s | 74.289s |
DolphinDB 與 Python 訓練模型在驗證集上誤差如下表所示:
| DolphinDB | Python | |
|---|---|---|
| RMSE | 0.390 | 0.394 |
在本行程時間預測任務中,在準確率上,DolphinDB 與 Python 相近;而在效能上,DolphinDB 在 PCA、KMeans++、XGBoost 上的效能均優於 Python。
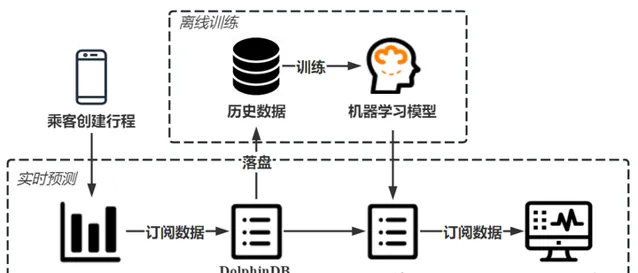
4. 行程時間即時預測
本節結合現實場景,介紹如何使用 DolphinDB 處理即時的訂單流數據,基於預測模型即時估計行程時間。
現實場景中,網約車乘客對時效性要求高,需要平台提供準確的行程時間估計;而服務商也需要監控出行平台,分析出行需求並完成資源排程,僅僅使用預測模型無法高效處理即時數據,難以完成即時預測任務,無法滿足乘客和服務商的即時需求。DolphinDB 流數據模組可以解決生產環境下即時數據的快速分析計算問題,對服務商發送的即時數據,DolphinDB 流數據引擎可高效完成數據預處理、資訊提取、特征構建等工作,使用預先訓練的模型完成即時訂單行程時間的快速準確預測,為使用者提供從模型訓練、流數據註入到即時預測及線上監控的一站式解決方案。

4.1 場景描述
DolphinDB 流數據模組采用釋出-訂閱-消費的模式,流數據首先註入流數據表中,透過流表來釋出數據,第三方套用可以透過 DolphinDB 指令碼或 API 訂閱及消費流數據。
為實作出租車行程時間的即時預測,服務商可以建立 DolphinDB 流數據表訂閱伺服端訊息,獲取乘客建立的行程資訊,使用離線訓練完成的模型對行程時間進行即時預測,最後可透過應用程式訂閱預測數據並提供給乘客。
4.2 即時數據模擬及預測
為獲取行程數據並使用機器學習模型預測行程時間,使用者需要建立三個流表實作即時預測,一是建立訂單資訊表訂閱乘客行程資訊,二是建立特征表完成對訂單資訊的特征提取;三是建立預測表預測特征流數據表發送的行程特征資訊,輸出預測結果。

使用者可以使用 subscribeTable 完成流數據的訂閱,並透過
handler
指定處理訂閱數據的方法(詳見subscribeTable — DolphinDB 2.0 documentation)。在本例中,特征表需訂閱訂單表完成原始資訊的特征提取,本模型定義
process
函數實作;預測表需訂閱特征表使用特征資訊完成行程時間預測,本模型定義
predictDuration
函數實作。函數實作詳見6.2節所附程式碼。
為模擬即時數據,使用 replay 函數回放歷史數據。
// 訂閱訂單資訊表,數據從訂單表流向特征表
subscribeTable(tableName="orderTable", actionName="orderProcess", offset=0, handler=process{traitTable, hisData}, msgAsTable=true, batchSize=1, throttle=1, hash=0, reconnect=true)
// 訂閱特征表,數據從特征表流向預測表
subscribeTable(tableName="traitTable", actionName="predict", offset=0, handler=predictDuration{predictTable}, msgAsTable=true, hash=1, reconnect=true)
// 回放歷史數據,模擬即時產生的生產數據
submitJob("replay", "trade", replay{inputTables=data, outputTables=orderTable, dateColumn=`pickup_datetime, timeColumn=`pickup_datetime, replayRate=25, absoluteRate=true, parallelLevel=1})
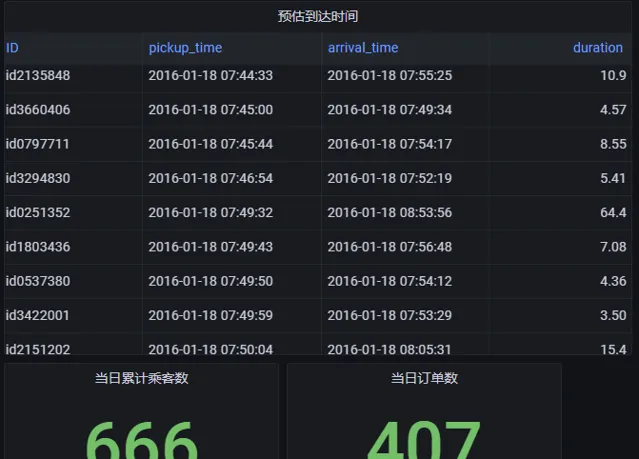
4.3 Grafana 即時監控
服務商可透過第三方 API 連線 DolphinDB 數據庫監控行程時間預測服務,本文以 Grafana 為例簡要介紹如何使用第三方應用程式動態展示即時數據。
Grafana 是一個用於時序數據動態視覺化的數據展示工具,DolphinDB 提供了 Grafana 的數據介面,使用者可在 Grafana 面板上編寫查詢指令碼與 DolphinDB 進行互動,實作 DolphinDB 時序數據的視覺化,並 Web 端進行即時數據分析,詳見 README.zh.md · dolphindb/grafana-datasource - Gitee。
添加 datasource 並新建 dashboard 後,在 Query 中填寫以下 DolphinDB 語句進行即時數據視覺化:
select id as ID, pickup_datetime as pickup_time, (pickup_datetime+int((exp(duration)-1))) as arrival_time, (exp(duration)-1)/60 as duration from predictTable
where date(predictTable.pickup_datetime) == date(select max(pickup_datetime) from predictTable)
select count(*) from predictTable
where date(predictTable.pickup_datetime) == date(select max(pickup_datetime) from predictTable)
select sum(passenger_count) from predictTable
where date(predictTable.pickup_datetime) == date(select max(pickup_datetime) from predictTable)
select pickup_latitude as latitude, pickup_longitude as longitude from predictTable
where date(predictTable.pickup_datetime) == date(select max(pickup_datetime) from predictTable)
select pickup_datetime, (exp(duration)-1)/60 as duration from predictTable
where date(predictTable.pickup_datetime) == date(select max(pickup_datetime) from predictTable)
4.4 數據持久化
如果需要將歷史數據落盤,可以訂閱訂單表中數據,指定
subscribeTable
以
loadTable
的方式將數據持久化到磁盤。
db = database("dfs://taxi")
if(existsTable("dfs://taxi", "newData")) { dropTable(db, "newData") }
db.createPartitionedTable(table=table(1:0, orderTable.schema().colDefs.name, orderTable.schema().colDefs.typeString), tableName=`newData, partitionColumns=`pickup_datetime, sortColumns=`pickup_datetime, compressMethods={datetime:"delta"})
subscribeTable(tableName="orderTable", actionName="saveToDisk", offset=0, handler=loadTable("dfs://taxi", "newData"), msgAsTable=true, batchSize=100000, throttle=1, reconnect=true)
5. 總結
本文介紹了 使用 DolphinDB 機器學習函數及外掛程式訓練出租車行程時間預測模型的方法 ,與 Python Scikit-Learn 等主流機器學習方法相比, DolphinDB 在模型訓練耗時及預測精度上均有良好表現 ;在此基礎上,本文還介紹了 如何使用 DolphinDB 流數據處理工具進行即時預測 ,並 以 Grafana 為例展示了 DolphinDB 時序數據的視覺化方法 。DolphinDB 內建的計算函數和機器學習方法能夠實作從數據儲存、數據載入、數據清洗、特征構造到模型建立、模型評價的完整機器學習流程,可以為物聯網行業使用者提供更全面的數據分析方法。
6. 附錄
6.1 測試環境
6.2 模型程式碼
DolphinDB 模型訓練程式碼:taxiTrain.dos
DolphinDB 流數據預測程式碼: taxiStream.dos
Python 模型訓練程式碼: taxiTrain.py










