
作者/冪律法律部 張麗峰
ChatGPT是由OpenAI在2022年11月30日釋出的對話式通用人工智能工具,甫一問世即成為史上使用者增長速度最快的消費級應用程式,上線僅五天,就突破了百萬使用者;在推出後短短兩個月的時間內,月活使用者就已經突破了一億。今年2月份以來,國內多款大模型產品相繼釋出:MOSS、ChatGLM、文心一言、日日新、通義千問、知海圖AI、天宮3.5、星火……更多的大模型產品也將陸續面世。
當前市面上的大模型產品以「通用大模型」為主,此外也有許多廠商瞄準垂直領域開發大模型產品,如自動駕駛領域的雪湖·海若、金融領域的BloombergGPT等, 冪律也在緊鑼密鼓地研發法律領域的大模型產品。 那麽為什麽有了通用大模型,還需要研發法律大模型呢?本文從法律領域的特殊性出發, 向讀者解釋法律大模型的研發必要性,並探討法律大模型產品研發過程中面臨的挑戰。
一、有了通用大模型為什麽還需要法律大模型?
通用大模型在語言轉譯、文本生成、數學計算等領域都有著不俗的表現,但從法律從業者的試用反饋來看,通用大模型對法律問題的回答效果卻並不理想。究其原因,是由於法律要求高度的專業性和準確性、法律語言具有特殊性、法律存在文化和地域差異,法律行業對大模型產品提出了更高的要求,訓練法律領域的大模型勢在必行。
1.法律的專業性和準確性
大模型通常采用Transformer架構,在此架構下模型被要求根據前面的資訊來預測後面的內容,模型透過計算接下來備選內容的概率選擇後續的輸出。在法律問答任務中,大模型給出的答案實際上是根據使用者的提問推算得出, 故而它可能生成離題、不夠專業或不準確的答案,而法律工作對此類錯誤的容忍度是很低的。
一方面,法律問答通常涉及法律的解釋和適用,法律條文的內容是精準的,需原文參照;基於對法律規範的準確理解,才能提供正確的法律指導。另一方面,法律問題的處理常常關涉人身財產權益, 不準確的回答容易產生誤導,對當事人的決策和行為產生重大影響。
普通民眾的法律知識有限,難以鑒別大模型回答中可能存在的問題,如果每一個回答都需要使用者自行驗證,將與大模型在法律領域提供更加便捷法律服務的初衷相悖。
法律大模型透過高質素的法律數據庫保證專業性,並根據法律領域的特點進行針對性的模型訓練,同時加入提示詞工程,以此提高法律問答的準確性,在常見法律問題上法律大模型通常能給出更準確的回答。
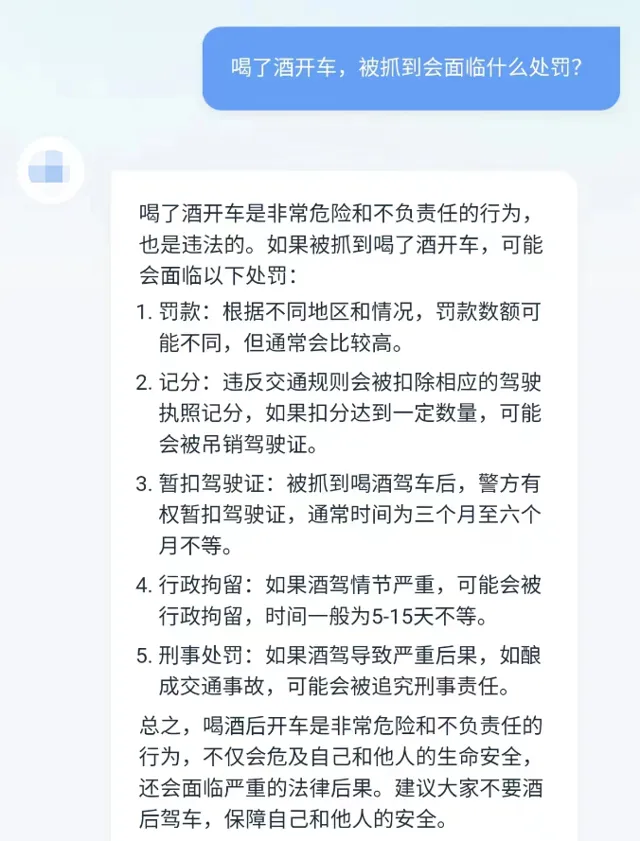

如上圖例是國內某通用聊天機器人和冪律大模型對酒後駕車這一問題的回答。喝了酒開車在法律上區分為酒駕與醉駕兩種情形,法律規定包括【道路交通安全法】第九十一條和【刑法】第一百三十三條之一。酒駕和醉駕面臨的處罰包括暫扣駕駛證、吊銷駕駛證、罰款、拘留以及可能承擔的刑事責任,根據情節不同行為人面臨的具體處罰也會有所不同。
由圖可知,通用聊天機器人雖然能回答出面臨的處罰種類,但答案比較籠統模糊,且未對酒駕與醉駕兩種情節作區分,也未能給出法律依據; 而冪律大模型則區分了酒駕與醉駕兩種情形,針對二者分別列明了具體處罰標準,並給出了準確的法律依據。
2.法律語言的特殊性
法律語言的精確性、特定性和邏輯性使得它與日常生活語言有明顯區別。
法律語言要求準確和專業,需要使用準確的詞匯及特定的表達方式來減少歧義。在法律領域,公民與自然人、居所和住所、營利和盈利、批準與核準、欺詐和詐騙等相似詞匯的適用範圍有著嚴格的界定,以保證準確傳達法律含義。以居所和住所為例,居所指自然人的居住地點,可以是一時的居住地點也可以是長期的居住地點;而住所則指民事主體進行民事活動的中心場所或者主要場所,一般是長期居住、較為固定的居所。
法律語言通常使用專門的術語,如民法上的無因管理、不當得利、刑法上的緊急避險等。專門的術語有助於確保法律條款的一致性和可靠性,並為法律行為和事實提供明確的定義,以便法官、律師和其他法律從業人員準確理解和套用。
此外,法律語言強調邏輯性,通常要求特定的語言結構。法律論證往往透過法律規則、案件事實和法律判斷的司法三段論展開,重視對權利義務的分析,結合法律法規以及相關案例來加強論證的合理性和權威性;法律檔通常采用特定的結構和格式以保證條文清晰、易於解釋和正確理解。
由於法律語言的上述特點,需要有專門的法律數據庫,並且訓練法律大模型。 透過法律文本訓練而成的法律大模型才能具備對法律術語及復雜語言結構的理解和套用能力。
3.法律的文化和地域差異
冪律法律團隊選擇了數百個高頻法律問題,由法律專家整理出答案,之後根據人工解答對比了ChatGPT和冪律大模型在這些問題上的表現。
以下是ChatGPT和冪律大模型對彩禮問題的回答:


關於彩禮的返還,法律規定在雙方未辦理結婚登記手續、雙方辦理結婚登記手續但確未共同生活、婚前給付並導致給付人生活困難這三種情形下返還彩禮的請求通常會被人民法院支持。
在此法律問題上,ChatGPT沒有對能否請求對方返還彩禮進行正面解答,也沒有對彩禮問題從法律角度進行分析並給出相關法律依據; 而冪律法律大模型則對此問題進行了明確回答,對題目進行分析並給出了相關法律依據。
最高人民法院關於適用【中華人民共和國民法典】婚姻家庭編的解釋(一)第五條
當事人請求返還按照習俗給付的彩禮的,如果查明屬於以下情形,人民法院應當予以支持:
(一)雙方未辦理結婚登記手續;
(二)雙方辦理結婚登記手續但確未共同生活;
(三)婚前給付並導致給付人生活困難。
適用前款第二項、第三項的規定,應當以雙方離婚為條件。
ChatGPT通常無法給出具體、直接的法律回答,甚至在一些法律問題上給出「作為AI語言模型,我無法判斷這種情況對你的具體影響……」、「具體情況會因為不同地區和文化背景差異而有所不同」這樣的答案;同時, ChatGPT在回答法律問題時也較少提供準確的中國法律依據。
這種情況可以理解,據Open AI公布,用於訓練ChatGPT的中文語料僅占全部語料的0.09905%,而其中中文法律語料就更少了。此外,國外大模型產品由於所屬法律體系不同、語言轉譯上的誤差等也加劇了ChatGPT對中國法律問題作出準確回答的困難。
因此,為了向使用者提供更優質、更高效的智能法律問答服務,不僅需要研發垂直領域的法律大模型, 更需要研發契合中國法律體系與國情的專業法律大模型。
二、研發法律大模型面臨的具體挑戰
我們期待體驗在法律領域具有強勁實力的法律大模型,但是研發法律大模型面臨著多重挑戰, 這些挑戰涉及模型訓練、法律遵循、數據處理等方面。
1.對模型理解和推理能力的更高要求
法律具有高度的抽象性,法律人需要從生活事實中抽象出法律事實,從日常行為中抽象出法律行為,然後透過推理、論證等方式分析不同的事實和行為對應的法律後果及應對方式。
然而,日常生活中的行為是紛繁復雜的,一種法律行為在生活中可能有多種表現形式。例如,刑法上詐騙指以非法占有為目的,使用欺騙方法,騙取數額較大的公私財物的行為。而在日常生活中,詐騙可能以刷單、殺豬盤、傳銷、兼職、微商代理、裸聊等多種形式出現。以「殺豬盤」為例,這是一種新型網絡電信詐騙方式,當使用者提問涉及遭遇「殺豬盤」時, 模型需要根據「殺豬盤」及其他相關資訊推理出使用者實際是遭遇了詐騙。 之後,模型應根據關於詐騙的法律規定以及使用者的具體情況進行法律推理與論證,最終給出處理結論並提供相關的法律依據。
這對法律大模型的語意理解和推理能力提出了更高的要求。推理能力是目前各種大模型著重提升的能力之一,而如何提高法律大模型在法律領域的理解和推理能力則是研發者必須直面的重要難題。
2.法律的時間效力對訓練數據的影響
法律法規是解決各種法律問題的基礎遵循,但法律是在不斷變動的,社會需求、法律改革、司法實踐的變化都可能會導致法律的新增、修正與廢止。

上圖是截至2023年3月13日十四屆全國人大一次會議閉幕之時,中國現行有效部份法律目錄。由圖可知,諸如【商標法】、【專利法】、【公司法】等法律已經歷了多輪修正,而【民法典】的生效更是導致【民法總則】、【合約法】、【婚姻法】等九部法律及相關立法、司法解釋同時廢止。
「立法者三句修改的話,全部藏書就會變成廢紙。」從訓練法律大模型的角度而言,法律的變動不僅會對作為訓練語料的法律條文範圍及版本產生影響,更深刻影響著作為訓練語料重要組成部份的法學書籍、司法解釋、法律文書以及龐大法律問答數據的準確度與適用性。
以法律問答數據為例,法律的變動會導致數據中存在法律關系變化、法律依據失效、條文序號與最新版法律無法對應等問題。
為了提高模型所需數據的準確性,研發團隊應當密切關註法律法規的變動,及時更新語料,並將法律變動對模型生成法律回答的影響降到最低。
3.數據標註與模型訓練問題
數據質素直接影響到模型的準確性與可靠性。由於法律數據具有復雜性和專業性, 因此法律大模型所需的訓練數據必須由專業的法律人員進行標註。 為了保證標註數據的質素,需要專業、準確的知識架構,並遵循明確的標準及指南以減少標註錯誤和偏差的發生。
標註完成後,研發者應考慮進行多個標註者之間的相互稽核、復審和質素評估,進而發現和糾正錯誤,以提高標註數據的準確性和一致性。
此外,由於法律的復雜性和專業性,法律大模型的訓練將需要更高的時間和計算成本, 並需要透過持續的叠代最佳化以提升準確性。
法律大模型的研發需要 專業基礎紮實的法律專業人士和實力強勁的研發人員通力配合,這是推動法律大模型研發的關鍵因素。 二者應共同致力於解決研發過程中的挑戰和問題,相互交流學習,使法律大模型能夠不斷進步和發展。
4.非典型問題的處理
一些非典型問題,可能是法律尚未覆蓋的新情況,或涉及到復雜的背景資訊、具有行業特殊性、存在區域差異,模型數據難以涵蓋此類特殊情形。例如在引起廣泛討論的「江歌案」中,在危急情形下被救助者是否對救助者負擔安全保障義務這一問題曾被公眾廣泛討論,實務領域、學術界對此問題尚且眾說紛紜,法律大模型作為新事物能夠給出權威結論的可能更是渺茫。
有鑒於此,對於非典型問題法律大模型當前難以提供非常具體、具有針對性的法律意見,此時可以提供一些初步的指導和建議並建議使用者咨詢專業律師。
未來,隨著數據的積累,透過嘗試新的技術方法, 法律大模型有望提高對各類問題的分析處理能力,為使用者提供更智能、高效的法律建議和支持,推動智能法律服務的進一步發展和最佳化。 我們對法律大模型的潛能充滿期待。
ChatGPT等通用大模型產品已經讓我們看到大模型在所涉領域全面性上的驚艷表現,而研發法律大模型,則更讓我們期待大模型在細分垂直領域的無限潛力。從2017年就深耕在「AI+法律」領域的冪律智能,聯合國內新一代認知智能通用模型廠商智譜AI, 即將釋出基於中文千億大模型的「法律ChatGPT」,敬請期待!











