上一篇博文詳細介紹了AlphaGo的核心演算法蒙地卡羅搜尋樹 ,但是還是沒有說明AlphaGo的超強棋力是如何練成的。
我們還是從原文開始,第一代AlphaGo使用了兩個獨立的深度網絡:策略網絡Policy Net和價值網絡Value Net,兩個網絡需要獨立訓練。第二代的AlphaGo Zero以及AlphaZero則使用了更加簡化優雅的網絡架構:統一了深度神經網絡 部份,只是將網絡輸出修改為Policy和Value兩個頭。
對比AlphaGo Lee和AlphaGo Zero兩個版本,只能用一句話來形容:「大道至簡 」。
一、和AlphaGo Lee的區別
| 訓練數據集 | 輸入數據 | 網絡結構 | MCTS搜尋 | |
|---|---|---|---|---|
| AlphaGo Lee | KGS上的16萬個高手棋譜(2940萬手棋)+自我對弈 |
19x19x48個特征面
Feature planes(落子、提子、征子等) |
策略網絡和價值網絡獨立 | 透過MCTS rollout來評估每一步價值 |
| AlphaGo Zero | 490萬局自我對弈 | 19x19x17只使用黑方和白方的落子作為輸入數據 | 統一的策略+價值網絡 | 不需要rollout,只用策略網絡的價值 |

二、網絡架構
AlphaGo Zero的策略網絡分為三個部份:輸入層、多個殘留誤差網絡 block、雙頭輸出層()
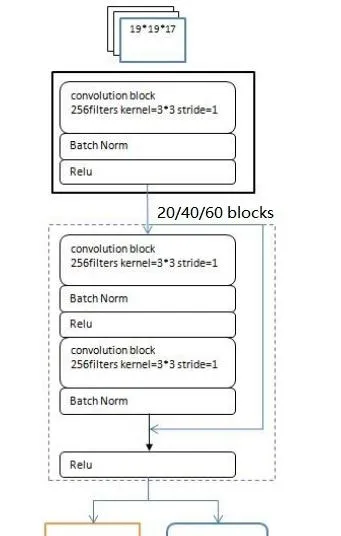
1、輸入層
AlphaZero策略網絡 的輸入封包含了黑白雙方過去8手的落子,以及當前落子的顏色。數據格式為19x19x17: s_{t}=[X_{t}, Y_{t}, X_{t-1}, Y_{t-1}, ..., X_{t-7}, Y_{t-7}, C]
其中C是當前棋手X的落子顏色(黑色為1,白色為2), X_{t} 是當前棋手X的所有落子, Y_{t} 是對方棋手Y的所有落子。 X_{t-1} 是棋手X在上一手時的所有落子,以此類推。
2、摺積Blocks
為了學會非常復雜的圍棋棋形,需要相當深度的神經網絡,AlphaGo Zero設計了基於CNN和Residual殘留誤差網絡的Residual blocks結構,每個block的組成為:
(1)摺積網絡Conv2D( filters=256, kernel_size=(3,3), stride=1, padding=0);
(2)正則化層Batch normalisztion;
(3)relu非線性啟用函數
(4)摺積網絡Conv2D( filters=256, kernel_size=(3,3), stride=1, padding=0);
(5)正則化層Batch normalisztion;
(6)殘留誤差連線 (skip connection)
(7)relu
3、輸出頭
網絡有兩個輸出頭:
Policy Output:
(1)Conv2D(filters=2, kernel_size=(1,1), stride=1, padding=0);
(2)正則化層Batch normalisztion;
(3)relu
(4)全連線輸出層 size=362,19*19 + 1,表示361種落子以及pass的概率
Value O











