如何利用計算中心成千上百的AI加速芯片的集群,訓練參數量超過百億的大規模模型?平行計算是一種行之有效的方法,除了分布式平行計算相關的技術之外,其實在訓練大模型的過程還會融合更多的技術,如新的演算法模型架構和記憶體/計算最佳化技術等。
這篇文章梳理我們在大模型訓練中使用到的相關技術點,主要分為三個方面來回顧現階段使用多AI加速芯片訓練大模型的主流方法。
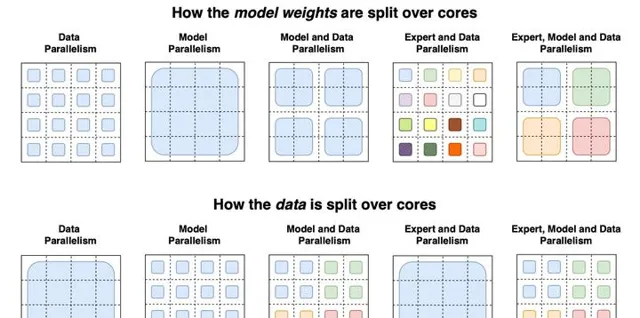
1. **分布式並列加速:** 並列訓練主要分為數據並列、模型並列、流水線並列、張量並列四種並列方式,透過上述四種主要的分布式並列策略來作為大模型訓練並列的主要策略。
2. **演算法模型架構:** 大模型訓練離不開Transformer網絡模型結構的提出,後來到了萬億級稀疏場景中經常遇到專家混合模型MoE都是大模型離不開的新演算法模型結構。
3. **記憶體和計算最佳化:** 關於記憶體最佳化技術主要由啟用Activation重計算、記憶體高效的最佳化器、模型壓縮,而計算最佳化則集中體現在混合精度訓練、算子融合、梯度累加等技術上。
大模型訓練的目標公式
超大模型訓練的總體目標就是提升總的訓練速度,減少大模型的訓練時間,你知道啦,畢竟訓練一個大模型基本上從按下回車的那一刻開始要1到2個月,是很蛋疼的。下面主要看一下在大模型訓練中的總訓練速度的公式:
總訓練速度 ∝ 單卡速度 * 加速芯片數量 * 多卡加速比上面公式當中,單卡速度主要由單塊AI加速芯片的運算速度、數據IO來決定;而加速芯片數量這個很清楚,數量越多增加訓練速度;而多卡加速比則是有計算和通訊效率決定。
我們再把使用到技術跟這個公式關聯在一起:
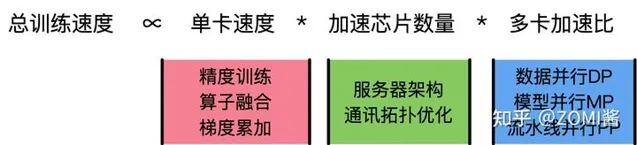
1、單卡速度 :單卡速度既然是運算速度和數據IO的快慢來決定,那麽就需要對單卡訓練進行最佳化,於是主要的技術手段有精度訓練、算子融合、梯度累加來加快單卡的訓練效能。
2、加速芯片數量 :理論上,AI芯片數量越多,模型訓練越快。但是,隨著訓練數據集規模的進一步增長,加速比的增長並不明顯。如數據並列就會出現局限性,當訓練資源擴大到一定規模時,由於通訊瓶頸的存在,增加計算資源的邊際效應並明顯,甚至增加資源也沒辦法進行加速。這時候需要通訊拓撲進行最佳化,例如透過ring-all-reduce的通訊方式來最佳化訓練模式。
3、多卡加速比 :多卡加速比既然由計算、通訊效率決定,那麽就需要結合演算法和集群中的網絡拓撲一起最佳化,於是有了數據並列DP、模型並列MP、流水線並列PP相互結合的多維度混合並列策略,來增加多卡訓練的效率。
總的來說呢,超大模型訓練的目標就是最佳化上面的公式,提升總訓練速度。核心思想是將數據和計算有關的圖/算子切分到不同器材上,同時盡可能降低器材間通訊所需的代價,合理使用多台器材的計算資源,實作高效的並行排程訓練,最大化提升訓練速度。
大模型訓練的集群架構
這裏的集群架構是為了機器學習模型的分布式訓練問題。深度學習的大模型目前主要是在集群中才能訓練出來啦,而集群的架構也需要根據分布式並列、深度學習、大模型訓練的技術來進行合理安排。
在2012年左右Spark采取了簡單直觀的數據並列的方法解決模型並列訓練的問題,但由於Spark的並列梯度下降方法是同步阻斷式的,且模型參數需透過全域廣播的形式發送到各節點,因此Spark的並列梯度下降是相對低效的。
2014年李沐提出了分布式可延伸的Parameter Server架構,很好地解決了機器學習模型的分布式訓練問題。Parameter Server不僅被直接套用在各大公司的機器學習平台上,而且也被整合在TensorFlow,Pytroch、MindSpore、PaddlePaddle等主流的深度框架中,作為機器學習分布式訓練最重要的解決方案之一。
目前最流行的模式有兩種:
1. 參數伺服器模式(Parameter Server,PS)
2. 集合通訊模式(Collective Communication,CC)
其中參數伺服器主要是有一個或者多個中心節點,這些節點稱為PS節點,用於聚合參數和管理模型參數。而集合通訊則沒有管理模型參數的中心節點,每個節點都是 Worker,每個Worker負責模型訓練的同時,還需要掌握當前最新的全域梯度資訊。
參數伺服器模式
參數伺服器架構Parameter Server,PS架構包括兩個部份,首先是把計算資源分為兩個部份,參數伺服器節點和工作節點:1)參數伺服器節點用來儲存參數;2)工作節點部份用來做演算法的訓練。
第二個部份就是把機器學習演算法也分成兩個方面,即1)參數和2)訓練。
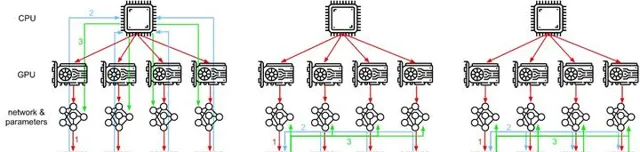
如圖所示,PS架構將計算節點分為server與worker,其中,worker用於執行網絡模型的前向與反向計算。而server則對各個worker發回的梯度進行合並並更新模型參數,對深度學習模型參數中心化管理的方式,非常易於儲存超大規模模型參數。
但是隨著模型網絡越來越復雜,對算力要求越來越高,在數據量不變的情況下,單個GPU的計算時間是有差異的,並且網絡頻寬之間並不平衡,會存在部份GPU計算得比較快,部份GPU計算得比較慢。這個時候如果使用異步更新網絡模型的參數,會導致最佳化器相關的參數更新出現錯亂。而使用同步更新則會出現阻塞等待網絡參數同步的問題。
GPU 強大的算力毋庸置疑可以提升集群的計算效能,但隨之而來的是,不僅模型規模會受到機器視訊記憶體和記憶體的制約,而且通訊頻寬也會由於集群網卡數量降低而成為瓶頸。
這個時候百度基於PS架構之上提出了Ring-All-Reduce新的通訊架構方式。
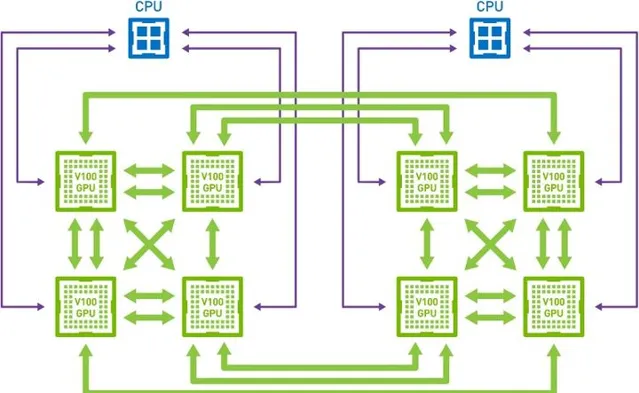
如圖所示,透過異步流水線執行機制,隱蔽了 IO 帶來的額外效能開銷,在保證訓練速度的同時,使訓練的模型大小不再受制於視訊記憶體和記憶體,極大提升模型的規模。而 RPC&NCCL 混合通訊策略可以將部份稀疏參數采用 RPC 協定跨節點通訊,其余參數采用卡間 NCCL 方式完成通訊,充分利用頻寬資源。
集合通訊模式
大模型訓練相關論文
2022年學習大模型、分布式深度學習,不可能錯過的AI論文,你都讀過了嗎?根據句上面的介紹,我們將會分為分布式並列策略相關的論文、分布式框架相關的論文、通訊頻寬最佳化相關的論文等不同的維度對論文進行整理。並給出一個簡單的解讀,希望大家可以一起去分享好的思想。
分布式並列策略相關
數據並列(Data Parallel,DP) :數據並列訓練加速比最高,但要求每個器材上都備份一份模型,視訊記憶體占用比較高。
模型並列(Model Parallel,MP) :模型並列,通訊占比高,適合在機器內做模型並列且支持的模型類別有限。
流水線並列(Pipeline Parallel,PP) :流水線並列,訓練器材容易出現空閑狀態,加速效率沒有數據並列高;但能減少通訊邊界支持更多的層數,適合在機器間使用。
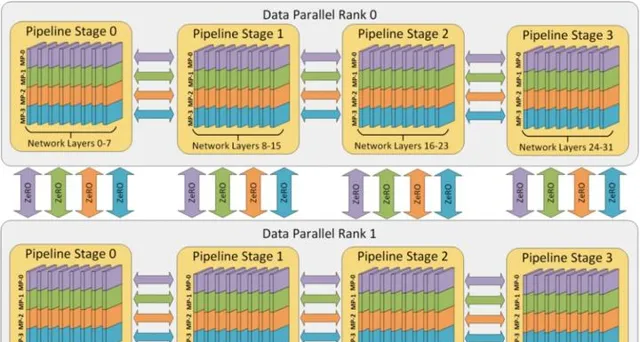
混合並列(Hybrid parallel,HP) :混合並列策略的思想,集三種策略的優勢於一身,實作取長補短。具體來說,先在單機內使用模型並列和分組參數切片組合的策略,這麽選擇的原因是這兩個策略通訊量較大,適合使用機器內的卡間通訊。接著,為了承載千億規模大模型,疊加流水線並列策略,使用多台機器共同分擔計算。最後,為了計算和通訊高效,在外層又疊加了數據並列來增加並行數量,提升整體訓練速度。這就是我們目前在AI框架中添加的並列策略,業界基本上都是使用這種方式。

**並列相關的論文**
下面就是並列相關的經典推薦論文,首先就是Jeff Dean在2012年的開創文章,然後介紹Facebook Pytroch裏面使用到的數據並列中DDP、FSDP的策略。然而這並不夠,因為有多重並列策略,於是NVIDIA推出了基於GPU的數據、模型、流水線並列的比較綜述文章。實際上流水線並列會引入大量的伺服器空載buffer,於是Google和微軟分別針對流水線並列最佳化推出了GPipe和PipeDream。最後便是NVIDIA針對自家的大模型Megatron,推出的模型並列涉及到的相關策略。
- Large Scale Distributed Deep Networks
2012年的神作,要知道那個時候神經網絡都不多,這是出自於Google大神Jeff Dean的文章。主要是神經網絡進行模型劃分,因為推出得比較早,所以會稍微Naitve一點,但是作為分布式並列的開創之作,稍微推薦一下。
- Getting Started with Distributed Data Parallel
- PyTorch Distributed: Experiences on Accelerating Data Parallel Training.
Facebook為Pytorch打造的分布式數據並列策略演算法 Distributed Data Parallel (DDP)。與 Data Parallel 的單行程控制多 GPU 不同,在 distributed 的幫助下,只需要編寫一份程式碼,torch 就會自動將其分配給n個行程,分別在 n 個 GPU 上執行。不再有主 GPU,每個 GPU 執行相同的任務。對每個 GPU 的訓練都是在自己的過程中進行的。每個行程都從磁盤載入其自己的數據。分布式數據采樣器可確保載入的數據在各個行程之間不重疊。損失函數的前向傳播和計算在每個 GPU 上獨立執行。因此,不需要收集網絡輸出。在反向傳播期間,梯度下降在所有GPU上均被執行,從而確保每個 GPU 在反向傳播結束時最終得到平均梯度的相同副本。
- Fully Sharded Data Parallel: faster AI training with fewer GPUs
Facebook釋出的FSDP(Fully Sharded Data Parallel),對標微軟在DeepSpeed中提出的ZeRO,FSDP可以看成PyTorch中的DDP最佳化版本,本身也是數據並列,但是和DDP不同的是,FSDP采用了parameter sharding,所謂的parameter sharding就是將模型參數也切分到各個GPUs上,而DDP每個GPU都要保存一份parameter,FSDP可以實作更好的訓練效率(速度和視訊記憶體使用)。
- Efficient Large-Scale Language Model Training on GPU Clusters
很好的一篇綜述出品與NVIDIA,論文中, NVIDIA 介紹了分布式訓練超大規模模型的三種必須的並列技術:數據並列(Data Parallelism)、模型並列(Tensor Model Parallelism)和流水並列(Pipeline Model Parallelism)。
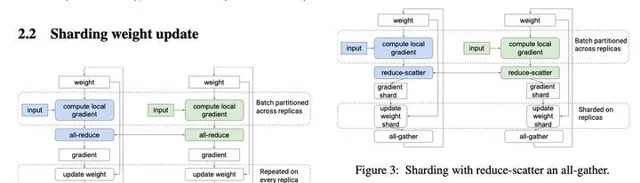
- Automatic Cross-Replica Sharding of Weight Update in Data-Parallel Training
在傳統的數據並列中,模型參數被復制並在每次訓練迴圈結束後被最佳化器更新。然而,當每個核的批次數不夠大的時候,計算或許會變成一個瓶頸。例如,以MLPerf的BERT訓練為例,在512個第三代TPU芯片上,LAMB最佳化器的參數更新時間可以占到整個迴圈時間的18%。Xu等人在2020年提出了參數更新劃分技術,這種分布式計算技術首先執行一個reduce-scatter操作,然後使得每個加速器有整合梯度的一部份。這樣每個加速器就可以算出相應的被更新的局部參數。在下一步,每個被更新的局部參數被全域廣播到各個加速器,這樣使得每個加速器上都有被更新的全域參數。為了獲得更高的加速比,同時用數據並列和模型並列去處理參數更新劃分。在影像分割模型中,參數是被復制的,這種情況下參數更新劃分類似於數據並列。然後,當參數被分布後到不同的核之後,就執行多個並行的參數更新劃分。
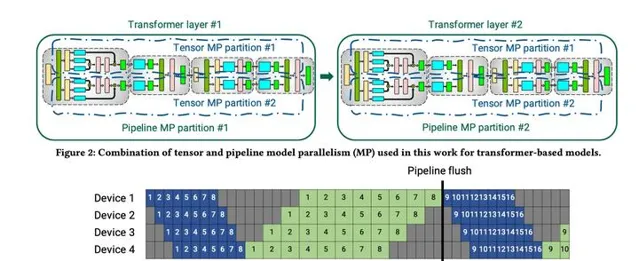
- PipeDream: Fast and Efficient Pipeline Parallel DNN Training
微軟研究院宣布了Fiddle專案的創立,其包括了一系列的旨在簡化分布式深度學習的研究專案。PipeDreams是Fiddle釋出的第一個側重於深度學習模型並列訓練的專案之一。其主要采用「流水線並列」的技術來擴充套件深度學習模型的訓練。在 PipeDream 中主要克服流水線並列化訓練的挑戰,演算法流程主要如下。首先,PipeDream 必須在不同的輸入數據間,協調雙向流水線的工作。然後,PipeDream 必須管理後向通道裏的權重版本,從而在數值上能夠正確計算梯度,並且在後向通道裏使用的權重版本必須和前向通道裏使用的相同。最後,PipeDream 需要流水線裏的所有 stage 都花費大致相同的計算時間,這是為了使流水線得到最大的通量。
- GPipe: Easy Scaling with Micro-Batch Pipeline Parallelism
GPipe是Google發明的論文,專註於透過流水線並列擴充套件深度學習應用程式的訓練負載。GPipe 把一個L層的網絡,切分成 K個 composite layers。每個composite layer 執行在單獨的TPU core上。這K個 core composite layers只能順序執行,但是GPipe引入了流水並列策略來緩解這個順序執行的效能問題,把 mini-batch細分為多個更小的macro-batch,提高並列程度。GPipe 還用recomputation這個簡單有效的技巧來降低記憶體,進一步允許訓練更大的模型。
- Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism.
- Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM.
出自NVIDIA,雖然這兩篇文章都是在講Megatron網絡模型,實際上裏面展開的都是模型並列等多維度並列的相關的技術點。其中第一篇論文共有兩個主要的結論:1,利用數據和模型並列的分布式技術訓練了具有3.9B參數的BERT-large模型,在GLUE的很多數據集上都取得了SOTA成績。同時,還訓練了具有8.3B參數的GPT-2語言模型,並在數據集Wikitext103,LAMBADA,RACE都上取得SOTA成績。這篇論文,一方面體現了算力的重要性,另一方面體現了模型並列和數據並列技術關鍵性。這兩項最佳化技術在加速模型訓練和推斷過程中至關重要。
大模型演算法相關
**必須了解的基礎大模型結構**
基礎大模型結構基本上都是由Google貢獻的,首先要看17年只需要Attention替代RNN序列結構,於是出現了第四種深度學習的架構Transformer。有了Transformer的基礎架構後,在18年推出了BERT預訓練模型,之後的所有大模型都是基於Transformer結構和BERT的預訓練機制。後面比較有意思的就是使用Transformer機制的視覺大模型ViT和引入專家決策機制的MoE。
- Attention is all you need.
Google首創的Transformer大模型,是現在所有大模型最基礎的架構,現在Transformer已經成為除了MLP、CNN、RNN以外第四種最重要的深度學習演算法架構。谷歌在arxiv發了一篇論文名字教Attention Is All You Need,提出了一個只基於attention的結構來處理序列模型相關的問題,比如機器轉譯。傳統的神經機器轉譯大都是利用RNN或者CNN來作為encoder-decoder的模型基礎,而谷歌最新的只基於Attention的Transformer模型摒棄了固有的定式,並沒有用任何CNN或者RNN的結構。該模型可以高度並列地工作,所以在提升轉譯效能的同時訓練速度也特別快。
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Google釋出的首個預訓練大模型BERT,從而引爆了預訓練大模型的潮流和趨勢,這個不用介紹大家肯定有所聽聞啦。BERT的全稱為Bidirectional Encoder Representation from Transformers,是一個預訓練的語言表征模型。它強調了不再像以往一樣采用傳統的單向語言模型或者把兩個單向語言模型進行淺層拼接的方法進行預訓練,而是采用新的masked language model(MLM),以致能生成深度的雙向語言表征。BERT論文發表時提及在11個NLP(Natural Language Processing,自然語言處理)任務中獲得了新的state-of-the-art的結果,令人目瞪口呆。
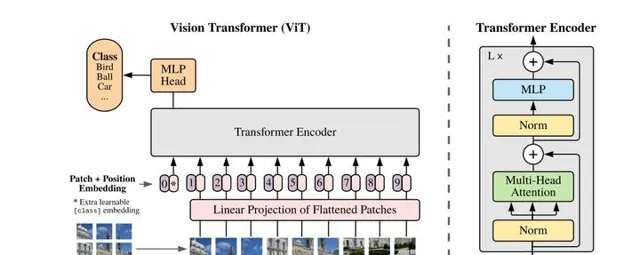
- An Image is Worth 16x16 Words: transformer for Image Recognition at Scale
ViT Google提出的首個使用Transformer的視覺大模型,基本上大模型的創新演算法都是出自於Google,不得不服。ViT作為視覺轉換器的使用,而不是CNN或混合方法來執行影像任務。結果是有希望的但並不完整,因為因為除了分類之外的基於視覺的任務:如檢測和分割,還沒有表現出來。此外,與Vaswani等人(2017年)不同,與CNN相比,transformer 效能的提升受到的限制要大得多。作者假設進一步的預訓練可以提高效能,因為與其他現有技術模型相比,ViT具有相對可延伸性。
- GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding.
好像G開頭的模型都是Google的了一樣魔性。在 ICLR 2021 上,Google 的進一步將 MoE 套用到了基於 Transformer 的神經機器轉譯的任務上。GShard 將 Transformer 中的 Feedforward Network(FFN)層替換成了 MoE 層,並且將 MoE 層和數據並列巧妙地結合起來。在數據並列訓練時,模型在訓練集群中已經被復制了若幹份。GShard 透過將每路數據並列的 FFN 看成 MoE 中的一個專家來實作 MoE 層,這樣的設計透過在多路數據並列中引入 All-to-All 通訊來實作 MoE 的功能。
**具有裏程碑意義性的大模型**
- GPT-3: Language Models are Few-Shot Learners
OpenAI釋出的首個百億規模的大模型,應該非常具有開創性意義,現在的大模型都是對標GPT-3。GPT-3依舊延續自己的單向語言模型訓練方式,只不過這次把模型尺寸增大到了1750億,並且使用45TB數據進行訓練。同時,GPT-3主要聚焦於更通用的NLP模型,解決當前BERT類模型的兩個缺點:對領域內有標簽數據的過分依賴:雖然有了預訓練+精調的兩段式框架,但還是少不了一定量的領域標註數據,否則很難取得不錯的效果,而標註數據的成本又是很高的。對於領域數據分布的過擬合:在精調階段,因為領域數據有限,模型只能擬合訓練數據分布,如果數據較少的話就可能造成過擬合,致使模型的泛華能力下降,更加無法套用到其他領域。
- T5: Text-To-Text Transfer Transformer
Google把T5簡單的說就是將所有 NLP 任務都轉化成Text-to-Text(文本到文本)任務。對於T5這篇論文,很Google的一篇文章啦,讓我也很無力,畢竟財大氣粗之外,還有想法,這就是高富帥。回到論文本身,T5意義不在燒了多少錢,也不在屠了多少榜,其中idea創新也不大,它最重要作用是給整個NLP預訓練模型領域提供了一個通用框架,把所有任務都轉化成一種形式
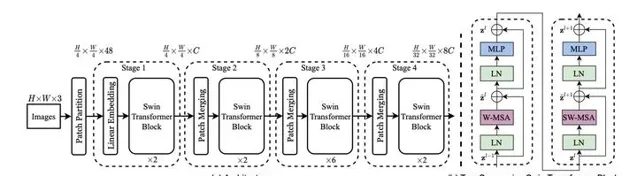
- Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
微軟亞研提出的Swin Transformer的新型視覺Transformer,它可以用作電腦視覺的通用backbone。在兩個領域之間的差異,例如視覺實體尺度的巨大差異以及與文字中的單詞相比,影像中像素的高分辨率,帶來了使Transformer從語言適應視覺方面的挑戰。
**超過萬億規模的稀疏大模型**
- Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts.
Google釋出的多工MoE。多工學習的目的在於用一個模型來同時學習多個目標和任務,但常用的任務模型的預測質素通常對任務之間的關系很敏感(數據分布不同,ESMM 解決的也是這個問題),因此,google 提出多門混合專家演算法(Multi-gate Mixture-of-Experts)旨在學習如何從數據中權衡任務目標(task-specific objectives)和任務之間(inter-task relationships)的關系。所有任務之間共享混合專家結構(MoE)的子模型來適應多工學習,同時還擁有可訓練的門控網路(Gating Network)以最佳化每一個任務。
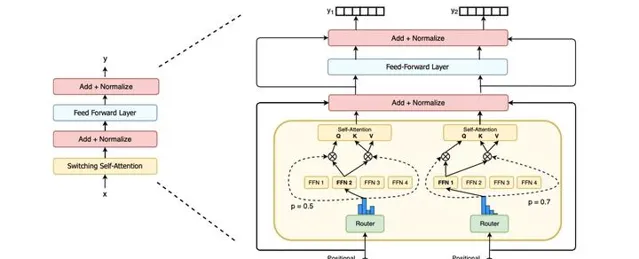
- Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.
Google重磅推出首個萬億參數的超大規模稀疏語言模型Switch Transformer。 聲稱他們能夠訓練包含超過一萬億個參數的語言模型的技術。直接將參數量從GPT-3的1750億拉高到1.6萬億,其速度是Google以前開發的語言模型T5-XXL的4倍。
記憶體和計算最佳化
最後就是最佳化方面的,其中主要是並列最佳化器、模型壓縮量化、記憶體復用最佳化、混合精度訓練等方面的最佳化,下面各列了幾個最經典的文章。
- Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
一篇17年關於最佳化器的老文章,文章的一個重要的結論很簡單,就是一個線性縮放原則,但裏面分析的不錯,講到了深度學習中很多基本知識的一個理解。本文從實驗的角度進行細致的分析。雖然文章分析的是如何在更大的batch上進行訓練,但同樣的道理本文也可以用在像我一樣的貧民黨,當我們沒有足夠的GPU或者視訊記憶體不足的時候到底該怎麽調節一些參數。
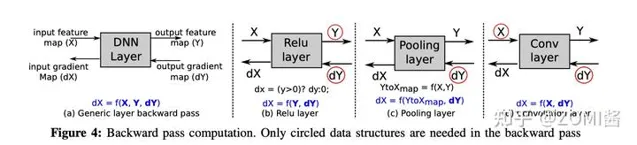
啟用重計算。
記憶體最佳化相關論文:
- Training Deep Nets with Sublinear Memory Cost.
陳天奇這個名字可能圈內人都會比較熟悉了,在2016年的時候提出的,主要是對神經網絡做記憶體復用。這篇文章提出了一種減少深度神經網絡訓練時記憶體消耗的系統性方法。主要關註於減少儲存中間結果(特征對映)和梯度的記憶體成本,因為在許多常見深度架構中,與中間特征對映的大小相比,參數的大小相對較小。使用計算圖分析來執行自動原地操作和記憶體共享最佳化。更重要的是,還提出了一種新的以計算交換記憶體的方法。
- Gist: Efficient data encoding for deep neural network training
Gist是ISCA'18的一篇頂會文章,不算是新文章了,但是參照量在系統文章中算是非常高的,看完之後發現實驗果然紮實,值得學習。主要思想還是圍繞如何降低神經網絡訓練時候的視訊記憶體使用量。Gist面向資料壓縮,發掘訓練模式以及各個層數據的特征,對特定數據進行不同方案的壓縮,從而達到節省空間的目的。
- Adafactor: Adaptive learning rates with sublinear memory cost.
AdaFactor,一個由Google提出來的新型最佳化器,AdaFactor具有自適應學習率的特性,但比RMSProp還要省視訊記憶體,並且還針對性地解決了Adam的一些缺陷。說實話,AdaFactor針對Adam所做的分析相當經典,值得我們認真琢磨體味,對有興趣研究最佳化問題的讀者來說,更是一個不可多得的分析案例。
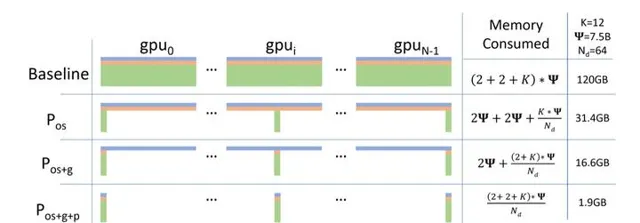
- ZeRO: Memory Optimization Towards Training A Trillion Parameter Models Samyam.
微軟提出很經典很經典的一個演算法了,為了這個演算法還基於Pytroch開發了一個分布式並列DeepSpeed框架。現有普遍的數據並列模式下的深度學習訓練,每一台機器都需要消耗固定大小的全量記憶體,這部份記憶體和並不會隨著數據的並列而減小,因而,數據並列模式下機器的記憶體通常會成為訓練的瓶頸。這篇論文開發了一個Zero Redundancy Optimizer (ZeRO),主要用於解決數據並列狀態下記憶體不足的問題,使得模型的記憶體可以平均分配到每個gpu上,每個gpu上的記憶體消耗與數據並列度成反比,而又基本不影響通訊效率。
- Mixed precision training.
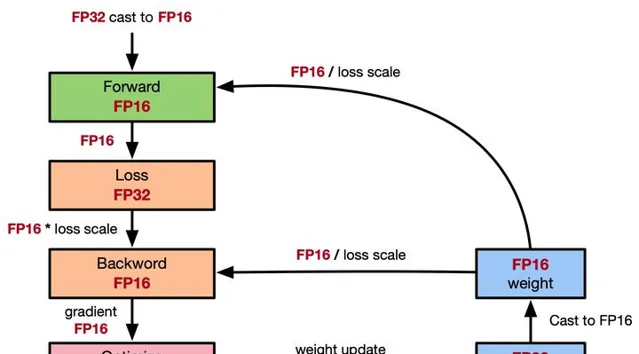
混合精度的文章,參考ZOMI醬寫得全網最全-混合精度訓練原理啦,裏面的內容都在文章中。
底層系統架構相關
- Parameter Server for Distributed Machine Learning
亞馬遜首席科學家李沐在讀書時期發表的文章。工業界需要訓練大型的機器學習模型,一些廣泛使用的特定的模型在規模上的兩個特點:1. 深度學習模型參數很大,超過單個機器的容納能力有限;2. 訓練數據巨大,需要分布式並列提速。這種需求下,當前類似Map Reduce的框架並不能很好適合。於是李沐大神在OSDI和NIPS上都發過文章,其中OSDI版本偏向於系統設計,而NIPS版本偏向於演算法層面。關於深度學習分布式訓練架構來說是一個奠基性的文章。
- More Effective Distributed ML via a Stale Synchronous Parallel Parameter Server.
- GeePS: Scalable deep learning on distributed GPUs with a GPU-specialized parameter server
分布式深度學習可以采用BSP和SSP兩種模式。1為SSP透過允許faster worker使用staled參數,從而達到平衡計算和網絡通訊開銷時間的效果。SSP每次叠代收斂變慢,但是每次叠代時間更短,在CPU集群上,SSP總體收斂速度比BSP更快,但是在GPU集群上訓練,2為BSP總體收斂速度比SSP反而快很多。
- Bandwidth Optimal All-reduce Algorithms for Clusters of Workstations
- Bringing HPC Techniques toDeep Learning
百度在17年的時候聯合NVIDIA,提出了ring-all-reduce通訊方式,現在已經成為了業界通訊標準方式或者是大模型通訊的方式。過去幾年中,神經網絡規模不斷擴大,而訓練可能需要大量的數據和計算資源。 為了提供所需的計算能力,我們使用高效能計算(HPC)常用的技術將模型縮放到數十個GPU,但在深度學習中卻沒有充分使用。 這種ring allreduce技術減少了在不同GPU之間進行通訊所花費的時間,從而使他們可以將更多的時間花費在進行有用的計算上。 在百度的矽谷AI實驗室(SVAIL)中,我們成功地使用了這些技術來訓練最先進的語音辨識模型。 我們很高興將Ring Allreduce的實作釋出為TensorFlow的庫和修補程式程式,並希望透過釋出這些庫,我們可以使深度學習社區更有效地擴充套件其模型。








