11月20日,在酷+科技峰會科技創新專場, RockAI CEO劉凡平發表了【大模型與物理空間:從單體智能到群體智能】的主題演講,主要探討了當前大模型面臨的諸多問題、群體智能是未來方向,以及大模型從單體智能到群體智能的發展路徑。
在演講中,劉凡平首先對大模型現狀與問題進行了分析,主要為現有大模型的局限、現有架構不足。當前大模型套用形式多為單體推理,依賴海量數據和強大算力,存在不合理性。其學習模式與人類不同,缺乏在現實生活中即時學習、互動的能力,且Transformer架構在儲存頻寬、訓練效果、多模態能力、即時性、能耗散熱等方面存在問題。OpenAI等面臨算力和數據充足但仍存在問題的困境,演算法才是核心。Transformer架構的原作者及圖靈獎獲得者如楊立昆、辛頓等也指出其存在的問題,如Scaling Law極限問題、計算資源浪費等,因此我們需要更好的架構。
Yan架構正是在這樣的背景下誕生的,它是首個國產化非Transformer架構。Yan架構多模態大模型在效能和效率上優於同類,可達到Llama3 8B的水平,訓練效率更高,推理吞吐更大,且能在樹莓派等多種低算力器材上部署。上述創新依據的基礎原理包含MCSD和類腦啟用機制。類腦啟用機制模擬人腦神經元啟用模式,選擇性啟用部份參數,降低算力依賴,實作訓練與推理同步,從而大幅提升模型效能。
關於通用人工智能的終局,RockAI認為是群體智能。RockAI在大模型領域首倡「群體智能」概念,並找到了實作路徑,且已走在路上。實作群體智能需具備自主學習、人機互動和適配更多終端三個條件。群體智能叠代路線包括創新性基礎架構、多元化硬件生態、自適應智能前進演化和協同化群體智能四個階段。RockAI處於第三階段並在追求群體智能,與OpenAI模式不同,堅持在演算法層面做創新。當前Transformer架構雖存在問題,但數據采集方式已使其有智能湧現能力,若將大模型引入物理世界有望實作超指數級智能化增長。
了解更多幹貨,詳見劉凡平的演講全文(共5217字,約需20分鐘)。
大模型現狀與問題分析
在開始之前,我想讓大家思考幾個小問題,可能在座很多人都想過這些問題,尤其是技術類的同仁們。
第一個是,我們現在離通用人工智能到底還有多遠?這個答案現在沒有一家能說得清楚。當前的大模型是否具備突破通用人工智能的潛力?OpenAI當時出來的時候,很多人都說它是走向了通用人工智能。但是從現在的實際情況來看,是這樣嗎?好像不是。看OpenAI最近的一些演講,你會發現他們說Scaling Law似乎異常了,這是OpenAI自己的研究員在說這件事情。
第二個是,我們現在的大模型是否真正能夠有自己的學習模式?現在大模型的模式是先預訓練、再微調,然後再去做運用推理,但這好像違背了我們的常識。為什麽?因為人可以在現實生活中學習,而現在的大模型不具備這個能力。那是不是說明我們的大模型發展遇到了問題?這個問題我們在很多年前就已經發現了。Transformer架構在2017年出來的時候,我是它忠實的擁護者,那個時候我基本上想到一切只要是序列相關的事情,第一時間就想到Transformer,GPT-1和GPT-2我全部都用過。
回到現在來看,Transformer作為當前大模型的核心,它真的是無可替代的嗎?
這些問題,其實都是我們創新的起點,所以RockAI是從很多年前就開始在做底層技術的研究。但是我們很低調,因為不打榜所以別人不知道我們,事實上我們很願意跟大家分享在技術上的一些成果。
不得不承認的一個點是,我們目前訓練的大模型,不管是哪一家訓練的,都是一個單體智能的大模型。它需要我們從物理世界獲得海量數據,這些海量數據給到伺服器上,然後讓更大的算力去訓練它。這個過程是不太合理的,為什麽要把那麽多數據放到伺服器上整理出來給它,而不是讓模型直接走向現實的世界來做這個事情呢?
我們今天在座的大概有一兩百人,如果說我們每個人都是一個終端,大腦就是我們的模型。其實我們的大腦是走向了物理世界去學習,而不是我們把數據送到大腦裏面,走向物理世界才是最根本的東西。所以我們非常贊同像李飛飛他們提到的空間智能等等,但我們更認為群體智能是邁向未來的更好的一個階梯。
群體智能是未來方向
為什麽是群體智能呢?
因為群體智能在自然界中是廣泛存在的,人類社會發展到今天,一定是依靠群體智能。每個人不會一出生就絕對聰明,但是你可以在學校裏學習,跟同學、同事交流,在交流的過程中獲得更多的知識。你可以翻閱一千年以前古人寫的書籍學習知識,會發現我們學習的東西其實都是基於別人而產生的。
那我們為什麽不相信群體智能才是走向更好的一個狀態呢?非要投入上億或者上十億的資金去買伺服器,在全世界的範圍內找數據去訓練一個模型嗎?我覺得這也是OpenAI現在面臨的非常重要的一個問題,它的算力已經是全球第一,數據已經是最多的,但還在說算力不夠,問題出在哪裏呢? 我們說AI的三要素是數據、演算法、算力。那麽多數據已經有了,算力也有了,那核心問題在哪裏呢?肯定就在演算法,所以我們願意堅持在演算法上做創新。
我們認為實作群體智能有三個必要條件:
第一,自主學習。
自主學習,是我們一定要讓模型在器材端以及其他任何一個場景下,都能夠學習。如果模型只能在器材上做推理,它一定陪大家不久,因為它不能學習你所擁有的一切知識。而物理世界是因為人與人之間的互動產生更多的數據,這些數據是要被即時學習到的。
就像今天大家坐在一起交流AI,如果現在讓一個雲端的大模型來訓練它,就得把所有影片、音訊收集起來放到伺服器上去訓練。但這樣真的好嗎?肯定不是。如果有個大模型就在眼前,它可以在這裏直接學習、吸收今天的內容,這才是最好的方式。
所以自主學習是指訓推同步,比如這會兒我在介紹的時候,就是一個推理的過程,但如果和大家有什麽交流,或者我看到一些新東西,就是我即時學習的過程,我的訓練和學習是同時進行的。
第二,人機互動。
人機互動是目前傳統的大模型(Transformer架構)都在努力做的一件事情。
第三,適配更多的終端。
只有更多的終端擁有AI,才有可能實作群體智能。就像人類社會一樣,只有更多的人的存在,才可能有人類社會的文明。
Transformer架構的大模型能否成為群體智能的單元大模型?很難。
為什麽它很難呢?我們很久之前在內部總結過,第一是它的儲存頻寬限制、訓練效果不佳還有幻覺影響,第二是多模態能力的不確定性,以及即時性,即時性基本上是它的致命痛點。第三是能耗和散熱,要在器材上能夠完整地跑起來,它所帶來的能耗遠遠高於以前的一些演算法。由此,我們認為從實踐的角度來說,Tansformer架構的大模型很難成為群體智能的單元大模型,這是基於我們幾年前的工作經驗和實踐得出的。
但其實最近一年,人工智能的三巨頭本吉奧(Joshua Bengio)、楊立昆(Yann LeCun)和辛頓(Geoffrey Hinton),辛頓也是前段時間諾貝爾獎的獲得者,他們都提到過現在大模型的一些情況,尤其是楊立昆,他在推特上直接說不做大模型了。
今年上半年輝達GDC大會,黃仁勛邀請了Transformer架構的7位作者(8位元中的7位),其中有兩位都提到Transformer的事情,這個世界需要比Transformer更好的東西,另外一位提到一個簡單的「2+2」就需要模型裏面所有的參數參與運算。大家想想這是錯誤的,怎麽能算一個「2+2」讓所有的參數參與運算呢?
其實Transformer架構的原作者早就知道這些問題了。但是ChatGPT在2022年火的時候大家忽視了這些問題,一股腦鉆進去,而我們是保持頭腦清醒的一部份人。
我們認為通用人工智能要走下去,至少經歷四個階段:
第一階段是架構重塑。 架構一定得改,如果用現有的架構,一定走不到通用人工智能。我們自己已經完成了第一步非Transformer架構的工作。
第二階段是單體推理。 單體推理是說器材上只能做推理,不做訓練。目前絕大部份Transformer架構的模型都在這樣一個階段,不管在伺服器也好、在手機上,只能做推理,不能做學習。
RockAI是在第三階段單體智能,不僅能做推理,還能做學習。
第四階段是我們目前在追求的一個方向,群體智能,這也是我們自己認為通用人工智能應該走的一個路徑。 這個路徑與國內跟隨的模式不太一樣,國內跟隨了OpenAI,我們和OpenAI的模式、思路完全不一樣。所以我們也堅信在很多年前我們選擇創業時,就已經是正確的方向。因為我們覺得,現在OpenAI遇到的問題,其實就是我們在解決的問題。
新架構 的模型, 才是 正 解 !
我們在8月測了模型的一些效能,這是直接從論文截出來的,沒有公開打榜。
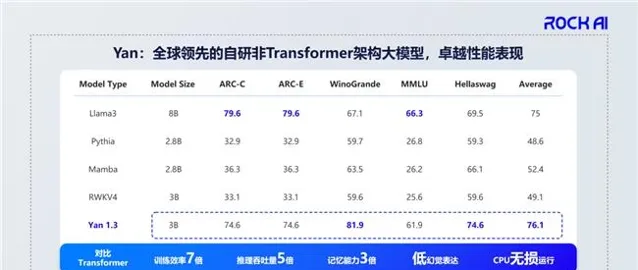
RockAI的Yan1.3是3B的模型,已經達到Llama3 8B的水平。 大家可能會好奇,為什麽我們會選擇Llama3的8B?因為國內部份模型廠商是用Llama3的8B來套殼,以3B達到8B的效果,意味著我們的資訊密度遠遠高於Llama。在這樣的情況下我們套不了殼,因為沒法用他們的東西。
不僅是效果層面,在訓練效率上,同樣的數據、同樣的參數量級下,如果Transformer架構的模型訓練要700個小時,我們只需要100個小時;同樣的資源、同樣的數據、同樣的參數量級下,推理吞吐大概是它的5倍,也就是如果一台伺服器它只能給10個人用,我們可以給50個人用。
這種效能和效率各方面的提升再次證明了一個問題——非Transformer架構才是有價值的。 我們應該去探索更多的路,而不應該去follow別人,一旦進入follow的模式,創新就遺失了。尤其在技術領域,其實國內的技術人員非常優秀,但是我們的創新還不足。
這是我們模型目前的結構,它是一個完全端到端、秒級即時響應的模型。
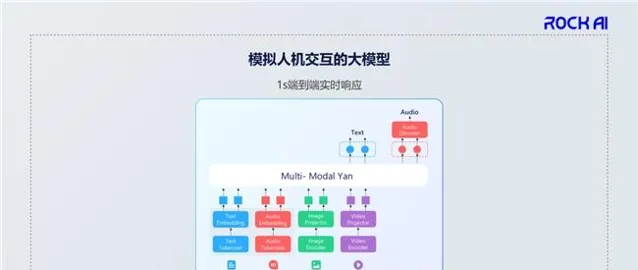
RockAI一直專註於基礎技術的創新,我想重點跟大家分享兩個機制。
第一,MCSD。
在研究MCSD模組的過程中,我們也驗證了Scaling Law機制,但只是過程性的驗證,並不是說要去做Scaling Law。可以這樣理解,Transformer架構是一個藍牌的燃油汽車,Attention機制是它的核心,是它的發動機,我們采用MCSD模組把它的發動機變成電機,它的響應效能等方面就變得更快。
第二,類腦啟用機制。
這是在國內、矽谷,甚至歐洲都沒有實作,而RockAI已經實作的一套方式。我們也申請了專利,包括國際專利。
類腦啟用機制,大家可以想象一個很簡單的場景:當你看電影時,大腦的視覺皮層會被大量啟用,因為大腦要處理這些視覺資訊的輸入,但是電影看完後回到家裏休息,閉上眼睛,這時候大腦的視覺皮層是被抑制的,沒有啟用。所以人的大腦工作時,並不是所有的參數都會參與運算,而是根據實際場景選擇性地啟用一部份。
人的大腦包括視覺區、聽覺區和語言功能區等多個功能區域。類腦啟用機制我們用到模型裏,最開始也是隨機了大量的神經元,神經元之間沒有任何關系,不像Transformer架構在定義的時候結構已經固定好,每一個參數都不能改變,而我們每一個參數是可以調整的。
在這樣的情況下,我們透過大量的數據自適應訓練,實作處理推理和訓練時只有少部份功能被啟用。比如說人在聽聲音時聽覺區會被啟用,反映在模型裏,聽覺區的參數會被啟用,而視覺和其他區域的參數不會被啟用,所以算力一定會降下去。
這就是為什麽人的大腦只有20多瓦的能耗,但是能支撐起大約860億參數的執行。而現實物理世界裏Transformer架構的模型,2000瓦的GPU伺服器可能都不能支撐上千億參數的執行。核心問題在於演算法層面,所以我們在演算法層面做了很多創新。
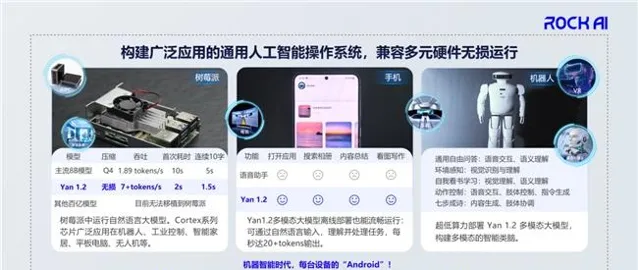
也正是因為演算法層面的創新,所以我們今年5月就做到全球首個真正在樹莓派上部署大模型,而且是多模態大模型。我們也已經透過今年的世界人工智能大會對外展示。直到現在,過去6個多月,還沒有另外一家廠商能夠在樹莓派上部署模型,姑且不說多模態大模型,連自然語言的大模型都無法部署。為什麽?因為演算法底層一定要創新,如果沒有創新是做不到的。
同時我們還可以在手機、家裏的電視、路由器等使用場景中部署模型,這意味著我們可以讓更多的器材用上我們的AI。 結合實作群體智能的三個必要條件,讓更多的器材用上人工智能,再加上自主學習能力,它就可以在終端發揮更大的能力。其實可以理解為我們每個人就是一個終端,只是這個終端有很強大的學習能力,所以人類從生物界裏面走出來了。如果說機器的智能也是這樣,那是不是可以認為這才是通往通用人工智能最好的路徑呢?
大模型最核心的能力是什麽?自主學習能力。
這也是為什麽我們不打榜單的原因,很多時候榜單只能作為參考,模型本身「出生」的時候,它的聰明程度沒有太大關系。以我們自己為例,不管是在學校,還是走向社會,伴隨我們最好的能力不是現在掌握的知識,而是自身的學習能力。假如現在讓我在從來沒幹過的金融崗位上工作,即使我並不具備這方面知識,但我的學習能力足夠強,那麽我就能在這個領域裏有所表現。
自主學習能力遠遠超過了現在榜單上評測的科學、數學、邏輯等能力,這是我們認為支撐人工智能下一步發展最關鍵的力量,也是目前Transformer架構的大模型遇到的困境。我們認為因為它不具備自主學習的能力,也就不具備在物理世界裏持續前進演化的能力。
一旦自主學習實作之後,它就會形成個人化, 個人化是人類社會發展的一個趨勢。大家可以發現,從2000年左右互聯網發展,那個時候我們看到的新聞網站基本上一樣,後來有了推薦,每個人看到的新聞就不一樣。到現在無論是抖音還是其他影片平台,每個人看到的影片都不一樣,個人化趨勢非常明顯。
大模型也一樣,它最終要服務於社會生產和勞動,如果說大模型不能做到個人化,一個絕對的雲端通用大模型能解決的問題少之又少。它應該從宏觀的適配自然場景、適配業務,到微觀的適配到每一個人,這樣走下去。而這個過程最重要的是自主學習,如果沒有自主學習,一定會遇到瓶頸,就像現在的Transformer架構。
當然,從我們自己的角度來說,要構建的就是群體智能。我們從最底層的Yan架構大模型開始,這是千裏之行的第一步。這一步完成之後,就是構建通用人工智能作業系統。我們現在已經在手機、樹莓派、PC、無人機等等這些器材上完全執行了我們的大模型,之後會把模型變成一個作業系統,讓更多的器材能夠使用。當每一台器材都擁有智能能力以及自主學習能力之後,它就會形成群體智能。
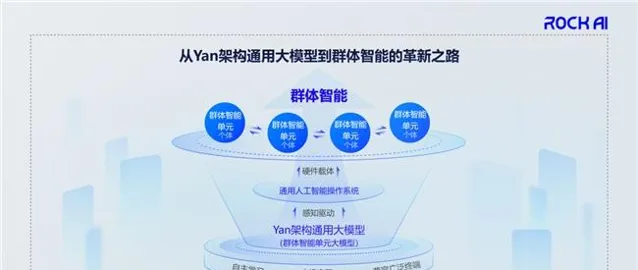
我們認為群體智能叠代的路線有四個階段:
第一步是 創新性基礎架構。 這個如果沒有突破,後面都是零。Transformer架構現在遇到的問題,包括熱議的Scaling Law似乎異常等等問題,就是因為第一步沒有做好,而我們在很多年前就意識到了。
第二步是 多元化硬件生態, 讓更多的器材用起來。
第三步是 自適應智能前進演化, 在器材上自主前進演化。
第四步是 協同化群體智能, 器材與器材之間串聯起來,形成相互學習、協同效應。
Transformer架構的訓練模式,需要從物理世界去獲得廣泛的數據,大家有沒有想過這個數據從哪裏來的?
一個人產生的數據是非常有限的,基本上在社會裏可以忽略不計,但是兩個人產生的和四個人產生的數據是指數級增長的。現在的Transformer架構的模型把這些數據收集起來,放到雲端訓練,大家可以理解為,把人類社會群體智能產生的社會活動數據,餵給Transformer架構大模型。因為它是靜止不動的,所以需要餵數據讓它去訓練、學習。
但是我們必須得讓它走出來,如果說現階段透過采集數據的方式已經讓它有智能湧現的能力,那麽讓模型進入物理世界,它所產生的數據遠遠比采集的多,智能化程度就會得到超指數級的一個增長,這個過程中才會產生真正的智能,而這樣的智能才是我們真正想要的。
所以通往通用人工智能這條路,我們一直認為不是OpenAI選擇的那條路,而是群體智能之路。不久前Google發了一篇paper專門講群體智能,剛好印證了我們之前的很多想法。今天的技術峰會匯聚了很多技術的創新者和技術的領先者們,這是一個很好的契機,我們應該鼓勵更多的人去做創新,而不是follow,這樣中國的通用人工智能發展才有可能有希望。
謝謝大家!











