編輯:LRS
【新智元導讀】人工智能工具正在幫助科研人員快速整合和理解大量科學文獻,但完全自動化的高質素文獻綜述生成仍面臨挑戰,雖然能提升研究效率,但也存在生成低質素綜述的風險,需謹慎使用,所以說現階段還是人眼看論文靠譜。
網絡的普及,加上文獻數量的爆炸式增長,如今的科研人員要面臨的一個主要難題就是,盡管可能已經收集了足夠的數據來幫助理解某個復雜的領域或系統,但由於資訊量的巨大,人類無法全面地閱讀和理解所有文獻。
就像是面對一個巨大的圖書館,雖然每本書都包含了寶貴的知識,但沒有人能夠閱讀所有的書籍並從中獲得一個完整的認知。

因此,盡管科學的進步為我們提供了大量的數據,但如何有效地整合和理解這些數據仍然是一個亟待解決的問題。
最近Nature上有一篇專欄文章,介紹了一些現有的、文獻綜述自動化生成的方法,並指出了這類方法主要面臨的困境及使用者痛點。

文章連結:https://www.nature.com/articles/d41586-024-03676-9
盡管身處ChatGPT時代,但想要完全沒有人類參與,讓AI「一鍵」完成系統性綜述生成,集查詢、整理、文獻篩選、總結歸納等於一身,並且沒有幻覺錯誤,仍然是一項不可能完成的任務。
用AI做文獻綜述
幾十年來,研究人員們一直在嘗試提升「將大量相關研究組譯成綜述」的速度,由於工作量過大,很多綜述在送出的時候往往就已經過時了。
ChatGPT等大模型展現出的超強語言理解能力,也再次激發了人們對於自動化綜述的興趣,今年9月, 美國初創公司FutureHouse構建了一個新系統,宣稱能夠在幾分鐘內生成一個比維基百科更準確的科學知識綜合頁面,並且已經為大約17,000個人類基因(human gene)生成了維基百科風格的條目,其中大部份在此前缺乏詳細的描述介紹。

一些科學文獻搜尋引擎也已經開始引入AI驅動能力,來幫助使用者透過尋找、排序和總結出版物來制作敘述性文獻綜述,但目前質素普遍比較低。
大多數研究人員都 認可 ,離實作自動化「金標準綜述」還有很長的路要走,整個過程涉及嚴格的程式來搜尋和評估論文,還包括元分析來合成結果,或許10年、甚至100年後才能略有進展。
電腦輔助評審
幾十年來,電腦軟件一直在輔助研究人員搜尋和解析研究文獻。
早在大型語言模型(LLMs)出現之前,科學家們就開始使用機器學習和其他演算法來幫助辨識特定研究,或快速從論文中提取發現,但類似ChatGPT這樣的大模型讓自動綜述的能力顯著提升。
不過,研究人員表示,要求ChatGPT或其他AI聊天機器人從頭開始撰寫學術文獻綜述,是相當不現實的。
如果模型被要求對某個主題的研究進行綜述,LLM可能會從一些可信的學術研究、不準確的網誌中,或是其他未知的資訊來源中整合資訊,而不會對最相關、最高質素的文獻進行權衡。
LLMs的執行機制,即透過反復生成對查詢在統計上合理的單詞,決定了模型對同一個問題會生成不同的答案,並「幻想」出一些錯誤資訊,比如眾所周知的「不存在」的學術參照,和人類進行綜述的過程可以說是毫無相似之處。
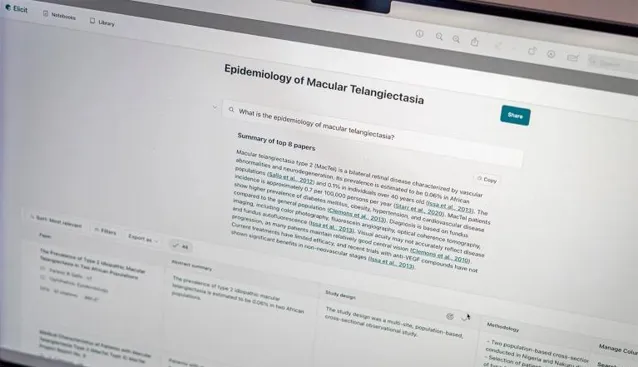
一個更復雜的過程是檢索增強生成(RAG),包括將預先選定的論文語料庫上傳到LLM,並要求模型從中提取關鍵點,並基於這些研究給出答案,可以在一定程度上減少幻覺現象,但無法完全消滅幻覺。
RAG的過程中,還可以設定資訊來源,類似Consensus和Elicit等專門的、AI驅動的科學搜尋引擎就是這樣做的,雖然大多數公司沒有透露系統工作的確切細節,但大體上就是將使用者的問題轉化為對學術數據庫(如Semantic Scholar和PubMed)的搜尋,並返回最相關的結果。
基於搜尋結果,大型語言模型(LLM)會總結這些研究,並將其綜合成一個「帶參照來源」的答案,使用者可以根據具體需要選擇要參照的工作。
丹麥南部大學奧頓塞分校的博士後研究員Mushtaq Bilal認為,這些工具肯定 能讓 提升綜述和寫作的效率,並且還自己開發了一個工具Research Kick。
至少搜尋引擎參照的內容是絕對真實存在的,使用者可以進一步點選檢視,自己分辨。
不同的輔助工具有不同的特點,例如Scite系統可以快速生成支持或反駁某個主張的論文的詳細分解,Elicit等系統可以從論文的不同部份提取間接(方法、結論等)。

大多數AI科學搜尋引擎不能全自動地生成準確的文獻綜述,其輸出更像是「一個本科生通宵達旦,然後總結出幾篇論文的主要觀點」,所以研究人員最好使用這些工具來最佳化綜述過程中的部份環節。
但這種工具還有一些缺點,例如只能搜尋開放獲取的論文和摘要,而非文章的全文,Elicit搜尋約1.25億篇論文,Consensus包含超過2億篇。
大部份研究文獻都處於付費墻後,而且搜尋大量全文計算量很大,讓AI套用執行數百萬篇文章的全部文本將需要很多時間,計算成本也會非常高。
系統性綜述仍然很難
敘述性地總結文獻已經非常難了,如果想把相關工作系統性地綜述更是難上加難,一個專業的研究人員也需要花費數月甚至數年才能完成。
根據Glasziou團隊的分析,系統綜述包括至少25個仔細的步驟,在梳理文獻後,研究人員必須從長列表中篩選出最相關的論文,然後提取數據,過濾出可能存在偏見的研究,並綜合結果。
這些步驟通常還需要另一位研究人員進行重復,以檢查不一致性。
在ChatGPT出現之前,Glasziou開始嘗試創造科學界的世界紀錄:在兩周內完成一篇系統綜述。
Glasziou和其他幾位同事,包括Marshall和Thomas,已經開發了電腦工具來提高效率,當時可用的軟件包括RobotSearch,能夠快速從一系列研究中辨識出隨機試驗;RobotReviewer可以幫助評估研究是否存在因為未充分盲化而產生偏見的風險。
第一次嘗試最終總共用了九個工作日;後來團隊又將該記錄縮短到了五天。
這個過程還能變得更快嗎?

Elicit是一家專註於幫助研究人員進行系統綜述而不僅僅是敘述性綜述的公司,但該工具並不提供一鍵式系統綜述,而是自動化其中某些步驟,包括篩選論文和提取數據等。
大多數使用Elicit進行系統綜述的研究人員都會上傳使用其他搜尋引擎找到的相關論文,但使用者普遍擔心這類工具可能無法滿足研究的兩個基本標準:透明度和可復制性。
如果不理解具體的演算法,那就不算是系統綜述,而只是一篇簡單的綜述文章。
今年早些時候,Glasziou團隊成員Clark領導了一項系統綜述,研究了使用生成式AI工具輔助系統綜述的研究,最終團隊只找到了15項已發表的研究,並將AI的效能與人進行充分對比。
這些尚未發表或同行評審的結果表明,這些AI系統可以從上傳的研究中提取一些數據,並評估臨床試驗的偏差風險。
現有的模型在閱讀和評估論文方面似乎做得還不錯,但在所有其他任務上表現得非常糟糕,包括設計和進行完善徹底的文獻搜尋。
潛在風險
自動化資訊合成也伴隨著風險。
研究人員多年來就知道許多系統評價存在冗余或質素差等問題,而人工智能可能會使這些問題變得更糟;作者可能會有意或無意地使用人工智能工具來快速完成不遵循嚴格程式或包含低質素工作的評審,並得到誤導性的結果。
除了綜述別人的工作外,Glasziou表示,這類模型還可以促使研究人員快速檢查以前發表的文獻,找出其中的錯誤,來繼續提高研究人員的水平。
甚至在未來,人工智能工具可以透過尋找P-hacking等明顯跡象來幫助標記和過濾掉質素較差的論文。
Glasziou將這種情況視為一種平衡:人工智能工具可以幫助科學家做出高質素的評審,但也可能會讓部份研究者快速生成不合格的論文,目前還不知道會對出版的文獻產生什麽影響。
有些研究者認為,合成和理解世界知識的能力不應僅僅掌握在不透明的營利性公司手中,希望未來可以看到非營利組織構建並仔細測試人工智能工具,小心謹慎地,盡可能保證每次提供的答案都是正確的。











