-Datawhale幹貨-
作者: @我想了很多事 ,Datawhale優秀選手
文章原文: 我想了很多事:再一次慘敗,訊飛2021關系抽取大賽前十記錄。
前言
又一次參加了比賽,這次還是沒有拿到特別靠前的位置,靠隊友闖入了前十,心裏難免失落,但是這也自己實力不足導致,希望再接再厲能取得更好的成績吧。
分享下本次比賽自己的收獲,也希望各位大佬多多交流,本次比賽的賽題是醫療文本中分別抽取出實體跟關系,此類的任務目前應該也算是比較常見的,這裏我就想大概介紹下。
此類任務的方法,首先NER的任務應該也有很多的分享與方案,這裏筆者之前也做過相關的總結,還沒看過的小夥伴可以觀看下如下的總結:我這裏就大概講下此次比賽中用到的方法,後續程式碼也會整理到筆者的Github:
開源:https:// github.com/powerycy/Dee pKg
比賽連結:https:// challenge.xfyun.cn/topi c/info?type=medical-entity
NER部份
Biaffine
NER部份筆者主要運用了兩種方法進行實驗,首先是目前比較主流的
Mulit-head
,
Biaffine
跟
GlobalPointer
三種方法,而
Mulit-head
的方法因為是線性的變換,筆者這裏沒有用此方法進行試驗,而是直接采樣了
Biaffine
的形式進行NER的訓練,這裏簡單介紹下
Biaffine
機制,這裏舉個例子:
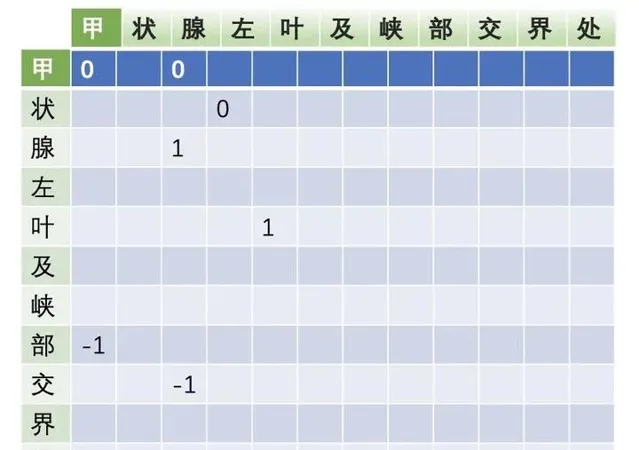
詳情請見文章:https:// zhuanlan.zhihu.com/p/37 5805722
透過筆者的實驗,發現此方法效果不錯,可以作為Base的其中之一來進行使用。而剩下進行一些常規的操作,首先加入了
label_embedding
作為特征,然後透過取
Roberta模型
的後兩層跟
CLS層
,一層作為
start
,一層作為end提取出的特征,經過FFNN,而
CLS層
融入到特征中,經過
Biaffine
矩陣,在透過
mask
掉
pad
跟下三角得到最終的
logits
。
此方法是蘇神之前介紹的方法效果很好並且速度非常快,蘇神在網誌做過詳細的介紹(筆者在之前的文章也做過介紹),這裏就稍加說下:
假設要辨識文本序列長度為 ,先假定只有一種實體要辨識,並且假定每個待辨識實體是該序列的一個連續片段,長度不限,並且可以相互巢狀(兩 個實體之間有交集),那麽該序列有個不同的連續子序列,這些子序列包含了所有可能的實體。
而我們要做的就是從這個「候選實體」裏邊挑出真正的實體,其實就是一個「選」的多標簽分類問題。這就是GlobalPointer的基本思想,以實體為基本單位進行判別。
筆者也是在此基礎上加入了
label_embedding
跟
CLS層
進行NER的訓練,最後筆者采用了
GlobalPointer
的方案。
詞匯增強已經普遍認為可以提升NER的效果了,筆者這裏是首先是把訓練集中的詞加入詞典,並把其拼接到整句話中,然後透過Mask矩陣讓整句話不與詞進行互動,但詞語整句話進行互動。
關於NER部份之前也寫過一篇來自騰訊的實驗,是來解決未標註實體在NER中帶來的問題,筆者也是進行了復現以及跟整個程式碼進行了一個整合。
關系抽取部份
NER部份筆者之前有一些程式碼的積累能快速的得到答案,而RE部份筆者這次做的比較的慌張,因為之前筆者並沒有在這方面整理出一個體系程式碼,所以大部份時間也都花費在這個上面。
熟悉RE任務的人應該很清楚,目前關於RE的方法分為Pipeline跟Join的方法,而RE任務目前的重疊問題筆者在這裏就簡單介紹一下:
一對多問題
,如「周杰倫演唱過【止戰之殤】【亂舞春秋】」中,存在2種關系:「周杰倫-歌手-止戰之殤」和「周杰倫-歌手-亂舞春秋」
一對實體存在多種關系
,如「周杰倫作曲並演唱【外婆】」中,存在2種關系:「周杰倫-歌手-外婆」和「周杰倫-作曲-外婆」
復雜關系問題
,由實體重疊導致。如【葉聖陶散文選集】中,葉聖陶-作品-葉聖陶散文選集;針對一系列的問題,目前有很多的論文提出了解決方案,比如一些常見的聯合抽取模型,聯合抽取就是將兩個子模型統一建模,以緩解錯誤傳播的缺點,對於聯合抽取已經有一系列的研究了。
筆者因為時間原因並沒有去嘗試比較經典的一些方法,而是采用了近兩年比較流行的一些方法,首先映入眼簾的是RE中通用性非常廣泛,也是蘇神所提出的
CasRel方法
,此方法在各大關系抽取大賽中基本都是常客,非常多的人使用,效果也很強大,筆者之前復現過一個torch的版本:https://
zhuanlan.zhihu.com/p/13
8858558
具體的詳情也可去蘇神的網誌進行觀看(筆者在之前的文章也做過介紹),簡單概括就是利用概率圖的思想:首先預測第一個實體Sub,預測出Sub過後透過
ConditionalLayerNorm
傳入Sub的特征在進行多標簽分類來得到Relation跟Obj。
而針對此方法以及過往比賽的分享來看主要是進行了如下的改變。
這種方案非常給力,這裏也是非常感謝自己的朋友們來跑這種方案,而筆者有更多的精力去做其他的方案,那麽還有哪些方案可以來做呢,筆者就來介紹一下首先也是大部份做RE的人也比較熟悉的TPLinker這篇文章,(筆者也進行過一個解讀):https:// zhuanlan.zhihu.com/p/34 2300800
簡單來說就是為了避免曝光偏差同時抽取出實體與關系,這裏筆者之前雖然分享了一篇源碼解讀,但是因個人能力有限無法對其進行改動,遂放棄,只能自己來造這個輪子。
不過筆者跟
TPLinker
的做法稍有不同,筆者這裏主要是采用了兩種方式來實作,一個是現在比較流行的
Biaffine
矩陣,另一個是采用蘇神的
GlobalPointer
來做,這裏筆者兩種方法都實驗了,
GlobalPointer
的方法略好,並且所占資源較少。
GlobalPointer關系聯合抽取
關於
GlobalPointer
的做法是,筆者將關系的首尾也標簽化,例如:('甲狀腺左葉及峽部交界處 內容 低回聲結節')這個三元組筆者將首首跟尾尾作為標簽這樣在進行抽取的時候把關系跟實體一起抽出來。
在訓練的時候也是對齊了
Tplinker
的形式,先給實體較大的權重,然後權重慢慢往關系傾斜,推理的時候也是先抽取實體,作為字典,然後抽出頭實體時在字典中尋找,在利用尾實體來確定三元組。
多內容抽取
嚴格來說此次的任務是進行內容抽取,而內容抽取最大的不同是只有內容這一個關系,這裏筆者考慮是否能把內容透過Schema的方式把其定義為不同的內容類別呢,這裏筆者又進行了一次實驗
這裏筆者透過對訓練集的內容類別進行了統計總共有42種schema,筆者分別做出42種內容類別,例如(內容_1,內容_2...)這種形式利用
GlobalPointer
進行關系抽取訓練,也用了蘇神的CasRel進行了訓練,得到的效果跟單個的效果差不多。
而筆者這麽做的原因是因為想實驗另一種方法的結果,從PRGC這篇文章筆者得到啟發(這篇文章筆者會在近段時間進行一個解讀,以及程式碼的整理),筆者主要是在
GlobalPointer
關系抽取的任務裏添加了存在哪些關系的的任務,然後透過一個矩陣U,像取向量一樣取出關系向量,將關系向量加到對應的token向量上最後得到
Logits
,如圖
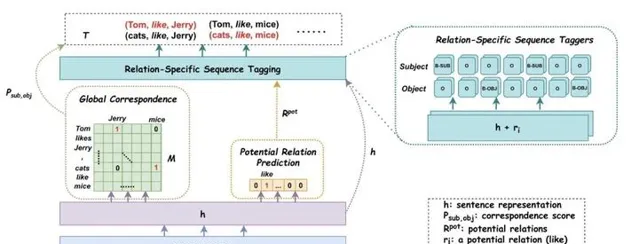
但發現效果也不是特別理想,筆者打算在其他關系抽取的數據集中在進行一些實驗。
PipeLine
去年陳丹琦大佬的文章讓筆者重新審視了
PipeLine
模型跟Joint模型,筆者的印象中一直覺得PipeLine模型會出現誤差積累,任務之間無法互動,計算復雜的刻板印象之中,而現在的SOTA基本全部都是Joint的天下了。沒想到這篇文章的出現也打破了筆者對PipeLine模型的偏見,文章利用兩個encoder組成Pipeline模型,采取兩個獨立的預訓練模型進行編碼。
NER方面透過BERT連線一個Span分類網絡-基於片段排列的方式,提取所有可能的片段排列,透過SoftMax對每一個Span進行實體類別判斷。
RE方面,在第一階段辨識出的實體,用邊界和類別特殊字元標識出來,作為第二階段的輸入 ,第二階段用BERT來預測兩個實體之間的關系,在RE階段將實體邊界和類別作為識別元加入到實體Span前後,辨識出的實體是Method的Subject,就把<S:Md>和</S:Md>插入到實體邊界,同理對於Object也插入<O:Md>和</O:Md>,對每個實體pair中第一個token的編碼進行拼接,然後過全連線層,最後過Softmax。
加速計算:每個實體pair輪流進行關系分類,同一文本需要進行多次編碼,加速的近似模型:可將實體邊界和類別的識別元放入到文本之後,然後與原文對應實體共享位置向量。相同的顏色代表共享相同的位置向量。在attention層中,文本token只去attend文本token、不去attend識別元token,而識別元token可以attend原文token。
原文也做了消融實驗,給出了為何PipeLine的方法為何會比Joint的方法有原因,Joint方法提取的特征可能一致,也可能沖突這樣會使模型的學習變得混亂。在 Two are Better than One中也有相同結論。
但是是否能解決Joint模型所出現的問題呢,ACL2021的UniRE給出了一種解決方案,這篇文章也是填表的方式來解決此問題,總的來說就是把實體辨識轉化成一種特殊的關系分類,如圖:
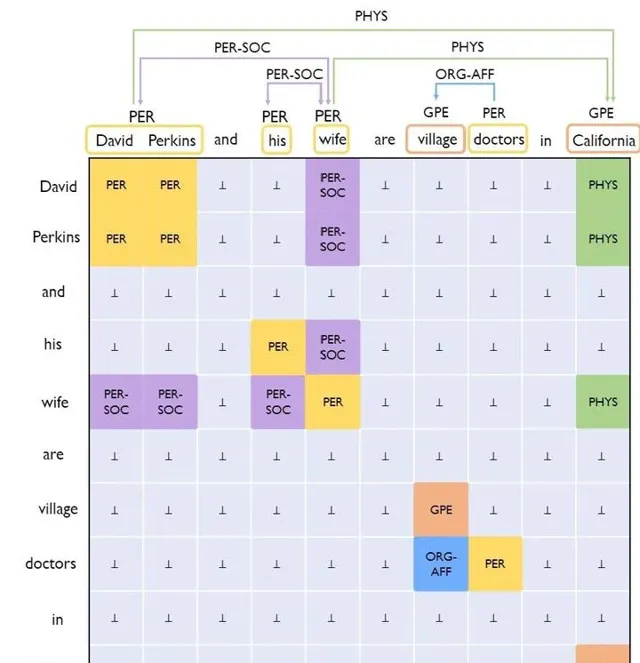
把關系也是分為了:正向關系,逆向關系,無向關系,這樣一來,模型的標簽空間就是一個統一的標簽空間了。(筆者之後會做一個詳細解讀,包括程式碼的整合,這裏就不在詳細展開)。
常規最佳化
到這裏筆者透過實驗最後選擇了
GlobalPointer
的實體關系聯合抽取模型作為Base模型。並對數據集進行清洗,10折交叉得到結果然後投票得到訓練集。
結束語
在這次比賽中筆者也是使用了大量的方法,PipeLine部份的方法有些還沒有實作,筆者這裏也是對這次的大賽做出了一個總結,程式碼部份筆者會盡快整理成統一的形式上傳的Github,也希望大佬們批評指正。
參考文獻:
蘇神的GlobalPointer:https://spaces.ac.cn/archives/8373
對抗訓練:Nicolas:【煉丹技巧】功守道:NLP中的對抗訓練 + PyTorch實作
【A Novel Cascade Binary Tagging Framework for Relational Triple Extraction】
【Named Entity Recognition as Dependency Parsing】
【Empirical Analysis of Unlabeled Entity Problem in Named Entity Recognition】
【TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking】
【PRGC: Potential Relation and Global Correspondence Based Joint Relational Triple Extraction】
【A Frustratingly Easy Approach for Joint Entity and Relation Extraction】
【Two are Better than One:Joint Entity and Relation Extraction with Table-Sequence Encoders】
【UniRE: A Unified Label Space for Entity Relation Extraction】
【R-Drop: Regularized Dropout for Neural Networks】
【Understanding and Improving Layer Normalization】









