想要高端的,學stata,不會的找個會的教你,估計兩小時就可以處理簡單的時間序列或者面板了。
然後知網找個計量的文章,比如xx(解釋變量)與經濟增長,假如你學校北京的你就找個寫上海的文章,看他用的啥數據,你也去找北京的相關數據,用個普通的ols或者面板數據跑一下,顯著了就成了。
然後文獻綜述隨便寫寫根據結果隨便提一下政策建議,文章基本就結了。
查重肯定過,相比絕大部份本科生畢業論文來說,強百倍(這種套路僅適用於經濟金融專業寫本科畢業論文)
當然如果計量模型用的高端點又是別人沒怎麽研究的變量,核心也能發。
-------------------------------------------------------------------
今天閑來無事,更新下,首先講講怎樣尋找可以參考的計量經濟學的實證文章。
經管類的實證文獻,一般題目都有固定套路,那就是解釋變量在前,被解釋變量在後,中間用「與」字或者頓號連線,後面跟個可愛的小尾巴說明下用的數據或者計量模型。舉幾個常見的經管類論文的題目:
第一類:X1與 Y
舉例:
金融發展與經濟增長——基於中國金融發展門檻變量的分析
人力資本與經濟增長關系實證分析——以浙江省為例
第二類:X1、X2 與 Y
舉例:
民間金融、產業發展與經濟增長——基於中國省際面板數據的實證分析
東北三省能源消費、要素投入與經濟增長關系研究——基於長面板和面板因果檢驗模型
金融發展、技術創新與經濟增長的關系研究——基於中國的省市面板數據
金融發展與經濟增長——基於中國金融發展門檻變量的分析
第三類:X 是否(促進了or阻礙了or提升了……) Y
舉例:
金融創新是促進還是阻礙了經濟增長——基於技術進步視角的面板分析
金融發展是否能夠促進海外直接投資——基於面板分位數的經驗分析
經濟增長是否促進官員晉升?——基於廣東省地級市數據的經驗研究
從上面幾個例子可以發現,經管類的實證論文有著很嚴謹的命名方式。
對於本科生來說,以經濟增長作為被解釋變量最簡單,用GDP對數就好了,當然你想復雜點去算實際GDP會更好。也可以采用城鄉收入差距,這個就是城鎮居民可支配收入比上農村居民純收入,統計年鑒都有的。
而解釋變量考慮你的專業,如果是金融學,那金融發展最簡單,一般都是用存貸款余額比GDP表示;如果是國際貿易,可以用進出口總額比GDP作解釋變量;如果是管理學,可以考慮用人力資本變量來做解釋變量,這個一般是用平均受教育年限,會復雜一點,但是人大經濟論壇都有別人算好的可以下了用。
下面以金融發展與經濟增長這個題目,在知網搜尋
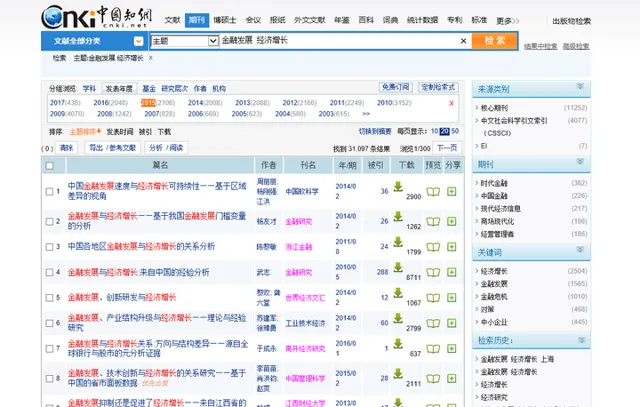
可以看到很多人都寫過這個方面的核刊,如果你以此做題目,一來別人已經做過了,二來這個題目太大了。因此我們可以考慮在後面加個直轄市或者省份,比如上海。
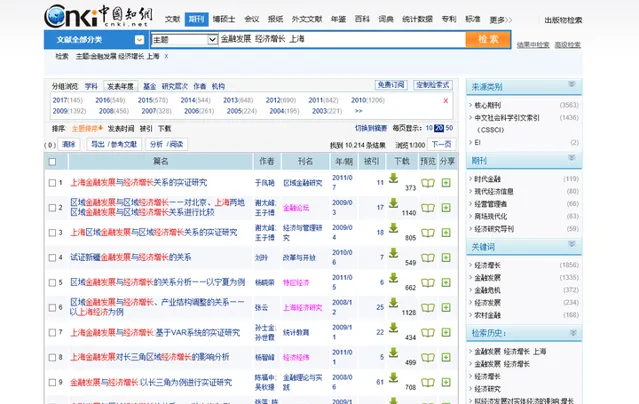
然後我們以這篇研究上海的金融發展與經濟增長的文獻為例。
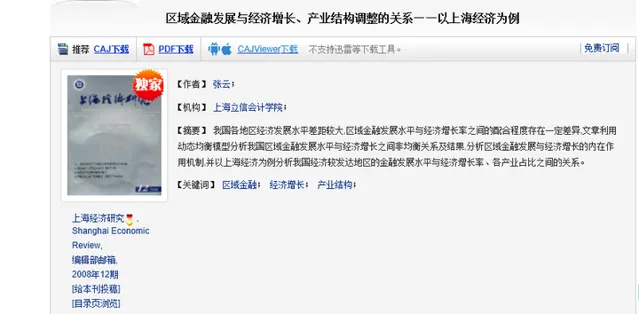
開啟論文我們直接去看模型。

可以看到該文章選取了GDP增長率來衡量經濟增長,你可以簡單點用GDP對數來衡量,而金融發展采用了金融機構存款、貸款在GDP的占比,這些各省統計年鑒都有,搜下統計局的網站都查的到。
既然知道了模型的設立和數據的來源,那麽你可以去套你學校所在的地區,比如我學校新疆的,那我寫畢業論文就可以用新疆的GDP做經濟增長變量,用新疆地區的存貸款余額來做金融發展變量,一個ols就結束了,至於這個ols怎麽做,軟件怎麽用,本科的計量經濟學的書都學過的,如果你不會,說明你一定沒聽課。
如果你覺著你想做更高端的,那就在搜文獻的時候,在後面再加個計量方法的關鍵詞,假設你想找研究金融發展與經濟增長的面板數據模型的文獻,可以這麽搜。
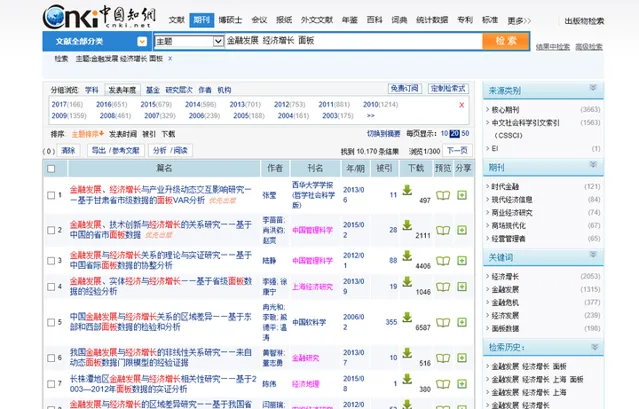
如果你選擇這個題目,顯然還是需要面對題目太大的問題,那麽簡單的解決辦法就是,分區域。比如你看到一個文章用的全國的面板數據,而你的學校在東北,那麽你就可以用東三省數據來做面板模型。(對本科生來說,能用到最簡單的面板固定效應模型,就足夠讓很多老師感動一會了)
順帶丟了Eviews吧,stata才簡單粗暴(用R的請忽視這句話)
有空我會更新下如何用stata做基礎的面板數據模型!
日常摸魚的強師傅,終於想起來填這個大坑了!
許多有關計量的入門教程都上來先丟一堆理論,看的頭暈腦脹,但實際套用卻講的十分含糊
這對於很多想快速水paper或者寫畢業論文交差的同學十分不友好
而跟著本教程走,則可以透過實際的例子,快速的學習Stata軟件的使用,這樣在匯入自己的數據後,可以快速搞出一篇論文的實證模型
經管類專業在本科都會學計量經濟學,但是一般只會教到基本的多元OLS模型就戛然而止了
誠然,這對於本科生來說夠用了,但是基本的多元OLS模型本身並不好處理。如果是橫截面數據,那解決異變異數問題還算簡單,但是大部份容易獲得的經濟數據都是時間序列數據,而時間序列數據的多重共線性處理又十分棘手。本科的計量書裏一般都會說,逐步回歸剔除一下就好了,但是這樣會使得你能用的變量數量大打折扣,有些奇葩導師總會要你必須加一些他們想要的變量,不能讓你去掉。另一個可行的方法則是采用主成分分析降維分析,但是這種方法,又需要用一個復雜的公式換算,過程繁瑣且麻煩,一些類似KMO檢驗的東西還可能根本過不去
因此,強師傅更推薦采用面板數據來處理本科以及碩士的畢業論文實證,因為其檢驗簡單,而且更易操作,總之就是坑少好摸
對於很多上了計量課就浪起來的同學來說,可能還分不清計量裏的三種數據結構
本科一般只教兩種:
橫截面數據:舉例來說,就是中國2020年30個省份的GDP
時間序列數據:整個中國2010至2020年的GDP
而第三種數據結構便是面板數據,實際上就是橫截面數據和時間序列數據的結合
值得註意的是,不同軟件輸入面板數據的格式不一樣,我只推薦Stata來處理這些數據,因為真的對新手很友好
面板數據可以在excel整理好,直接貼上到Stata
一個簡單的面板數據例子如下:
以北京上海和廣州3個城市2010至2016年的人口,地區生成總值和商品房均價為例,在excel裏的整理如下:
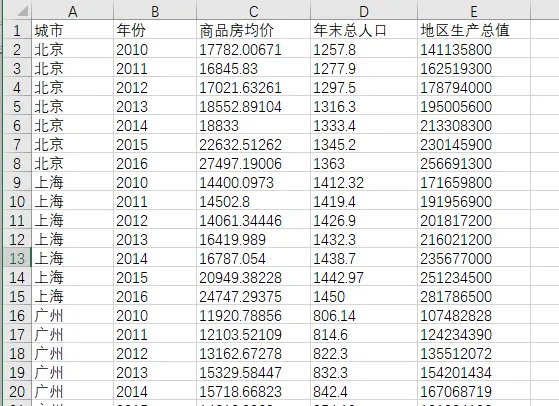
可以看到,A列為我們的具體城市,實際上也就是截面或叫做個體,而B列年份則是時間,其余列為變量
你可以自己搭配不同的數據,整理成這樣的格式即可
開啟stata的視窗

其中下方命令視窗可以直接輸入我們要做的指令,左邊為歷史視窗可以看到我們已經進行過的處理,而變量視窗則可以顯示我們輸入數據後產生的變量
在命令視窗輸入edit則可以開啟數據編輯視窗

將excel的數據連同表頭直接貼上到這個視窗,則會有如下提示:
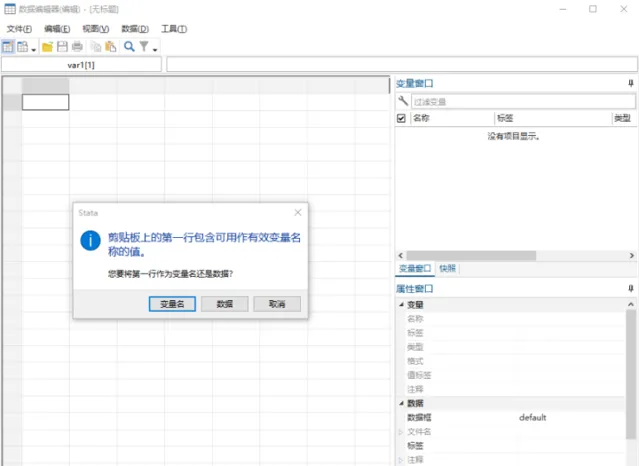
選擇變量名則可以直接將第一行作為變量名稱
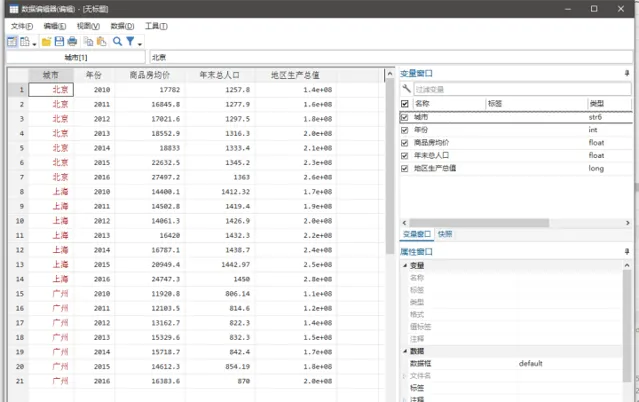
關閉該視窗回到stata主界面,則可以發現,有五個變量21個觀測被匯入了進去
由於城市變量是字元數據,因此在處理之前需要采用encode命令將其改為數值型數據
具體命令如下:
encode 城市,gen(city)
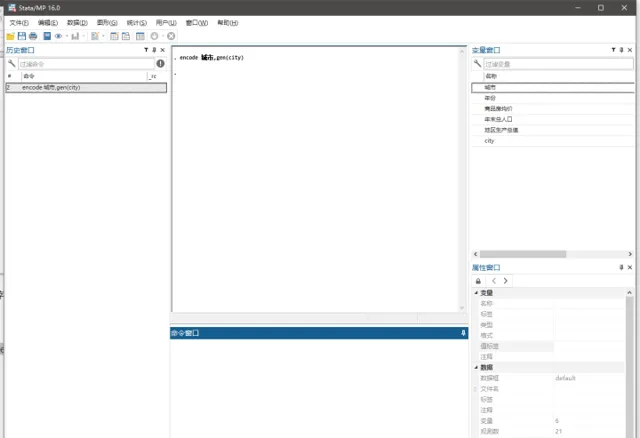
這個命令中 encode為命令的名字,其作用是將字元數據轉換為數值型。而gen為生成的意思,實際上是生成一個新變量。如果你的城市是以數值如1,2,3,4來命名的,則可以省略這一步
緊接著,可以用xtset來聲明面板模型的截面和時間
在stata裏,x代表個體或截面(在計量中和paper裏,個體一般用n或i來表示,面板的模型的公式角標一般是it或者nt),t代表時間,set便是設定的意思。在stata裏,一般與面板相關的命令都會以xt開頭
輸入xtset city 年份
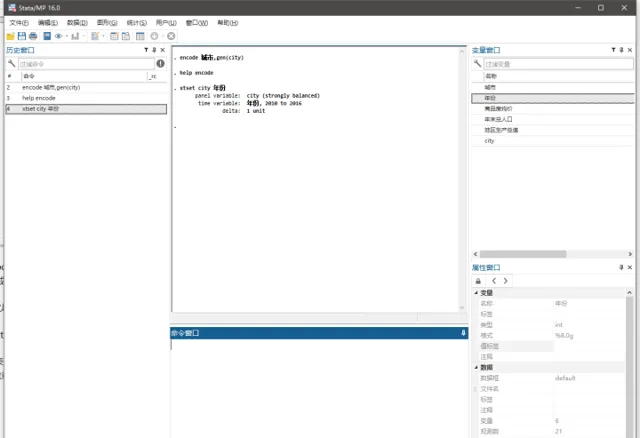
則會發現,stata提示我們的panel變量,也就是個體為city,而時間跨度為2010至2016,如果每個城市每個年份均有數據,則為strongly balanced,即平衡面板,如果缺失數據,則為非平衡面板
接著我們就可以著手跑第一個面板模型了,輸入:
xtreg 商品房均價 年末總人口 地區生產總值,fe
則可以得到如下結果:
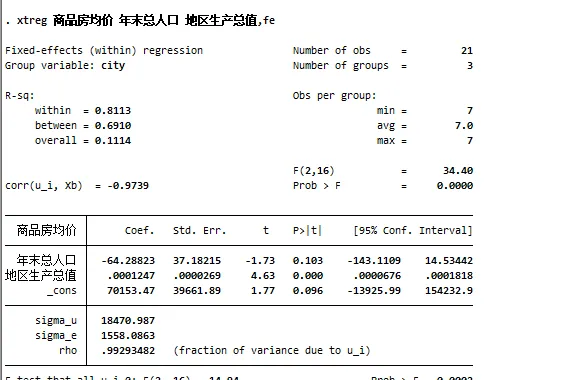
此時我們便得到了第一個面板個體固定效應模型的結果
其中xtreg表示我們執行的面板模型,在stata裏,第一個出現的變量一定是y變量,也就是被解釋變量,而後面的變量均為x變量,因此在這個模型裏,商品房價格為Y變量,人口和地區生產總值為X變量
在stata裏,逗號後面一般跟隨的都是命令的選項,你可以透過不同的選項來調節模型。我們的命令裏,fe代表fixed effects,即個體固定效應模型
在上述結果中,最為重要的是t檢驗的p值,即P>|t|這一列,可以發現,年末總人口的P值為0.103,這一般認為是不顯著的結果。而地區生產總值為0.000,意味著其在1%水平上透過了顯著性檢驗,可以認為地區生產總值直接與商品房房價有關。(一般P值小於0.1為10%顯著,0.05為5%顯著,小於0.01為1%顯著,在論文裏一般用星號代替,分別為*, ** , ***)
值得註意的是,面板模型不需要在意R2,因此R-sq的數值並不重要,這個後續的文章再講原因。而_cons為常數項,不需要特別的解釋
需要關註的是coef.這一列,對於P>|t|顯著的,如變量「地區生產總值」可以這樣解釋:北京上海廣州三個城市地區生產總值每上漲1萬元,商品房房價上漲0.0001247元
但是這樣解釋看起來,很奇怪,因為一來系數非常的小,感覺很不直觀,二來並不能反映出邊際效應的變化
因此,需要將y和x兩邊取對數,一來縮小因次,二來轉換為邊際效應,也可以稱為彈性
stata裏輸入
gen ln商品房均價=log( 商品房均價 )gen ln年末總人口 =log( 年末總人口 )gen ln地區生產總值 =log( 地區生產總值 )
即可生成三個變量的對數形式:

計量模型一定要用自然對數,stata裏,log和ln都會取以e為底的自然對數。而excel裏取對數的公式,用ln是自然對數,用log是以10為底的對數,是不一樣的(一個小坑)
再次執行面板模型的命令:
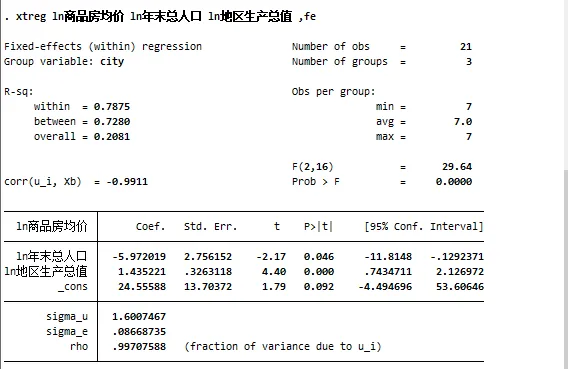
可以發現,系數coef.的數值一下子變得好解釋了。當然也會發現,年末總人口的P值小於了0.05,透過了顯著性檢驗。這是由於許多社會經濟數據本身是右偏的,而取對數可以將其轉換為正態分布,從而修正異變異數性,這部份會後續再詳細解釋(挖坑*1)
而此時,模型則可以這樣解釋:
當北上廣三個城市,人口上升1%,則會導致商品房均價下降5.97%,而地區生產總值上升1%,則商品房價格會上升1.43%
有些時候,結果不是我們想要的,可能是我們的數據結構和樣本選取導致的。面板模型是一個大樹,後面根據不同的數據結構會出現不同的分支。對於個體多於時間的數據,則為短面板,一般為大N小T,而個體少於時間的數據,則為長面板,一般被稱為小N大T。我們這個模型只有3個城市,但時間跨度為7年,顯然屬於長面板範疇,則需要特殊的處理,這個後續再補(挖坑*2)
對於本科生來說,采用短面板是比較好的選擇,對於碩士生來說,長面板可以進行許多高階操作以滿足實證的復雜度需要,如變系數模型或動態面板(挖坑*3)
模型需要做Hausman檢驗以在隨機和固定效應兩種不同的模型中進行選擇,這會在下一期文章中講解(挖坑*4)
而遺漏變量和內生性問題也可能會導致我們得不到想要的結果,這時候則需要一些高級的方法如工具變量法來處理(挖坑*5)
但是對於許多想要快速進行實證分析的本科生和碩士生來說,這篇文章算是一個好的入門了
等不了更新的同學也可以購買這本書
雖說這本書有些內容比如空間計量等章節都過時了,理論部份寫的馬馬虎虎,但是Stata的基礎操作還是寫的很透徹的
我的個人公眾號已上線,各位大佬可以隨意添加,歡迎向我提問哦











