Simultaneous Localization and Mapping - 同步定位與建圖
1. 【SLAM】Incremental Visual-Inertial 3D Mesh Generation with Structural Regularities
【同步定位與建圖】具有結構規律的增量視覺慣性 3D 網格生成
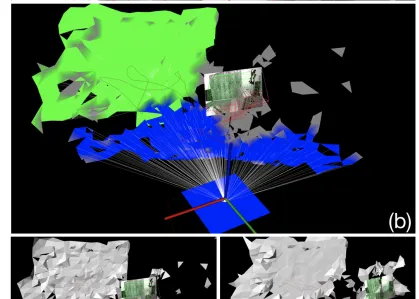
作者:Antoni Rosinol, Torsten Sattler, Marc Pollefeys, Luca Carlone
連結:
https:// arxiv.org/abs/1903.0106 7v2
程式碼:
https:// github.com/ToniRV/Kimer a-VIO-Evaluation
https:// github.com/MIT-SPARK/Ki mera
英文摘要:
Visual-Inertial Odometry (VIO) algorithms typically rely on a point cloud representation of the scene that does not model the topology of the environment. A 3D mesh instead offers a richer, yet lightweight, model. Nevertheless, building a 3D mesh out of the sparse and noisy 3D landmarks triangulated by a VIO algorithm often results in a mesh that does not fit the real scene. In order to regularize the mesh, previous approaches decouple state estimation from the 3D mesh regularization step, and either limit the 3D mesh to the current frame or let the mesh grow indefinitely. We propose instead to tightly couple mesh regularization and state estimation by detecting and enforcing structural regularities in a novel factor-graph formulation. We also propose to incrementally build the mesh by restricting its extent to the time-horizon of the VIO optimization; the resulting 3D mesh covers a larger portion of the scene than a per-frame approach while its memory usage and computational complexity remain bounded. We show that our approach successfully regularizes the mesh, while improving localization accuracy, when structural regularities are present, and remains operational in scenes without regularities.
中文摘要:
視覺慣性裏程計(VIO)演算法通常依賴於場景的點雲表示,它不會對環境的拓撲結構進行建模。相反,3D網格提供了更豐富但更輕量級的模型。然而,從透過VIO演算法三角剖分的稀疏和嘈雜的3D地標構建3D網格通常會導致網格不適合真實場景。為了對網格進行正則化,以前的方法將狀態估計與3D網格正則化步驟分離,或者將3D網格限制到當前幀,或者讓網格無限增長。相反,我們建議透過在新的因子圖公式中檢測和執行結構規律來緊密耦合網格正則化和狀態估計。我們還建議透過將其範圍限制在VIO最佳化的時間範圍內來逐步構建網格;生成的3D網格覆蓋了比逐幀方法更大的場景部份,而其記憶體使用和計算復雜度仍然有限。我們展示了我們的方法成功地規範了網格,同時提高了定位精度,當存在結構規律時,並且在沒有規律的場景中保持操作。
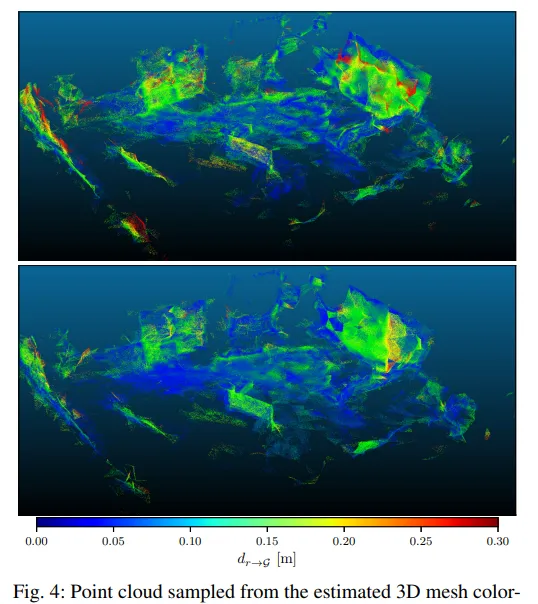
2. 【SLAM】LiDARTag: A Real-Time Fiducial Tag System for Point Clouds
【同步定位與建圖】LiDARTag:點雲的即時基準標記系統
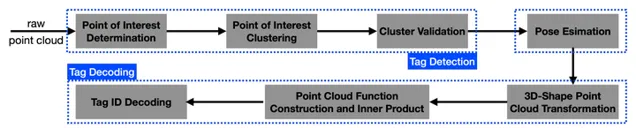
作者:Jiunn-Kai Huang, Shoutian Wang, Maani Ghaffari, Jessy W. Grizzle
連結:
https:// arxiv.org/abs/1908.1034 9v3
程式碼:
https:// github.com/UMich-BipedL ab/extrinsic_lidar_camera_calibration
https:// github.com/UMich-BipedL ab/LiDARTag
英文摘要:
Image-based fiducial markers are useful in problems such as object tracking in cluttered or textureless environments, camera (and multi-sensor) calibration tasks, and vision-based simultaneous localization and mapping (SLAM). The state-of-the-art fiducial marker detection algorithms rely on the consistency of the ambient lighting. This paper introduces LiDARTag, a novel fiducial tag design and detection algorithm suitable for light detection and ranging (LiDAR) point clouds. The proposed method runs in real-time and can process data at 100 Hz, which is faster than the currently available LiDAR sensor frequencies. Because of the LiDAR sensors' nature, rapidly changing ambient lighting will not affect the detection of a LiDARTag; hence, the proposed fiducial marker can operate in a completely dark environment. In addition, the LiDARTag nicely complements and is compatible with existing visual fiducial markers, such as AprilTags, allowing for efficient multi-sensor fusion and calibration tasks. We further propose a concept of minimizing a fitting error between a point cloud and the marker's template to estimate the marker's pose. The proposed method achieves millimeter error in translation and a few degrees in rotation. Due to LiDAR returns' sparsity, the point cloud is lifted to a continuous function in a reproducing kernel Hilbert space where the inner product can be used to determine a marker's ID. The experimental results, verified by a motion capture system, confirm that the proposed method can reliably provide a tag's pose and unique ID code. The rejection of false positives is validated on the Google Cartographer indoor dataset and the Honda pD outdoor dataset.
中文摘要:
基於影像的基準標記在雜亂或無紋理環境中的物件跟蹤、相機(和多傳感器)校準任務以及基於視覺的同時定位和對映(SLAM)等問題中非常有用。最先進的基準標記檢測演算法依賴於環境照明的一致性。本文介紹了LiDARTag,一種適用於光檢測和測距(LiDAR)點雲的新型基準標簽設計和檢測演算法。所提出的方法即時執行,可以處理100Hz的數據,這比目前可用的LiDAR傳感器頻率更快。由於LiDAR傳感器的特性,快速變化的環境照明不會影響LiDARTag的檢測;因此,所提出的基準標記可以在完全黑暗的環境中執行。此外,LiDARTag很好地補充並相容現有的視覺基準標記,例如AprilTags,允許高效的多傳感器融合和校準任務。我們進一步提出了最小化點雲和標記樣版之間的擬合誤差的概念,以估計標記的姿勢。所提出的方法實作了毫米的平移誤差和幾度的旋轉。由於激光雷達返回的稀疏性,點雲被提升為再現內核希爾伯特空間中的連續函數,其中內積可用於確定標記的ID。透過運動捕捉系統驗證的實驗結果證實,所提出的方法可以可靠地提供標簽的姿勢和唯一的ID碼。在Google Cartographer室內數據集和Honda pD室外數據集上驗證了拒絕誤報。

3. 【SLAM】3D Dynamic Scene Graphs: Actionable Spatial Perception with Places, Objects, and Humans
【同步定位與建圖】3D 動態場景圖:對地點、物體和人類的可操作空間感知
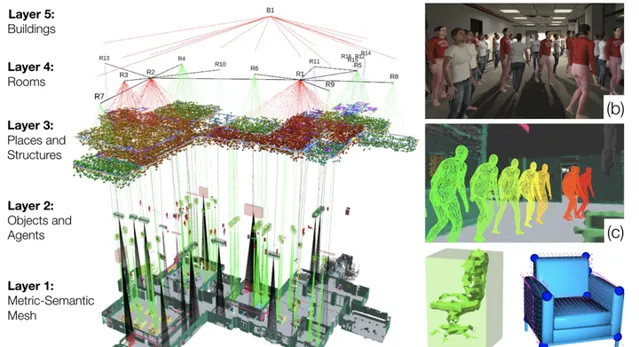
作者:Antoni Rosinol, Arjun Gupta, Marcus Abate, Jingnan Shi, Luca Carlone
連結:
https:// arxiv.org/abs/2002.0628 9v2
程式碼:
https:// github.com/ToniRV/Kimer a-VIO-Evaluation
https:// github.com/MIT-SPARK/Ki mera
英文摘要:
We present a unified representation for actionable spatial perception: 3D Dynamic Scene Graphs. Scene graphs are directed graphs where nodes represent entities in the scene (e.g. objects, walls, rooms), and edges represent relations (e.g. inclusion, adjacency) among nodes. Dynamic scene graphs (DSGs) extend this notion to represent dynamic scenes with moving agents (e.g. humans, robots), and to include actionable information that supports planning and decision-making (e.g. spatio-temporal relations, topology at different levels of abstraction). Our second contribution is to provide the first fully automatic Spatial PerceptIon eNgine(SPIN) to build a DSG from visual-inertial data. We integrate state-of-the-art techniques for object and human detection and pose estimation, and we describe how to robustly infer object, robot, and human nodes in crowded scenes. To the best of our knowledge, this is the first paper that reconciles visual-inertial SLAM and dense human mesh tracking. Moreover, we provide algorithms to obtain hierarchical representations of indoor environments (e.g. places, structures, rooms) and their relations. Our third contribution is to demonstrate the proposed spatial perception engine in a photo-realistic Unity-based simulator, where we assess its robustness and expressiveness. Finally, we discuss the implications of our proposal on modern robotics applications. 3D Dynamic Scene Graphs can have a profound impact on planning and decision-making, human-robot interaction, long-term autonomy, and scene prediction.
中文摘要:
我們為可操作的空間感知提出了一個統一的表示:3D動態場景圖。場景圖是有向圖,其中節點表示場景中的實體(例如物件、墻壁、房間),邊表示節點之間的關系(例如包含、鄰接)。動態場景圖(DSG)擴充套件了這一概念,以表示具有移動代理(例如人類、機器人)的動態場景,並包含支持規劃和決策制定的可操作資訊(例如時空關系、不同抽象級別的拓撲)。我們的第二個貢獻是提供第一個全自動空間感知引擎(SPIN),以從視覺慣性數據構建DSG。我們整合了用於物體和人類檢測以及姿勢估計的最先進技術,並描述了如何在擁擠的場景中穩健地推斷物體、機器人和人類節點。據我們所知,這是第一篇協調視覺慣性SLAM和密集人體網格跟蹤的論文。此外,我們提供演算法來獲得室內環境(例如地點、結構、房間)及其關系的分層表示。我們的第三個貢獻是在逼真的基於Unity的模擬器中演示所提出的空間感知引擎,我們在其中評估其魯棒性和表現力。最後,我們討論了我們的提議對現代機器人套用的影響。3D動態場景圖可以對規劃和決策、人機互動、長期自主和場景預測產生深遠的影響。

4. 【SLAM】DXSLAM: A Robust and Efficient Visual SLAM System with Deep Features
【同步定位與建圖】DXSLAM:具有深度特征的強大且高效的視覺 SLAM 系統
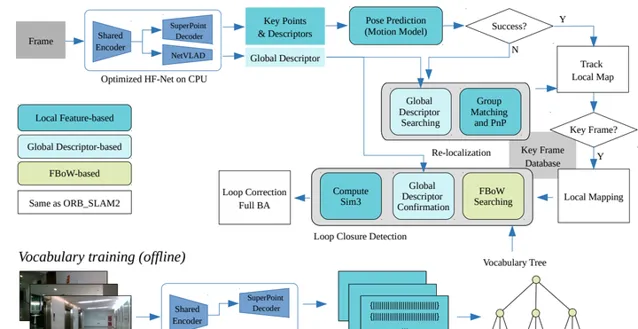
作者:Dongjiang Li, Xuesong Shi, Qiwei Long, Shenghui Liu, Wei Yang, Fangshi Wang, Qi Wei, Fei Qiao
連結:
https:// arxiv.org/abs/2008.0541 6v1
程式碼:
https:// github.com/cedrusx/dxsl am_ros
https:// github.com/ivipsourceco de/dxslam
英文摘要:
A robust and efficient Simultaneous Localization and Mapping (SLAM) system is essential for robot autonomy. For visual SLAM algorithms, though the theoretical framework has been well established for most aspects, feature extraction and association is still empirically designed in most cases, and can be vulnerable in complex environments. This paper shows that feature extraction with deep convolutional neural networks (CNNs) can be seamlessly incorporated into a modern SLAM framework. The proposed SLAM system utilizes a state-of-the-art CNN to detect keypoints in each image frame, and to give not only keypoint descriptors, but also a global descriptor of the whole image. These local and global features are then used by different SLAM modules, resulting in much more robustness against environmental changes and viewpoint changes compared with using hand-crafted features. We also train a visual vocabulary of local features with a Bag of Words (BoW) method. Based on the local features, global features, and the vocabulary, a highly reliable loop closure detection method is built. Experimental results show that all the proposed modules significantly outperforms the baseline, and the full system achieves much lower trajectory errors and much higher correct rates on all evaluated data. Furthermore, by optimizing the CNN with Intel OpenVINO toolkit and utilizing the Fast BoW library, the system benefits greatly from the SIMD (single-instruction-multiple-data) techniques in modern CPUs. The full system can run in real-time without any GPU or other accelerators.
中文摘要:
強大且高效的同時定位和對映(SLAM)系統對於機器人自主性至關重要。對於視覺SLAM演算法,雖然大部份方面的理論框架已經建立,但在大多數情況下特征提取和關聯仍然是經驗性設計的,並且在復雜環境中可能容易受到攻擊。本文表明,使用深度摺積神經網絡(CNN)進行特征提取可以無縫整合到現代SLAM框架中。所提出的SLAM系統利用最先進的CNN來檢測每個影像幀中的關鍵點,並且不僅給出關鍵點描述符,而且給出整個影像的全域描述符。然後,這些局部和全域特征被不同的SLAM模組使用,與使用手工制作的特征相比,對環境變化和視點變化的魯棒性要強得多。我們還使用詞袋(BoW)方法訓練局部特征的視覺詞匯。基於局部特征、全域特征和詞匯,構建了一種高可靠的閉環檢測方法。實驗結果表明,所有提出的模組都顯著優於基線,整個系統在所有評估數據上實作了更低的軌跡誤差和更高的正確率。此外,透過使用英特爾OpenVINO工具包最佳化CNN並利用FastBoW庫,系統極大地受益於現代CPU中的SIMD(單指令多數據)技術。整個系統無需任何GPU或其他加速器即可即時執行。

5. 【SLAM】Semantic Histogram Based Graph Matching for Real-Time Multi-Robot Global Localization in Large Scale Environment
【同步定位與建圖】大規模環境下基於語意直方圖的即時多機器人全域定位圖匹配
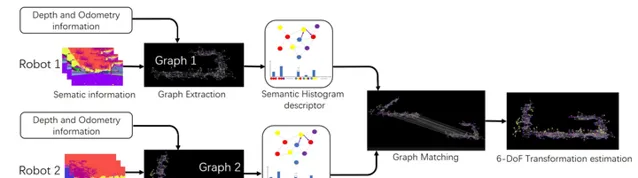
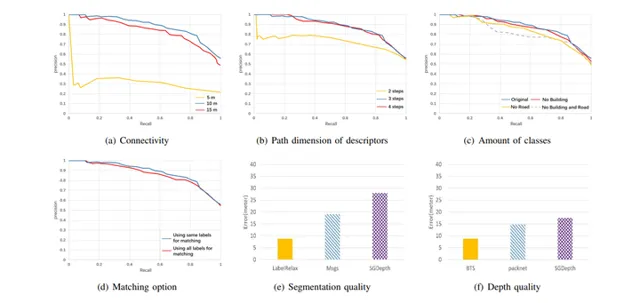
作者:Xiyue Guo, Junjie Hu, Junfeng Chen, Fuqin Deng, Tin Lun Lam
連結:
https:// arxiv.org/abs/2010.0929 7v2
程式碼:
https:// github.com/gxytcrc/sema ntic-histogram-based-global-localization
https:// github.com/gxytcrc/Sema ntic-Graph-based--global-Localization
英文摘要:
The core problem of visual multi-robot simultaneous localization and mapping (MR-SLAM) is how to efficiently and accurately perform multi-robot global localization (MR-GL). The difficulties are two-fold. The first is the difficulty of global localization for significant viewpoint difference. Appearance-based localization methods tend to fail under large viewpoint changes. Recently, semantic graphs have been utilized to overcome the viewpoint variation problem. However, the methods are highly time-consuming, especially in large-scale environments. This leads to the second difficulty, which is how to perform real-time global localization. In this paper, we propose a semantic histogram-based graph matching method that is robust to viewpoint variation and can achieve real-time global localization. Based on that, we develop a system that can accurately and efficiently perform MR-GL for both homogeneous and heterogeneous robots. The experimental results show that our approach is about 30 times faster than Random Walk based semantic descriptors. Moreover, it achieves an accuracy of 95% for global localization, while the accuracy of the state-of-the-art method is 85%.
中文摘要:
視覺多機器人同時定位與建圖(MR-SLAM)的核心問題是如何高效、準確地執行多機器人全域定位(MR-GL)。困難是雙重的。首先是對於顯著視點差異的全域定位困難。基於外觀的定位方法在大的視點變化下往往會失敗。最近,語意圖已被用於克服視點變化問題。然而,這些方法非常耗時,尤其是在大規模環境中。這就引出了第二個難點,即如何進行即時全域定位。在本文中,我們提出了一種基於語意直方圖的圖匹配方法,該方法對視點變化具有魯棒性,並且可以實作即時全域定位。在此基礎上,我們開發了一個系統,可以為同質和異質機器人準確高效地執行MR-GL。實驗結果表明,我們的方法比基於隨機遊走的語意描述符快約30倍。此外,它實作了95%的全域定位準確率,而最先進方法的準確率為85%。
AI&R是人工智能與機器人垂直領域的綜合資訊平台。我們的願景是成為通往AGI(通用人工智能)的高速公路,連線人與人、人與資訊,資訊與資訊,讓人工智能與機器人沒有門檻。
歡迎各位AI與機器人愛好者關註我們,每天給你有深度的內容。
微信搜尋公眾號【AIandR艾爾】關註我們,獲取更多資源❤biubiubiu~








