BEVFormer 的第一版程式碼開源了(2022/06/13):
BEVFormer很榮幸參與到最近這波BEV感知的研究浪潮中,我們從開源社區中受益良多,也希望盡我們所能為社區做出我們自己的貢獻,希望未來與社區一道共同構建更加安全可靠的自動駕駛感知系統。
TL; DR: 本文提出了一套基於Transformer和時序模型在鳥瞰圖視角下最佳化特征的環視物體檢測方案,即BEVFormer。nuScenes數據集上以NDS指標(類似mAP),在camera only賽道中 大幅領先 之前方法。本文旨在介紹我們在設計BEVFormer過程中考慮的思路、比較的多種方法、以及下一步可能的研究方向。
(未經授權,禁止轉載 或 需要申請轉載)
介紹
最近,基於多視角網絡攝影機的3D目標檢測在鳥瞰圖下的感知(Bird's-eye-view Perception, BEV Perception) 吸引了越來越多的註意力。一方面,將不同視角在BEV下統一與表征是很自然的描述,方便後續規劃控制模組任務;另一方面,BEV下的物體沒有影像視角下的尺度(scale)和遮擋(occlusion)問題。如何優雅的得到一組BEV下的特征描述,是提高檢測效能的關鍵。
nuScenes自動駕駛數據集因其數據的質素、規模與難度都比之前數據集有大幅提升,而獲得了很多研究者的關註。在nuScenes 3D object detection task上,目前前6名方案都是2022年3月進行的送出。 我們提出的BEVFormer取得了48.1 mAP和56.9 NDS,兩個指標均超越現有方法3個點以上,暫列第一。 「低碳版」BEVFormer-pure僅使用ResNet-101與單尺度測試,取得了優於第二名(Swin-B、test-time aug)的mAP以及相同的NDS。具體榜單和Demo影片如下。
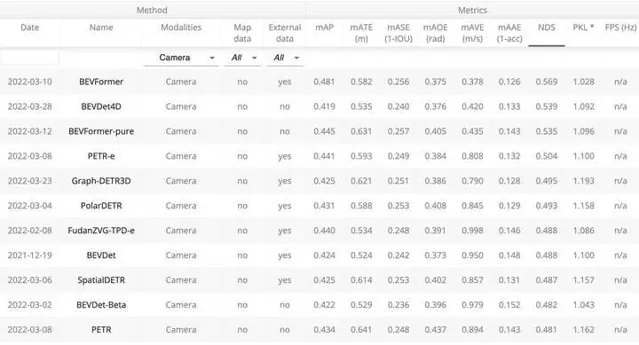
 bevformer.pm4
https://www.zhihu.com/video/1496231642200637440
bevformer.pm4
https://www.zhihu.com/video/1496231642200637440
Demo: BEVFormer,一種全新的環視目標檢測方案
本專案最早啟發於2021年7月特斯拉的技術分享會,為此我們還做了幾期細致的分享(連結TODO)。特斯拉展示了基於Transformer使用純視覺輸入進行自動駕駛感知任務的驚艷效果,但是它並沒有展示其方法的具體實作和量化指標。與此同時,學術界也有許多相關工作旨在利用純視覺輸入來完成自動駕駛感知任務,例如3D目標檢測或者構建語意地圖。我們提出的BEVFormer的主要貢獻在於 使用Transformer在BEV空間下進行時空資訊融合。
BEVFormer方案
動機
在介紹BEVFormer的具體方案之前,先要回答兩個問題。
1: 為什麽要用BEV?
事實上對於基於純視覺的3D檢測方法,基於BEV去做檢測並不是主流做法。在nuScenes 榜單上很多效果很好的方法(例如DETR3D, PETR)並沒有顯式地引入BEV特征。從影像生成BEV實際上是一個ill-posed問題,如果先生成BEV,再利用BEV進行檢測容易產生復合錯誤。但是我們仍然堅持生成一個顯式的BEV特征,原因是因為一個顯式的BEV特征非常適合用來融合時序資訊或者來自其他模態的特征,並且能夠同時支撐更多的感知任務。
2: 為什麽要用時空融合?
時序資訊對於自動駕駛感知任務十分重要,但是現階段的基於視覺的3D目標檢測方法並沒有很好的利用上這一非常重要的資訊。時序資訊一方面可以作為空間資訊的補充,來更好的檢測當前時刻被遮擋的物體或者為定位物體的位置提供更多參考資訊。除此之外時序資訊對於判斷物體的運動狀態十分關鍵,先前基於純視覺的方法在缺少時序資訊的條件下幾乎無法有效判斷物體的運動速度。
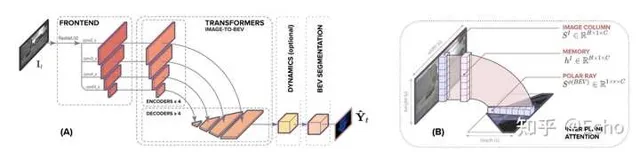
BEVFormer Pipeline
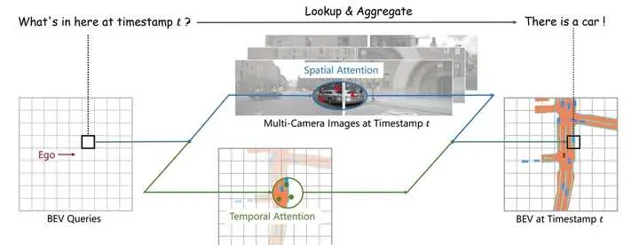
1. 定義BEV queries
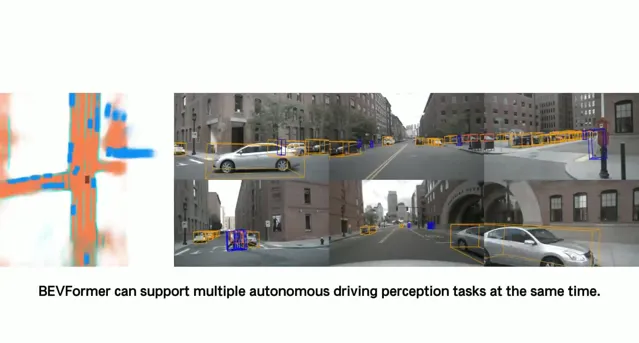
我們定義了一組維度為H*W*C的可學習參數作為BEV queries, 用來捕獲BEV特征。在nuScenes數據集上,BEV queries 的空間分辨率為200*200,對應自車周圍100m*100m的範圍。BEV queries 每個位於(x, y)位置的query都僅負責表征其對應的小範圍區域。BEV queries 透過對spatial space 和 tempoal space 輪番查詢從而能夠將時空資訊聚合在BEV query特征中。最終我們將BEV queries 提取的到的特征視為BEV 特征,該BEV特征能夠支持包括3D 目標檢測和地圖語意分割在內的多種自動駕駛感知任務。
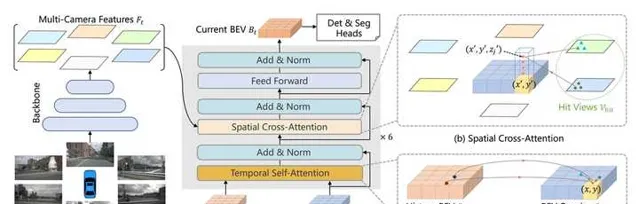
2. Spatial Cross-Attention
如上圖(b)所示,我們設計了一中空間交叉註意力機制,使BEV queries 從多相機特征中透過註意力機制提取所需的空間特征。由於本方法使用多尺度的影像特征和高分辨率的BEV特征,直接使用最樸素的global attention 會帶來無法負擔的計算代價。因此我們使用了一種基於deformable attention 的稀疏註意力機制時每個BEV query之和部份影像區域進行互動。具體而言,對於每一個位於(x, y)位置的BEV特征,我們可以計算其對應現實世界的座標x',y'。 然後我們將BEV query進行lift 操作,獲取在z軸上的多個3D points。 有了3D points, 就能夠透過相機內外參獲取3D points 在view 平面上的投影點。受到相機參數的限制,每個BEV query 一般只會在1-2個view上有有效的投影點。基於Deformable Attention, 我們以這些投影點作為參考點,在周圍進行特征采樣,BEV query使用加權的采樣特征進行更新,從而完成了spatial 空間的特征聚合。
3. Temporal Self-Attention
從經典的RNN網絡獲得啟發,我們將BEV 特征視為類似能夠傳遞序列資訊的memory。 每一時刻生成的BEV特征都從上一時刻的BEV特征獲取了所需的時序資訊,這樣保證能夠動態獲取所需的時序特征,而非像堆疊不同時刻BEV特征那樣只能獲取定長的時序資訊。具體而言,給定上一時刻的BEV 特征,我們首先根據ego motion 來將上一時刻的BEV特征和當前時刻進行對齊,來確保同一位置的特征均對應於現實世界的同一位置。對於當前時刻位於(x, y)出的BEV query, 它表征的物體可能靜態或者動態,但是我們知道它表征的物體在上一時刻會出現在(x, y)周圍一定範圍內,因此我們再次利用deformable attention 來以(x, y)作為參考點進行特征采樣。我們並沒有顯式地設計遺忘門,而是透過attention 機制中的attention wights來平衡歷史時序特征和當前BEV特征的融合過程。每個BEV query 既透過spatial cross-attention 在spatial space下聚合空間特征,還能夠透過temporal self-attention 聚合時序特征,這個過程會重復多次確保時空特征能夠相互促進,進行更精準的特征融合。
4. 使用BEV特征支撐多種感知任務
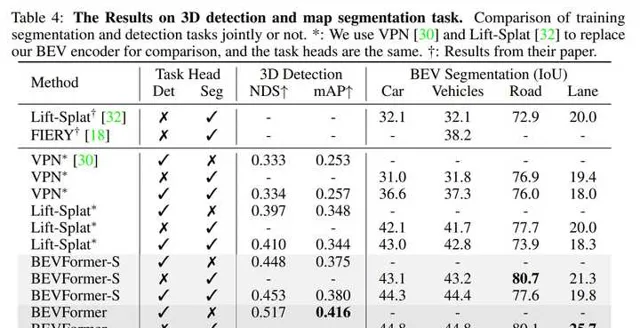
一個顯式的BEV特征能夠被用於3D目標檢測和地圖語意分割任務上。 常用的2D檢測網絡,都可以透過很小的修改遷移到3D檢測上。我們也驗證了使用相同的BEV特征同時支持3D目標檢測和地圖語意分割,實驗表明多工學習能夠提升在3D檢測上的效果。
實驗效果
我們在nuScenes上的實驗結果表明了BEVFormer的有效性。在其他條件完全一致下,使用時序特征的BEVFormer比不使用時序特征的BEVFormer-S 在NDS指標上高7個點以上。尤其是 引入時序資訊之後,基於純視覺的模型真正能夠預測物體的移動速度,這對於自動駕駛任務來說意義重大。
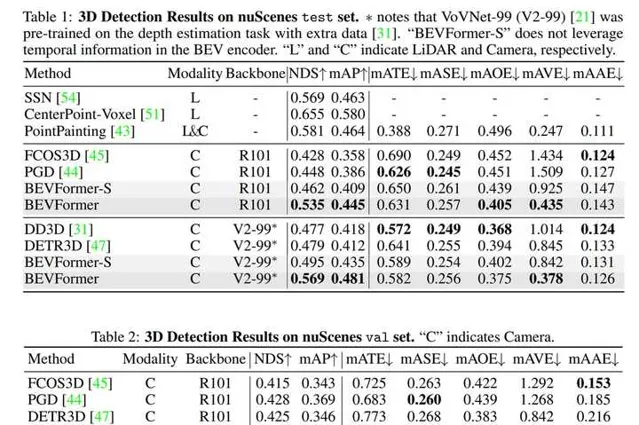
我們還證明了模型同時做檢測和分割任務能夠提升在3D檢測任務上的效能,基於同一個BEV特征進行多工學習, 意義不僅僅在於提升訓練和推理是的效率,更在於基於同一個BEV特征,多種任務的感知結果一致性更強,不易出現分歧。
在下面這個場景下,BEVFormer基於純視覺輸入得到的檢測結果跟真實結果十分接近, 再BEV視角下的分割結果和檢測結果也有著非常好的一致性。

相關工作
自動駕駛場景中,基於BEV空間的感知系統能夠給系統帶來巨大的提升。在經典的自動駕駛感知系統中,camera感知演算法工作在2D空間,LiDAR/RaDAR感知演算法工作在3D空間。下遊的融合演算法透過2D與3D之間的幾何關系對感知結果進行融合。由於融合演算法僅對感知結果進行融合,會遺失大量的原始資訊,同時手工設計的對應關系難以應對復雜的場景。在基於BEV空間的感知系統中,Camera,LiDAR,RaDAR的感知均在BEV空間中進行,有利於多模態感知融合。而且,融合過程較傳統方法提前,能充分利用各個傳感器的資訊,提升感知效能。將camera feature從仿射視角perspective轉換到鳥瞰圖BEV視角,一般使用IPM(inverse perspective mapping) 和MLP (multi-layer perception),近來也有工作使用Transformer結構。

BEVFormer正是在特斯拉技術分享會後收到的啟發。TESLA在AI DAY的技術演講中也對基於BEV的檢測進行了介紹,Tesla使用tranformer將不同視角的影像轉換至BEV空間下,再在BEV空間進行物體檢測。詳細技術分享細節參見:BEVFormer。
以BEV為中心的感知方案同樣受到了國產廠商的關註。國產廠商中,地平線和毫末智行均公開展示過其感知方案使用BEV範式。
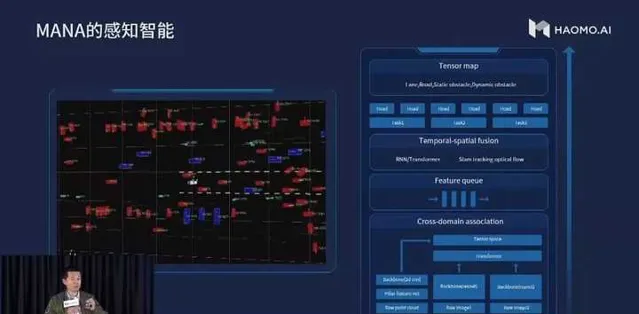
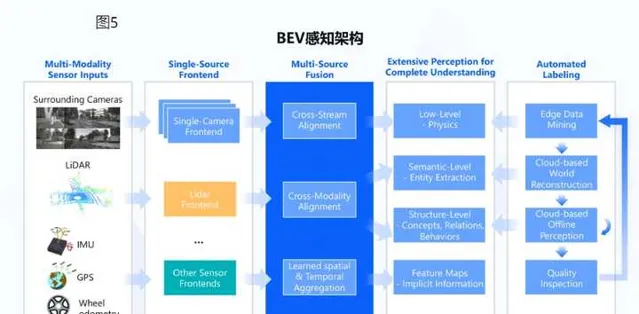
無論地平線還是毫末智行,BEV範式均在其感知系統中起到了重要的作用。神經網絡透過數據驅動,將不同傳感器的數據對映到BEV空間中,繼而根據BEV特征進行空間與時間融合,從而獲取到對場景(空間及時間)的抽象表征。最後由BEV表征出發,輸出不同任務的結果。由於BEV範式感知能大規模利用原始數據進行抽象建模,減少人為設計,感知系統融合效能得到了顯著的提高。可以預見會有越來越多的國產廠商使用BEV這種新型的感知範式。

PYVA使用MLP進行perspective到BEV的轉換,在完成轉換後,再使用一個MLP將BEV feature X'轉換回perspective view,並透過X與X''進行約束。然後使用tranformer融合BEV feature X'和perspective feature X'',再透過數據約束獲得BEV表征。
PYVA由兩個MLP構成,一個將原始特征X從perspective轉換到BEV X',另一個將BEV X'轉換回perspective X",兩個MLP透過X與X''進行約束。然後使用tranformer融合BEV feature X'和perspective feature X'',再透過數據約束獲得BEV表征。
Translateing images into maps發現,無論深度如何,在影像上同一列的像素在BEV下均沿著同一條射線,因此,可以將每一列轉換到BEV構建BEV feature map。作者將影像中每一列encode為memory,利用BEV下射線的半徑query memory,從而獲得BEV feature,最後透過數據監督使模型擁有較好的視角轉換能力。

DETR3D雖然沒有直接使用BEV feature,但DETR3D直接在BEV視角下進行物體檢測。透過解碼的物體三維位置及相機參數,利用2D圖片對應位置的feature不斷refine物體3D位置,從而達到了更好的3D物體檢測效能。
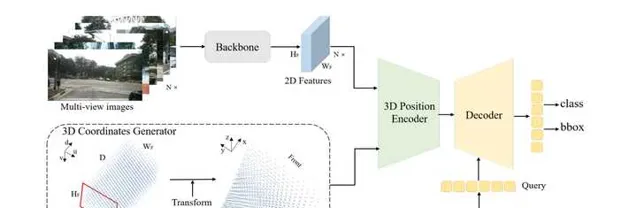
PETR 在DETR3D的基礎上更進一步,為每個2D視角添加了3D位置特征,與之前的Lift-Spalt-Shot類似,PETR使用深度分布來表征每個2D像素潛在的深度資訊。將相機空間下的座標系轉換成世界座標系之後,能為所有視角提供一個統一的3D位置特征。不同於DETR3D, PETR無需讓query回歸3D框的中心點然後投影到2D視角下聚合特征,PETR直接使用類似DETR那樣的全域cross-attention自適應的學習所需特征。
下一步工作
相信讀到這裏的小夥伴都是我們的鐵粉,且堅定相信BEV Perception會是下一代自動駕駛感知演算法框架的主流趨勢。這裏我們也給大家分享下基於BEVFormer的最新思考,希望和業界同仁一起探索這個方向。歡迎各種challenge與comment.
一方面,把BEVFormer擴充套件成 多模態 、與激光雷達 融合 是一個很自然的想法。我們註意到最新的DeepFusion工作也已經揭開其神秘的面紗。這裏面一個關鍵的點是如何正確align Lidar query feature和相機下的特征;在deepFusion實作中,InverseAug是保證特征一致的重要操作。該方法在目前Waymo 3D Detection榜單中也獨占鰲頭。
另一方面,如何以 純視覺 的設定,最佳化當前pipeline, 把效能提升至和Lidar差不多的結果也是一件非常有挑戰的事情。這裏面一個關鍵因素是如何以相機2D的資訊輸入,得到一個準確的3D空間位置估計,即基於影像的(稠密)深度估計。在這方面發力的影響力要遠遠大於單純的Sensor Fusion.











