当 下 A I 编 程 现 状 :

AI 编程一直是人们对人工智能的一大期望,现有的 AI 编程技术虽然已经惠及了许多不会编程的普通用户,但从上图来看,还远没有达到满足人们预期的程度,一大痛点在于:现有 AI 只会进行机械地记忆与复制粘贴,难以灵活处理人们的需求。下面,我们会详细说明现有AI编程技术的发展程度,未来发展的关键,以及微软亚洲研究院在这方面所作出的努力:新型神经网络架构 LANE(Learning Analytical Expressions),可以模拟人类的抽象化思维,从而在 AI 编程中获得组合泛化能力。
从 AI 编程说起
让 AI 学会写程序,是人们的普遍预期:直接用自然语言描述想干什么,AI 就能自动生成相应的程序。现有的 AI 编程技术显然还远达不到这种预期,但相关技术已然在各种特定领域中以更为广泛的形式惠及了大量不会编程的普通用户。例如,微软在 Ignite 2019 大会上展示了Excel 中的一项新功能[1]——只需要向 Excel 提问题,它就能自动理解并进行智能数据分析,并通过可视化图表的方式将结果呈现在你的眼前(如图1所示)。这个超实用功能背后的技术支撑正是一系列将自然语言转换为数据分析程序的 AI 编程技术。而另一个例子是微软 Semantic Machines 团队研发的智能对话服务,其产品化方案正是基于程序合成的[2]。
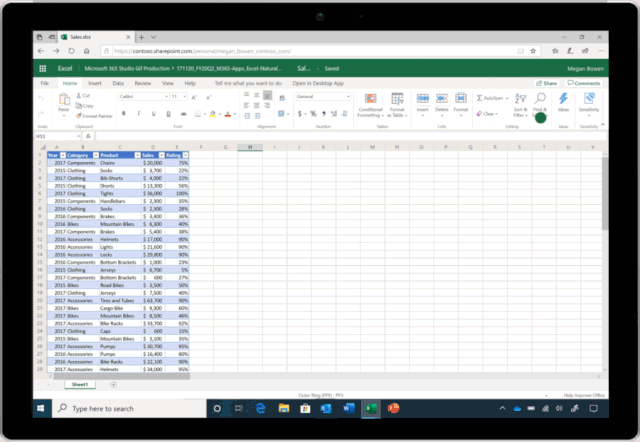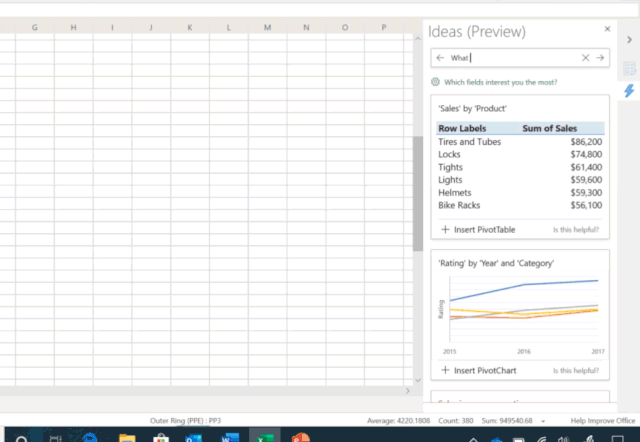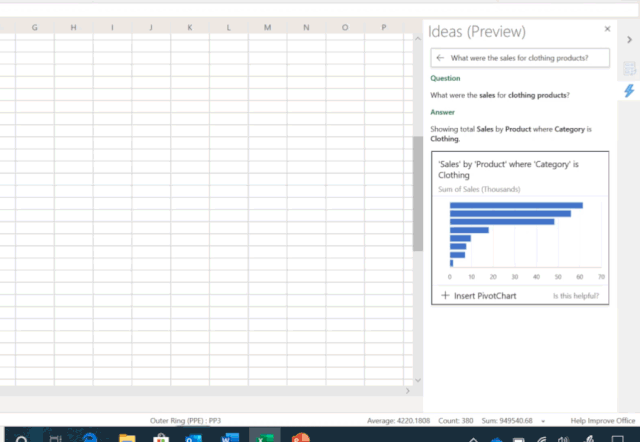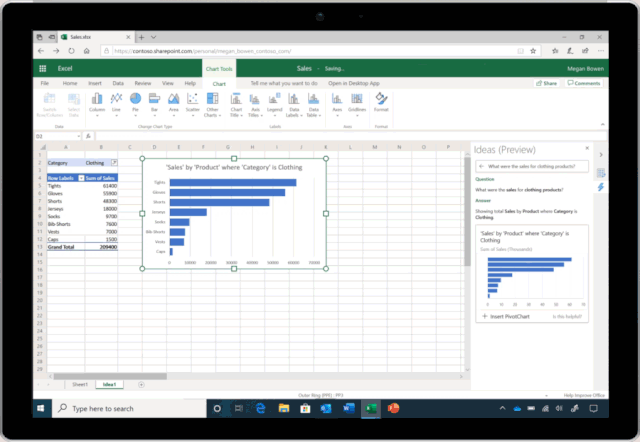
本文所讨论的「AI 编程技术」,指的是以一个自然语言句子作为输入,自动生成一段相应的机器可解释/可执行的程序作为输出。这里的程序通常是由一个已知的 DSL(Domain Specific Language,领域特定语言)所编写。自然语言处理领域的研究者可能更熟悉这一任务的另一称谓:语义解析(Semantic Parsing)。
然而,即使是在这样的限定下,现有的 AI 编程技术也并不总能让人满意。一大痛点在于,它们似乎只学会了从已知的代码库中进行机械地记忆与复制粘贴,却难以为人类灵活多变的需求生成真正合适的程序。
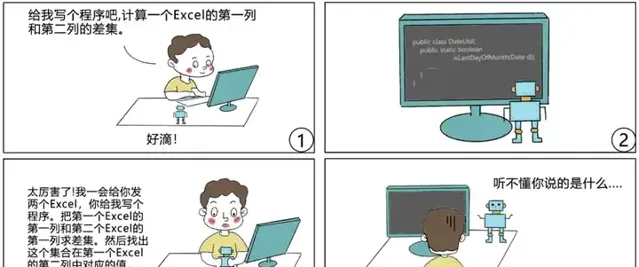
以图2漫画(改编自[3])为例,当用户提出的需求相对简单,且这个 AI 编程机器人可以在某个大代码库中找到能够实现这一需求的程序时,效果通常是不错的。但是如果用户提出的需求相对复杂,要求 AI 编程机器人具有一定的推理能力(所需的程序在已知代码库中并不存在,需要对一些已有的程序片段进行复合生成),在这种情况下的效果通常是比较糟糕的。
本回答所介绍的研究工作正是以此为出发点,旨在探索如何让 AI 编程机器人不再只会」复制粘贴」,而是学会类人的推理能力,从而更为有效地合成所需的程序。
组合泛化能力是走向类人 AI 的关键
前面所讨论问题的核心可以归结为 AI 系统的「组合泛化」(Compositional Generalization)能力问题。更通俗地说,就是 AI 系统是否具备「举一反三」的能力:能够将已知的复杂对象(即本文中所讨论的「程序」)解构为多个已知简单对象的组合,并据此理解/生成这些已知简单对象的未知复杂组合。
人类天生具有组合泛化能力。例如,对于一个从没接触过「鸭嘴兽」这个概念的人,只要看一张鸭嘴兽的照片,他就认识它了,并可以在脑海中很有画面感地理解一些复杂句子,比如「三只鸭嘴兽抱着蛋并排坐着」、「两只鸭嘴兽在河里捕食完小鱼之后开始上岸掘土」等。这和深度学习是很不同的,即使是为了学会「鸭嘴兽」这样一个单独的概念,深度学习都需要大量的标注数据,更不用说学会这个概念的各种复杂组合了。
从语言学的角度看, 人类认知的组合泛化能力主要体现在系统性(Systematicity)和生产性(Productivity)上 。系统性可以简单理解为对已知表达式的局部置换。比方说,一个人已经理解了「鸭嘴兽」和「狗在客厅里」,那么他一定能够理解「鸭嘴兽在客厅里」。生产性则可以简单理解为通过一些潜在的普适规律,用相对简单的表达式构造出更复杂的表达式。比方说,一个人已经理解了「鸭嘴兽」和「狗在客厅里」,那么他一定能够理解「鸭嘴兽和狗在客厅里」。
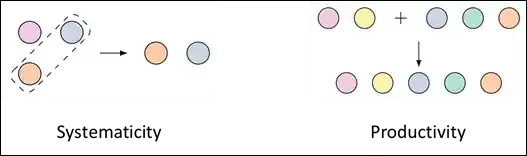
正如语言学家、哲学家乔姆斯基所说,「有限资源,作无穷运用(infinite use of finite means) 」。正是依靠组合泛化能力,人类智能才能够从一些最基础的元素出发,一步一步创造出复杂甚至无限的语义世界。可以说, 组合泛化是类人智能体必须具备的基本能力 。
深度学习缺乏组合泛化能力
程序是具有组合性的,即使是一个很小的 DSL(领域很限定,语法很简单,预定义的函数很有限),也能够产生一个指数爆炸式的巨大程序空间。任何一个训练数据集中所包含的程序,都只是这个指数级程序空间中的冰山一角。因此,若一个 AI 编程机器人缺乏组合泛化能力,则必然会导致如前面漫画所体现的「人工智障」情况。
从这个角度出发,越来越多的研究工作开始重新审视现有的基于深度学习的 AI 编程解决方案。当前主流的解决方案大多基于深度编解码架构(Neural Encoder-Decoder Architectures)。纽约大学教授 Brenden Lake 和 Facebook AI 科学家 Marco Baroni 的一系列研究表明,现有的深度学习模型并不具有组合泛化能力[4]。图4简单展示了他们的研究方法。实验任务是将诸如「run after walk」这样的自然语言句子翻译成诸如「WALK RUN」这样的指令序列(程序)。

表面上看,这是个非常简单的序列到序列生成任务。在收集到大量自然语言句子以及它们所对应的指令序列之后,随机划分成训练集和测试集,用现有的深度学习模型进行训练,即可在测试集上达到99.8%的准确率。然而,一旦从组合性的角度对训练集和测试集的划分方式加以约束,深度学习模型就不再有效。例如,为了验证模型的系统性,可以让模型在训练阶段除了「jump -> JUMP」之外不再接触任何与 jump 有关的样例,而在测试阶段去看模型是否能够在包含 jump 的句子(例如:「jump around left」)上做对。实验结果表明,在这样的设定下,深度学习模型仅能达到1.2%的准确率。
另一方面,为了验证模型的生产性,则可以让模型在训练阶段只接触指令序列长度小于24的样例,而在测试阶段去看模型是否能够正确地生成长度不小于24的指令序列。实验结果表明,在这样的设定下,深度编解码网络仅能达到20.8%的准确率。诸如此类的一系列研究表明,现有的深度学习模型在语义解析任务上不具备组合泛化能力[4][5]。
在当前的工业实践中,从业者主要通过深度学习与人工规则的混合系统来缓解这一瓶颈(数据增广也可以归入其中,因为需要增广哪些数据通常也需要人工归纳)。本文想要探讨一种更有趣的思路:是否能够在深度学习中引入合适的归纳偏置,使之摆脱简单的记忆与模仿,也不需要引入人工规则,而是自动地探索、发现并归纳出数据集中内在的组合性规律,从而使端到端的深度神经网络具备组合泛化能力。
在深度神经网络中模拟人脑的抽象化思维
人类的认知之所以具备组合泛化能力,关键在于抽象化(Abstraction),即省略事物的具体细节,以减少其中所含的信息量,从而更有利于发现事物间的共性(规律)。
这种抽象化能力是一种代数能力,而这正是现有的深度神经网络所缺乏的。如图5左侧所示,对于 AI 编程任务,现有的深度神经网络更倾向于「死记硬背」:自然语言和程序语言被看作是两个集合,那么学习到的只能是具体的自然语言句子和具体的程序之间的简单映射关系,这样自然是难以做到组合泛化的。对于这一问题,关键思路在于,将自然语言和程序语言看作是两个代数结构,且需要 让深度神经网络倾向于学习这两个代数结构之间的同态 (如图5右侧所示)。

更形象地来说,如果训练数据中已经包含「run opposite walk」、「run after left」、 「walk twice」等样例,现在面对如下样例:
INPUT: 「run opposite left after walk twice」
OUTPUT: 「WALK WALK LTURN LTURN RUN」
深度学习模型的实质是记住诸如此类输入输出对之间的映射关系,而人类的认知则倾向于做出如图6所示的抽象化:
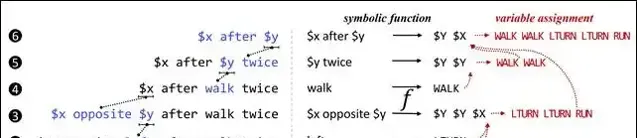
图6的左侧自下而上地给出了对于作为输入的自然语言句子的抽象化过程。在第1、2、4步,分别剥离掉「run」、「left」和「walk」这三个单词的具体属性,将它们抽象为变量;在第3、5、6步,分别剥离掉「$x opposite $y」、「$y twice」和「$x after $y」这三个子句属性,也将它们抽象为变量。人类记住的并非输入与输出之间的直接映射,而是这一抽象化过程中每一步所产生的局部映射(如图6右侧所示)的集合。例如,在第1步中,将单词「run」映射到了程序「RUN」上;在第3步中,将抽象子句「$x opposite $y」映射到了程序「$Y $Y $X」。此处的「$X」是一个程序中的变量,指代自然语言中的变量「$x」所对应的程序;同样地,$Y$亦是一个程序中的变量,指代自然语言中的变量「$y」所对应的程序。
上述例子说明了,相比于直接记住相对复杂的具体映射,人类更倾向于从中归纳出相对简单的共性抽象映射,从而获得组合泛化能力。因此,为了让深度学习也获得组合泛化能力,需要设计一种能够模拟人类认知中的抽象化过程的新型神经网络架构。
将输入/输出的各个具体对象形式化,称为源域表达式(Source Expression, SrcExp)/目标域表达式(Destination Expression, DstExp),统称为表达式(Expression, Exp)。若表达式中的某个/某些子部分被替换为变量,则称这些带变量的表达式为解析表达式(Analytical Expression, AE)。同样地,解析表达式也可分为源域解析表达式(SrcAE)和目标域解析表达式(DstAE)。
对于每个输入的 SrcExp,神经网络架构需要通过若干次抽象化操作逐渐地将其转换为更简单的 SrcAE(如图6左侧所示)。在这一抽象化过程中,每个被置换为变量的 SrcAE 将被解析为一个 DstAE,最终由这些 DstAE 组合形成一个 DstExp 作为输出(如图6右侧所示)。模型需要以这种抽象化过程作为一种归纳偏置,在不依赖任何人工预定义的抽象/映射规则的前提下,完全自动化地完成对具体的抽象化过程与表达式映射的探索与学习。
LANE 的模型实现
新型的神经网络架构 LANE(Learning Analytical Expressions)能够在语义解析任务中模拟人类的抽象化思维,从而获得组合泛化能力 。在之前的神经网络学习框架中,神经网络是直接被用来学习一个从具体的源字串(Source Token Sequence)到具体的目标串(Destination Token Sequence)的映射函数。而在 LANE 中,需要学习的是一个定义域和值域分别是由源字串抽象化后导出的解析表达式和目标串解析表达式的函数。
LANE 由两个神经网络模块构成:一个模块称为 Composer,由一个 TreeLSTM 模型实现,负责对输入的 SrcExp 进行隐式树状归纳(Latent Tree Induction),从而得到逐渐抽象简化的中间 SrcAE;另一个模块称为 Solver,负责在每次抽象发生时进行局部语义解析,将语义细节剥离并保留在记忆单元(Memory)中,从而使得后续处理过程中这些细节被简化为一个变量。
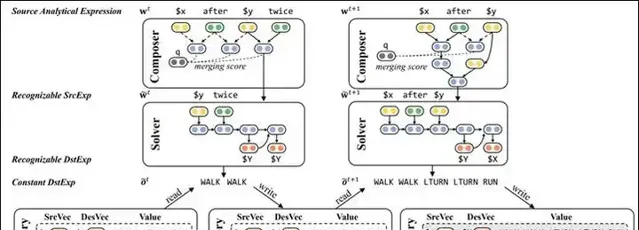
图7解释了 LANE 的工作流程,也展示了 LANE 如何处理图6中的第5步和第6步抽象。在第5步抽象化过程中,对于当前的 SrcAE 「$x after $y twice」,Composer 基于树状 LSTM 输出下一步抽象动作:应该对「$y twice」这个局部进行抽象化。Solver 则使用一个深度编解码网络将「$y twice」解释为 DstAE 「$Y $Y」,与原 Memory 中的「$Y = WALK」结合得到新变量所对应的 DstExp 「WALK WALK」,并以此更新 Memory。经过这一过程,「$x after $y twice」中的「$y twice」这部分细节被剥离掉了,形成了一个抽象程度更高的 SrcAE 「$x after $y」,进而可以开始第6步抽象。通过这样的方式,Composer 与 Solver 协同工作,LANE 将输入的 SrcExp 逐渐抽象为简化程度越来越高的 SrcAE,直到形成一个由单变量构成的最简 SrcAE。该变量在 Memory 中对应的取值即为最终输出的 DstExp。
由于 LANE 中包含不可求导的离散操作,因此可以基于强化学习(Reinforcement Learning)来实现模型的训练。模型训练有如下三个关键点:
1. 奖励(Reward)设计 。Reward 分为两部分:一部分是基于相似度的奖励,即模型生成的 DstExp 与真实的 DstExp 之间的序列相似度;另一部分是基于简洁度的奖励,它是受奥卡姆剃刀原则启发,用于鼓励模型生成更通用/简洁的解析表达式。由于这两个奖励的设计都没有刻意引入任务相关的特别知识,表明 LANE 应该具有很大的普适性。
2. 分层强化学习(Hierarchical Reinforcement Learning)。Composer 和 Solver 协同工作,但地位并不相同:Solver 的决策依赖于 Composer 的决策。因此,将 Composer 和 Solver 分别视作高层代理(High-level Agent)和底层代理(Low-level Agent),应用分层强化学习联合训练这两个模块。
3. 课程学习(Curriculum Learning)。为了加强探索效率,根据 SrcExp 的长度将数据划分为从易到难的多个课程。模型先在最简单的课程上进行训练,而后逐渐将更难的课程加入训练。
实验结果
Lake 等人建立了一套基准数据集 SCAN,用于评测语义解析系统的组合泛化能力[4]。该数据集上衍生出了多个子任务,用于度量不同方面的组合泛化能力。例如,ADD_JUMP 子任务用于度量模型是否能够处理新引入元素的组合;LENGTH 子任务用于度量模型是否能够生成超出训练数据中已知长度的组合。研究实验结果表明,LANE 在这些子任务上均达到了100%的准确度。
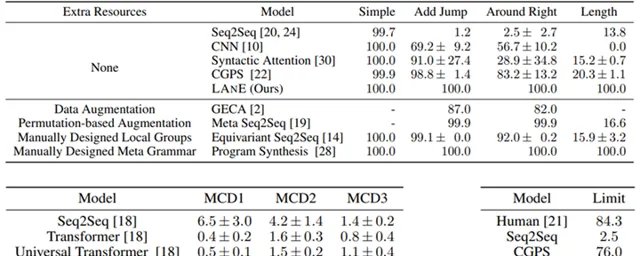
图9展示了 LANE 中的 Composer (TreeLSTM)学习得到的两个隐式树结构作为示例。TreeLSTM 在具体实现时是二叉化的,将具体进行抽象动作的结点着黑色。可以看到,即使并未引入任意人工预定义的抽象/映射规则,LANE 也能够自动化地探索出符合人类思维的抽象化过程。

新型的端到端神经网络架构 LANE 能够模拟人类的抽象化思维能力,以此学习到数据中潜在的解析表达式映射,从而在 AI 编程(语义解析)任务中获得组合泛化能力。微软亚洲研究院的研究员们希望以此作为一个出发点,探讨深度学习如何由 「鹦鹉范式」(记忆与模仿)走向「乌鸦范式」(探索与归纳),从而延伸其能力边界。不过目前这还是初步的理论研究,想要应用到更复杂的任务中还需要很多后续工作(例如,提高训练效率、提高容错学习能力、与无监督方法结合等)。
论文:https:// arxiv.org/abs/2006.1062 7
代码:https:// github.com/microsoft/Co ntextualSP
参考文献
[1] 【智能数据分析技术,解锁Excel「对话」新功能】<https://www. msra.cn/zh-cn/news/feat ures/conversational-data-analysis >[2] 【对话即数据流:智能对话的新方法】<https://www. msra.cn/zh-cn/news/feat ures/dialogue-as-dataflow >
[3] 【朋友送了我一个会编程的机器人,说程序员可以下岗了!!!】<http:// dwz.date/dgNY >
[4] Brenden Lake, Marco Baroni. Generalization without Systematicity: On the Compositional Skills of Sequence-to-Sequence Recurrent Networks. 2018. <https:// arxiv.org/abs/1711.0035 0 >.
[5] Daniel Keysers, et al. Measuring Compositional Generalization: A Comprehensive Method on Realistic Data. 2019. <https:// arxiv.org/abs/1912.0971 3 >
本账号为微软亚洲研究院的官方知乎账号。本账号立足于计算机领域,特别是人工智能相关的前沿研究,旨在为人工智能的相关研究提供范例,从专业的角度促进公众对人工智能的理解,并为研究人员提供讨论和参与的开放平台,从而共建计算机领域的未来。
微软亚洲研究院的每一位专家都是我们的智囊团,你在这个账号可以阅读到来自计算机科学领域各个不同方向的专家们的见解。请大家不要吝惜手里的「邀请」,让我们在分享中共同进步。
也欢迎大家关注我们的微博和微信 (ID:MSRAsia) 账号,了解更多我们的研究。











