-Datawhale干货-
作者: @我想了很多事 ,Datawhale优秀选手
文章原文: 我想了很多事:再一次惨败,讯飞2021关系抽取大赛前十记录。
前言
又一次参加了比赛,这次还是没有拿到特别靠前的位置,靠队友闯入了前十,心里难免失落,但是这也自己实力不足导致,希望再接再厉能取得更好的成绩吧。
分享下本次比赛自己的收获,也希望各位大佬多多交流,本次比赛的赛题是医疗文本中分别抽取出实体跟关系,此类的任务目前应该也算是比较常见的,这里我就想大概介绍下。
此类任务的方法,首先NER的任务应该也有很多的分享与方案,这里笔者之前也做过相关的总结,还没看过的小伙伴可以观看下如下的总结:我这里就大概讲下此次比赛中用到的方法,后续代码也会整理到笔者的Github:
开源:https:// github.com/powerycy/Dee pKg
比赛链接:https:// challenge.xfyun.cn/topi c/info?type=medical-entity
NER部分
Biaffine
NER部分笔者主要运用了两种方法进行实验,首先是目前比较主流的
Mulit-head
,
Biaffine
跟
GlobalPointer
三种方法,而
Mulit-head
的方法因为是线性的变换,笔者这里没有用此方法进行试验,而是直接采样了
Biaffine
的形式进行NER的训练,这里简单介绍下
Biaffine
机制,这里举个例子:
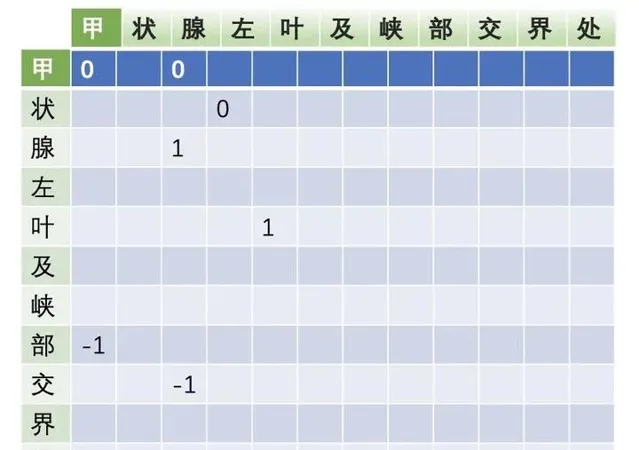
详情请见文章:https:// zhuanlan.zhihu.com/p/37 5805722
通过笔者的实验,发现此方法效果不错,可以作为Base的其中之一来进行使用。而剩下进行一些常规的操作,首先加入了
label_embedding
作为特征,然后通过取
Roberta模型
的后两层跟
CLS层
,一层作为
start
,一层作为end提取出的特征,经过FFNN,而
CLS层
融入到特征中,经过
Biaffine
矩阵,在通过
mask
掉
pad
跟下三角得到最终的
logits
。
此方法是苏神之前介绍的方法效果很好并且速度非常快,苏神在博客做过详细的介绍(笔者在之前的文章也做过介绍),这里就稍加说下:
假设要识别文本序列长度为 ,先假定只有一种实体要识别,并且假定每个待识别实体是该序列的一个连续片段,长度不限,并且可以相互嵌套(两 个实体之间有交集),那么该序列有个不同的连续子序列,这些子序列包含了所有可能的实体。
而我们要做的就是从这个「候选实体」里边挑出真正的实体,其实就是一个「选」的多标签分类问题。这就是GlobalPointer的基本思想,以实体为基本单位进行判别。
笔者也是在此基础上加入了
label_embedding
跟
CLS层
进行NER的训练,最后笔者采用了
GlobalPointer
的方案。
词汇增强已经普遍认为可以提升NER的效果了,笔者这里是首先是把训练集中的词加入词典,并把其拼接到整句话中,然后通过Mask矩阵让整句话不与词进行交互,但词语整句话进行交互。
关于NER部分之前也写过一篇来自腾讯的实验,是来解决未标注实体在NER中带来的问题,笔者也是进行了复现以及跟整个代码进行了一个整合。
关系抽取部分
NER部分笔者之前有一些代码的积累能快速的得到答案,而RE部分笔者这次做的比较的慌张,因为之前笔者并没有在这方面整理出一个体系代码,所以大部分时间也都花费在这个上面。
熟悉RE任务的人应该很清楚,目前关于RE的方法分为Pipeline跟Join的方法,而RE任务目前的重叠问题笔者在这里就简单介绍一下:
一对多问题
,如「周杰伦演唱过【止战之殇】【乱舞春秋】」中,存在2种关系:「周杰伦-歌手-止战之殇」和「周杰伦-歌手-乱舞春秋」
一对实体存在多种关系
,如「周杰伦作曲并演唱【外婆】」中,存在2种关系:「周杰伦-歌手-外婆」和「周杰伦-作曲-外婆」
复杂关系问题
,由实体重叠导致。如【叶圣陶散文选集】中,叶圣陶-作品-叶圣陶散文选集;针对一系列的问题,目前有很多的论文提出了解决方案,比如一些常见的联合抽取模型,联合抽取就是将两个子模型统一建模,以缓解错误传播的缺点,对于联合抽取已经有一系列的研究了。
笔者因为时间原因并没有去尝试比较经典的一些方法,而是采用了近两年比较流行的一些方法,首先映入眼帘的是RE中通用性非常广泛,也是苏神所提出的
CasRel方法
,此方法在各大关系抽取大赛中基本都是常客,非常多的人使用,效果也很强大,笔者之前复现过一个torch的版本:https://
zhuanlan.zhihu.com/p/13
8858558
具体的详情也可去苏神的博客进行观看(笔者在之前的文章也做过介绍),简单概括就是利用概率图的思想:首先预测第一个实体Sub,预测出Sub过后通过
ConditionalLayerNorm
传入Sub的特征在进行多标签分类来得到Relation跟Obj。
而针对此方法以及过往比赛的分享来看主要是进行了如下的改变。
这种方案非常给力,这里也是非常感谢自己的朋友们来跑这种方案,而笔者有更多的精力去做其他的方案,那么还有哪些方案可以来做呢,笔者就来介绍一下首先也是大部分做RE的人也比较熟悉的TPLinker这篇文章,(笔者也进行过一个解读):https:// zhuanlan.zhihu.com/p/34 2300800
简单来说就是为了避免曝光偏差同时抽取出实体与关系,这里笔者之前虽然分享了一篇源码解读,但是因个人能力有限无法对其进行改动,遂放弃,只能自己来造这个轮子。
不过笔者跟
TPLinker
的做法稍有不同,笔者这里主要是采用了两种方式来实现,一个是现在比较流行的
Biaffine
矩阵,另一个是采用苏神的
GlobalPointer
来做,这里笔者两种方法都实验了,
GlobalPointer
的方法略好,并且所占资源较少。
GlobalPointer关系联合抽取
关于
GlobalPointer
的做法是,笔者将关系的首尾也标签化,例如:('甲状腺左叶及峡部交界处 属性 低回声结节')这个三元组笔者将首首跟尾尾作为标签这样在进行抽取的时候把关系跟实体一起抽出来。
在训练的时候也是对齐了
Tplinker
的形式,先给实体较大的权重,然后权重慢慢往关系倾斜,推理的时候也是先抽取实体,作为字典,然后抽出头实体时在字典中寻找,在利用尾实体来确定三元组。
多属性抽取
严格来说此次的任务是进行属性抽取,而属性抽取最大的不同是只有属性这一个关系,这里笔者考虑是否能把属性通过Schema的方式把其定义为不同的属性类型呢,这里笔者又进行了一次实验
这里笔者通过对训练集的属性类型进行了统计总共有42种schema,笔者分别做出42种属性类型,例如(属性_1,属性_2...)这种形式利用
GlobalPointer
进行关系抽取训练,也用了苏神的CasRel进行了训练,得到的效果跟单个的效果差不多。
而笔者这么做的原因是因为想实验另一种方法的结果,从PRGC这篇文章笔者得到启发(这篇文章笔者会在近段时间进行一个解读,以及代码的整理),笔者主要是在
GlobalPointer
关系抽取的任务里添加了存在哪些关系的的任务,然后通过一个矩阵U,像取向量一样取出关系向量,将关系向量加到对应的token向量上最后得到
Logits
,如图
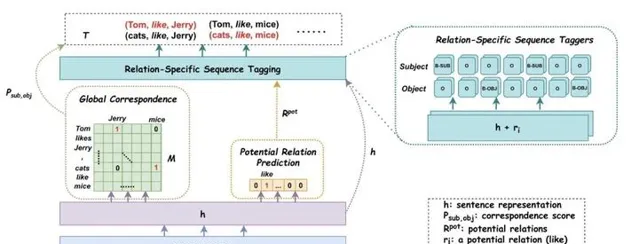
但发现效果也不是特别理想,笔者打算在其他关系抽取的数据集中在进行一些实验。
PipeLine
去年陈丹琦大佬的文章让笔者重新审视了
PipeLine
模型跟Joint模型,笔者的印象中一直觉得PipeLine模型会出现误差积累,任务之间无法交互,计算复杂的刻板印象之中,而现在的SOTA基本全部都是Joint的天下了。没想到这篇文章的出现也打破了笔者对PipeLine模型的偏见,文章利用两个encoder组成Pipeline模型,采取两个独立的预训练模型进行编码。
NER方面通过BERT连接一个Span分类网络-基于片段排列的方式,提取所有可能的片段排列,通过SoftMax对每一个Span进行实体类型判断。
RE方面,在第一阶段识别出的实体,用边界和类型特殊字符标识出来,作为第二阶段的输入 ,第二阶段用BERT来预测两个实体之间的关系,在RE阶段将实体边界和类型作为标识符加入到实体Span前后,识别出的实体是Method的Subject,就把<S:Md>和</S:Md>插入到实体边界,同理对于Object也插入<O:Md>和</O:Md>,对每个实体pair中第一个token的编码进行拼接,然后过全连接层,最后过Softmax。
加速计算:每个实体pair轮流进行关系分类,同一文本需要进行多次编码,加速的近似模型:可将实体边界和类型的标识符放入到文本之后,然后与原文对应实体共享位置向量。相同的颜色代表共享相同的位置向量。在attention层中,文本token只去attend文本token、不去attend标识符token,而标识符token可以attend原文token。
原文也做了消融实验,给出了为何PipeLine的方法为何会比Joint的方法有原因,Joint方法提取的特征可能一致,也可能冲突这样会使模型的学习变得混乱。在 Two are Better than One中也有相同结论。
但是是否能解决Joint模型所出现的问题呢,ACL2021的UniRE给出了一种解决方案,这篇文章也是填表的方式来解决此问题,总的来说就是把实体识别转化成一种特殊的关系分类,如图:
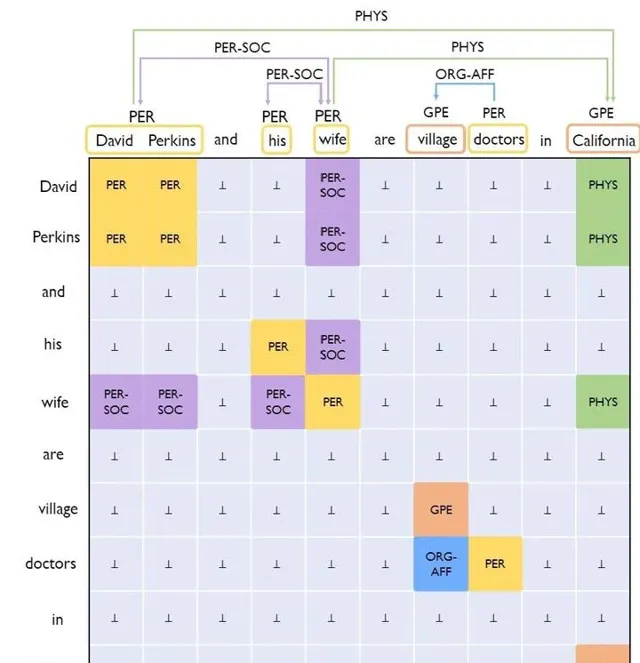
把关系也是分为了:正向关系,逆向关系,无向关系,这样一来,模型的标签空间就是一个统一的标签空间了。(笔者之后会做一个详细解读,包括代码的整合,这里就不在详细展开)。
常规优化
到这里笔者通过实验最后选择了
GlobalPointer
的实体关系联合抽取模型作为Base模型。并对数据集进行清洗,10折交叉得到结果然后投票得到训练集。
结束语
在这次比赛中笔者也是使用了大量的方法,PipeLine部分的方法有些还没有实现,笔者这里也是对这次的大赛做出了一个总结,代码部分笔者会尽快整理成统一的形式上传的Github,也希望大佬们批评指正。
参考文献:
苏神的GlobalPointer:https://spaces.ac.cn/archives/8373
对抗训练:Nicolas:【炼丹技巧】功守道:NLP中的对抗训练 + PyTorch实现
【A Novel Cascade Binary Tagging Framework for Relational Triple Extraction】
【Named Entity Recognition as Dependency Parsing】
【Empirical Analysis of Unlabeled Entity Problem in Named Entity Recognition】
【TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking】
【PRGC: Potential Relation and Global Correspondence Based Joint Relational Triple Extraction】
【A Frustratingly Easy Approach for Joint Entity and Relation Extraction】
【Two are Better than One:Joint Entity and Relation Extraction with Table-Sequence Encoders】
【UniRE: A Unified Label Space for Entity Relation Extraction】
【R-Drop: Regularized Dropout for Neural Networks】
【Understanding and Improving Layer Normalization】









