「端到端」是不是撕开完全自动驾驶的那道裂缝?
流量/声量这么大,大家都创造条件上,

辣应该是的光吧,至少是在聚光灯下的。
说是曙光/微光,是因为这道光真的能照进来的话。
可能意味着:
最终世界模型的路,真有可能走通
。
一个可解释的一端式端到端,性能表现类人类、稳定、可靠的话。
确实是一道微光。
和现在搭积木(场景),以量取胜的自动驾驶相比。
端到端最大的区别在于。
有一点点摸到,
直接理解物理世界的那道坎
。

就像,看剧,不需要字幕组:
直接生吞物理世界这个「生肉」是生吞, 全量的、瞬息万变的、包含小概率事件 的现实世界。
怎么生吞的:
「端到端」是通过一个
单一
的神经网络模型直接从传感器输入到控制输出。
这样能简化多个模块之间的复杂交互和信息传递过程。误差积累也就少了,计算效率也提升了。
对比现在传统的架构:用分模块的方法,将感知、预测、规划和控制等任务分别由不同的算法模块处理,每个模块之间通过接口传递数据。
虽然降低了开发难度,但容易导致信息传递损耗、误差累积以及计算延时。
可以快速的搭起下限不低的自动驾驶,但是天花板隐隐也就在上头了
。
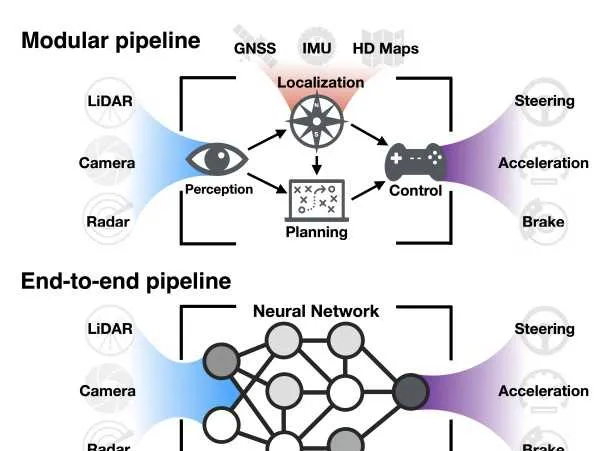
而端到端架构则通过深度学习模型直接处理原始传感器数据。
关键,衍生出了
全局优化和泛化
的能力
所以,端到端,是隐隐摸到
但为什么是
隐隐摸到
,能不能生吞现实世界?
八戒吃人生果那样可不行。
得
可解释
,这是目前最大的难题。
目前也有一些方案来攻克 可解释性
多模态大模型
:
牛津大学提出的RAG-Driver通过使用多模态大模型的上下文学习,提供人类可理解的解释,增强自主决策的可信度和透明度。
类似于给代码写一个阅读性很强的文档?
从算法建模前、中、后三个阶段插手
:
在算法模型建模前、建模中与建模后三个阶段赋予模型从始至终的可解释性。
类似于,每一个模块都「打印」出来,做过程检验?
但,这与一段式端到端是不是背离的。
但是底层的,需要超量的高质量数据及仿真/实车验证。
要靠时间,不能压缩的时间。
希望,这道光快点照进来吧。











