1 前言
BEV感知是近几年自动驾驶领域发展最快的方向,甚至可以不用加之一。自从2021年Tesla在AI Day上展示了这一技术以来,BEV迅速占领了感知领域的各个方向,从3D目标检测到语义分割,从视觉感知到多传感器融合,等等。
在感知领域取得巨大成功之后,BEV技术也逐渐被应用到自动驾驶系统的其他模块,比如行为预测,轨迹规划,语义地图等等。同时,还有一种趋势,就是用BEV把所有这些模块都串接起来,形成一个整体,这也就是当下最火热的「端到端自动驾驶」的概念。
专栏之前的文章详细介绍了视觉BEV感知的概念和代表性算法,这些算法主要是为了完成3D目标检测的任务。视觉传感器:BEV感知综述
在此基础上,本文进一步探讨BEV如何应用到其它感知任务(比如目标跟踪,语义分割,占据栅格等),以及其它自动驾驶任务(行为预测,轨迹规划,语义地图等),甚至是用来设计端到端的自动驾驶系统。此外,虽然本文介绍的这些扩展任务是以视觉输入为主,但是这些任务对输入并没有限制,多传感器融合的BEV方法同样可以来完成这些任务。
那么, 为什么BEV可以做这么多的任务呢,它核心的技术到底是什么呢 ?
字面上理解,BEV是Bird's Eye View的缩写,所以它只是一种视图表示方法,或者说一种坐标系。自动驾驶系统最终是需要在BEV坐标下(或者说3D空间坐标,这里为了描述简单我们不作区分),而传统的视觉感知是在2D图像坐标下进行的,这中间就有了gap。BEV技术出现之前,一般的做法都是先在2D图像上生成各种感知结果,然后再把结果转换到BEV坐标。 BEV技术最核心的思想就是直接在BEV空间中输出结果,跳过了在2D图像上输出结果的步骤,而2D图像上只做最基本的特征提取 。
为了直接在BEV空间进行操作,最直接的方法就是把图像特征从2D空间映射到3D空间,也就是常说的View Transform。这是BEV技术的核心步骤,可以通过Transformer或者深度估计来完成。当然,有些方法没有显式的做特征空间转换,而是利用Transformer,直接从图像特征中预测3D空间中的感知结果。但是不管采用哪种方式,基于BEV的方法都没有在2D图像上生成感知结果。
如果显式生成了BEV特征图,那么这个特征图就可以被用来完成很多的下游任务,比如行为预测和轨迹规划。这些自动驾驶的任务本来就是在BEV坐标下设计的,因此可以很容易的与BEV特征图衔接。同时,我们也可以设计不同类型的query(比如动态目标,地图元素,自车轨迹等),把多个任务整合到一个大的神经网络中,形成一个「端到端」的系统。
为了更好的理解BEV技术,下面我们来探讨两个常见的问题。
1. BEV和Transformer有什么联系呢?
严格来讲,BEV本身和Transformer没有任何关系。但是,BEV技术的View Transform可以通过Transformer来实现,比如BEVFormer中的方式。当然,View Transform也可以通过深度估计来实现,比如BEVDet中的方式。此外,Transformer作为主干网络结构,可以更好的提取图像特征,这也是目前大模型中常用的方式。当然,传统的网络结构,比如ResNet,EfficientNet等都可以作为主干网络来提取图像特征。为了进行多任务扩展,可以设计对应不同任务的query,当然也可以利用传统的多头网络结构,每个头对应一个任务。
所以,理论上来说,一个BEV网络可以完全不包含任何与Transformer相关的结构。但是,在目前主流的网络设计中,尤其是「端到端大模型」中,使用Transformer结构可以增强网络的学习能力,在海量数据的加持下可以获得更好的性能。因此,BEV+Transformer这种组合逐渐被固定下来。但是,我们要知道,他们两个本质上是两个概念。
2. BEV技术是不是已经过时了,端到端才是未来?
BEV和端到端其实也是两个概念。用传统的2D图像感知网络,理论上我们也可以把它与下游的预测和规控任务连接起来,只不过设计和实现的难度都比较大。用BEV的框架来实现端到端会更加合适一些,因为BEV把感知任务也放到BEV空间里来做,跟下游的预测和规控任务统一起来了。同时,预测和规控模块也可以很容易的利用BEV坐标下的图像信息。此外,在BEV坐标下,图像与雷达点云的融合也变得更加容易,为「多模态端到端大模型」奠定了基础。
所以,BEV只是实现「端到端」的一种方式。从目前的趋势来看,BEV+Transformer是实现端到端的一种比较现实的方式,仅此而已。也许,在将来的某一天,我们用一个超级神经网络,直接把原始的传感器数据转换为车辆的控制信号。从不同坐标系下的传感器输入到自车坐标系下控制信号,坐标系的转换都隐藏在神经网络中,已经无从分辨了。到那个时候,也许我们就不会再更多谈论BEV的概念了。
2 感知任务扩展
专栏之前的文章着重介绍了视觉BEV感知网络的设计思路,终端任务基本都是常见的3D目标检测。至于其他感知任务,只在「多任务网络」部分进行了简单的介绍。如上文所述,BEV感知可以很自然的扩展到其他感知任务,比如目标跟踪、语义分割、占据栅格等。
2.1 占据栅格(Occupancy Grid)
占据栅格这个任务其实就是一个3D空间的语义分割,与其他分割任务相比并没有本质区别,只不过分割的对象不同。图像语义分割的对象是像素,点云语义分割的对象是点,而占据栅格的分割对象是3D空间的栅格(3D grid cell或者voxel)。其实,在激光点云的分割中,如果把点云量化为voxel再做处理,这个跟占据栅格任务是非常相似的。既然是语义分割任务,那么评价的指标也可以类似的用IoU和mIoU来衡量。
作为一个分割任务,占据栅格的优势当然也是处理「非标准」的障碍物,或者说通用障碍物。在3D目标检测任务中,目标都是以「框」(bounding box)的形式存在,但是很多障碍物是不能简单用一个框来表示的。比如,一段弯道两侧的绿化带,一辆转弯的两段式公交车,如果用框来表示就会有很大误差。甚至,在自动泊车的场景下,一辆小轿车如果用矩形框来表示都会带来不可接受的误差。因此,虽然占据栅格这种稠密的表示需要很大的计算量,在某些场景下还确实是必须要有的。
2.1.1 真值生成
占据栅格本质是一个语义分割任务,其输出是每个voxel的占据状态和语义标签。假设感知场景包含C个语义类别,那么每个voxel的的标签就是一个C+1维的向量,其中0表示「非占据」,1到C表示占据的语义类别。为了训练神经网络预测这种输出,我们需要构建同样格式的真值,也就是稠密的带有语义标签的voxel。
这并不是一个简单的任务,因此本文专门用一小节来介绍占据栅格真值的生成方法。与目标检测中的物体框相比,语义分割任务的真值标注要困难很多。采用人工标注的话,耗费的时间基本要多一个数量级。与图像和点云相比,占据栅格的标注就更加费时,因为它比图像多一个维度,比点云稠密度高很多。因此,占据栅格的真值生成要么是全自动的,要么是高度自动化的(只需要少量的人工检查)。
OpenOccupancy
在该论文中,作者提出了一种半自动的方法,从激光点云的语义标注出发,构建稠密的占据栅格标注。实验在nuScenes数据库上进行,利用了Panoptic nuScenes提供的激光点云语义标注。
该方法称作Augmenting And Purifying (AAP),其中Augmenting是自动化的部分,而Purifying是人工校验的部分。首先,多帧激光点云根据标注的3D物体框,可以区分为静态点和动态点。静态点通过自车运动信息进行多帧累积,动态点则在物体框自身坐标系下进行多帧累积(再放回到静态场景中),最后形成一个相对稠密的多帧点云。然后,用该点云生成占据栅格,文中称之为「初始标签」。此时的栅格还是有很多空洞区域的,但是可以用来训练一个基准的占据栅格预测网络。之后这个基准的网络就可以用来预测稠密的占据栅格,文中称之为「伪标签」。初始标签和伪标签合并到一起,就可以得到完整的占据栅格标签(两者冲突的时候,以初始标签为准)。以上就是Augmenting的流程。最后,人工标注员再利用标注工具检查Augmenting生成的标签,查缺补漏,也就是Purifying。在nuScenes数据集上,3.4万个关键帧的检查花费了大约4000个小时的人工,平均每小时可以检查8.5帧,还是非常高效的。
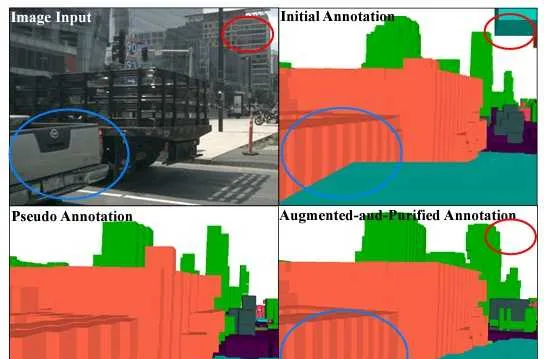
SurroundOcc
与OpenOccupancy类似,该方法在第一步中同样采用动静分离的处理方式来合并多帧点云,并得到初始的占据栅格。自然的,这个栅格并不是完全稠密,而是带有很多空洞的。接下来,作者提出利用Poisson Surface Reconstruction来对初始占据栅格进行补全。补全之后再利用最近邻的策略来给栅格分配语义标签。整个过程没有人工参与,可以全自动进行。但是,全自动生成的占据栅格肯定还会有错误,如果有人工修正的话可以进一步提高标注的质量。
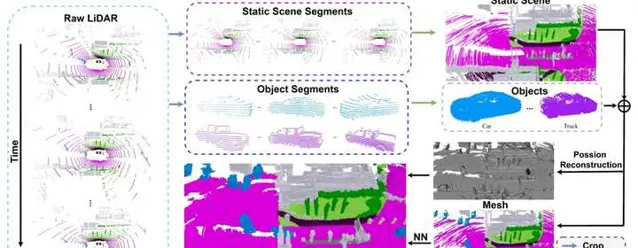
Occ3D
该方法同样采用动静分离的策略合并多帧点云,也采用了Surface Reconstruction和K近邻的策略来补全稀疏的占据网格及其语义标签。这些步骤与OpenOccupancy和SurroundOcc是类似的,不过Occ3D额外关注了遮挡和不确定区域的问题。
上述自动标注的流程都是基于激光点云,激光射线有反射的栅格(也就是点云的位置)会被标记为"occupied",其余栅格标记为"free"。但是激光射线是稀疏的,无法覆盖所有的区域。尤其是在远距离的区域,射线之间的空白空间会很大。此外,障碍物后面的区域,激光射线也覆盖不到。所以,"free"的栅格有两种情况,一种是真的free,另一种其实是不确定的。Occ3D通过ray-casting的方法,进一步区分出不确定区域的栅格,把它们标记为"unobserved"。
另外,激光雷达和摄像头的FOV是不一致的。激光能看到的,摄像头不一定能看到,反之亦然。因此,Occ3D中同样也定义了基于相机的"occupied"、"free"和"unobserved"。在训练和测试的过程中,需要综合考虑来自两种传感器的标签状态。这里有很多细节的选择,需要根据实验结果来具体分析。
为了进一步提高标注质量,Occ3D还采用2D图像上的语义分割标注来对3D占据栅格进行细化。

流程总结
通过对以上三个典型方法的分析,我们可以总结出一个一般性的基于激光点云的占据栅格真值生成流程。
- 激光点云根据目标级的标注信息,划分为静态背景和动态目标。
- 静态场景和动态目标分别进行多帧累积,生成更加稠密的点云。
- 多帧累积后静态场景和动态目标合并到一起,并进行网格化。
- 利用预训练模型或者mesh reconstruction之类的技术对voxel进行补全,然后对遮挡区域进行处理。最后再利用2D图像或者人工操作对voxel标注进行检查和修正。
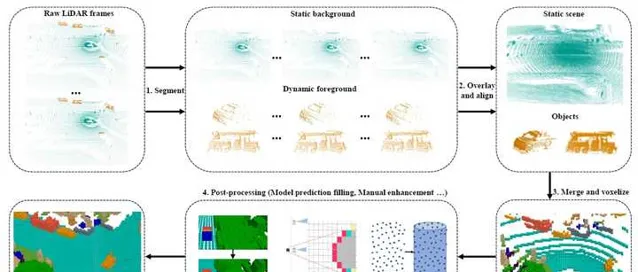
用激光点云生成的3D占据栅格真值来提供监督信号,是最直接的一种训练方法。此外,还有些方法提出用网络预测的占据栅格来生成2D的深度图,用深度的真值来做监督学习,比如 SimpleOccupancy 和 UniOcc 。当然,深度的真值一般也是通过激光点云获取的。
数据采集车一般都配备激光雷达,但是这样得到的数据非常有限。更多的数据其实来自于量产车,但是量产车上不一定配备激光雷达,即使有的话一般规格也比数据采集车低很多。如何能在没有激光点云或者激光点云质量较低的情况下训练占据栅格网络呢?这也是一个非常有意思,也非常现实的问题。一个直接的想法就是利用NeRF,因为NeRF本身的目的就是得到一个连续的场景函数,以此为基础就可以生成占据栅格。但是,周视的相机数量太少(一般是6个),互相之间的视野重叠也很少,无法提供足够的3D几何信息。所以,这种方式一般只用来构建一个额外的自监督的损失函数,用来辅助网络训练,并不能完全代替激光点云。
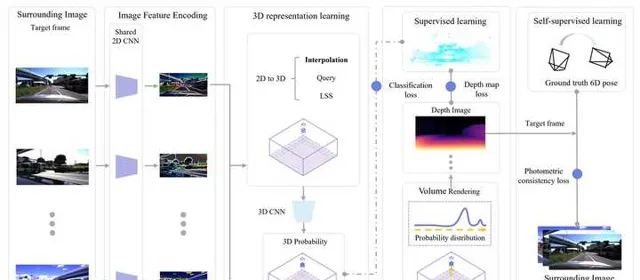
为了能够完全摆脱对激光点云的依赖, OccNeRF 中提出充分利用时序信息,也就是说用NeRF生成连续多帧图像,并且利用多帧图像的光度一致性(photometric consistency)来提供主要的监督学习信号。不过,与用激光点云监督的方法相比,OccNeRF的mIoU指标明显较低。在实际应用中,还是应该考虑如何更加有效的重构3D场景,得到4D标注(这里可以利用多辆车的数据),以及如何更好的利用多种监督信号。
关于4D标注,感兴趣的朋友可以参考 隋唐:面向BEV感知的4D标注方案 | 万字实录
2.1.2 典型算法分析
占据栅格虽然是近期提出的概念,但其实它也不算是一个新的任务。前面介绍了,它可以被看做是3D栅格上的语义分割任务,是2D占据栅格的一种扩展形式。另外,早期的语义场景补全(Semantic Scene Completion,SCC)也跟占据栅格任务的目的非常相似。
SCC任务从稀疏的语义信息出发,恢复稠密的3D场景信息,其最终的输出也就是一个3D的语义栅格。所以,一些用来做SCC任务的方法,比如 MonoScene , VoxFormer ,一样也可以用来做占据栅格的预测。从图像预测3D占据栅格的核心是2D到3D的视角转换,以及3D特征的提取。MonoScene和VoxFormer在2D到3D转换方面做的相对比较粗糙,后续也也就无法很好的提取3D特征,因此它们在占据栅格预测上的性能并不是很好。
视觉BEV感知兴起以后,图像特征从2D到3D的转换有很大的改善,典型的方法包括LSS/BEVDet中的push方法(或者叫forward方法),以及BEVFormer中的pull方法(或者叫backward方法)。两种方法的细节可以参考专栏关于视觉BEV感知的介绍文章。
理论上说,BEV的方法都可以用来做占据栅格,我们只需要在BEV特征提取之后加一个3D占据栅格预测的任务头。BEV特征虽然没有显式的高度维度,但是高度方向的信息都已经被编码到了特征中,是可以恢复出3D空间结构的。比如, MiLO 方法使用了BEVDet4D的结构, OccTransformer 方法使用了BEVFormer的结构,而 FB-OCC 方法采用了FB-BEV的结构(综合了forward和backward两种视角变换方式)。此外, TPVFormer 利用俯视图(也就是BEV)/前视图/侧视图三种不同的视图来提取特征,试图用这种方法来尽可能的保留3D特征。这些方法在得到3D Voxel特征以后,通常都会利用一个3D-UNet或者3D-ResNet结构来进一步增强3D特征的提取。这是3D占据栅格网络与一般的BEV网络最大的区别。

除了3D特征提取以外,目前准确率比较好的占据栅格方法都采用了很多的trick。比如,采用更大的预训练主干网络来提取图像特征,叠加更多帧以增强时序特征提取,甚至把多个完全不同的占据栅格网络ensemble到一起。这些trick都会增加很多的计算量,而车载系统需要考虑准确率和计算量的平衡,对这些trick的使用会比较谨慎。
如上所述,在占据栅格网络中,3D特征提取是重要的一环,同时也是计算量的瓶颈之一。为了降低这部分的计算量, FlashOcc 中提出一直在BEV视图上做特征提取,这里高度信息是被编码到特征通道里了(也就是height-to-channel),直到最后需要预测3D占据栅格时,才利用channel-to-height的reshape操作生成3D网格特征。这种方式避免了非常昂贵的3D卷积计算,通过实验可以看到准确率和计算量之间的tradeoff也是很不错的。比如,在mIoU只降低0.6%的情况下,FPS可以从92.1提升到210.6。
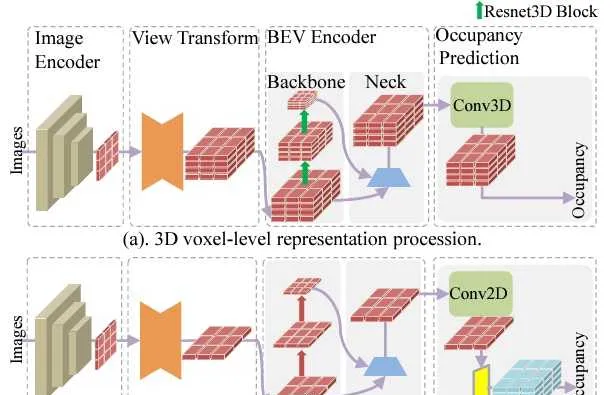
类似的, FastOcc 也是利用BEV特征的2D卷积代替Voxel特征上3D卷积,以降低计算量。但是在最后阶段恢复3D特征的时候,没有采用channel-to-height,而是将原始的2D图像特征转换到3D Voxel特征,与unsqueezed的BEV特征合并,做一次3D卷积后,用于占据栅格的预测。这里的3D Voxel特征相当于没有经过处理,而是通过类似ResNet中的shortcut方式,直接与BEV特征合并。
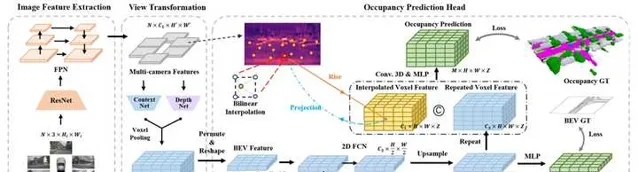
除了3D特征提取,占据栅格网络的另外一个计算量瓶颈在于网格的大小。为了满足自动驾驶系统要求,网格大小一般在5到50厘米之间,分辨率越高,网格的尺寸也就越大,特征提取所花费的计算量也就越大。但是,在实际场景中,大部分的网格都是"非占据"的,这些区域并不需要很高的分辨率。换句话说,只有"占据"区域的网格需要较高的分辨率。在这种思路的指导下, OpenOccupancy 提出了一种coarse-to-fine的占据栅格预测方法。首先,任何占据栅格网格都可以被用来预测一个低分辨率的栅格。然后,这个栅格中被占据的格子单独拿出来,在空间上进行分割,得到高分辨率的网格,并以此为基础生成query。最后,这些高分辨率的query去和图像/点云特征交互,生成高分辨率的占据栅格。"非占据"的栅格可以直接扩展为多高分辨率网格,因为这些栅格本身就是空的,没有信息量。采用类似思路包括PanoOcc和OctreeOcc。

还有一些方法提出采用多尺度的栅格表示,比如 SurroundOcc 和 Multi-Scale Occ 。但是多尺度的栅格对应的空间范围是相同的。其实,在自动驾驶任务中,对网格分辨率的要求是跟距离相关的。远距离区域可以采用低分辨率网格,而近距离区域需要高分辨率的网格。根据这个思路,我们也可以设计多组不同分辨率,对应不同距离区域的网格,从而降低整体的栅格预测计算量。
2.2 多目标跟踪(MOT)
卷积神经网络很早就被用到了物体检测领域。但是对于目标跟踪来说,用传统的卷积网络来实现还是比较困难的,其中主要的问题在于如何处理track的生命周期,以及如何处理detection和track之间的assignment关系。当Transformer被用于物体检测后,我们发现利用query机制可以很好的处理上述问题。比如,在 TrackFormer 和 MOTR 中,query被划分为detection和tracking两部分。Detection query主要用来完成目标检测任务,而track query和detection query合并后计算自注意力,完成assignment。更新后的query再与图像特征交互,确定新生成的track和需要删除的track。专栏的另外一篇文章中详细介绍了TrackFormer的原理,供大家参考。多传感器融合:后融合(深度学习)
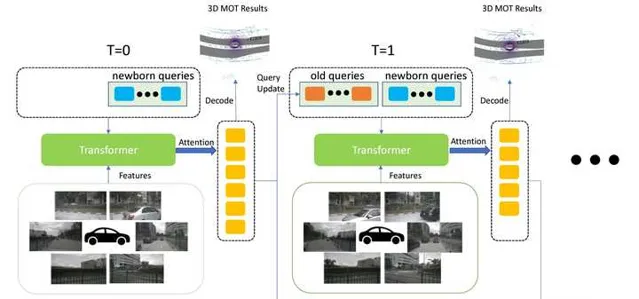
同样的,query的机制也可以用来在BEV框架下实现多目标跟踪。比如,在 MUTR3D 中,query分为newborn和old两种,分别用来生成新的track和维护现有的track。当query的confidence低于一定阈值后,就会被设置为dead query,也就是被删除了。此外,MUTR3D还维护了一个motion model,具体来说就是通过query和自车运动的信息来预测被跟踪目标的运动。这一步其实就是模拟了kalman滤波中的dynamic model。
3 地图任务扩展
在2021年Tesla的AI Day上,BEV感知的概念第一次亮相。在那场发布会上,当时Tesla AI部门的负责人Karpathy博士举了两个例子来证明BEV感知优于传统2D图像感知,其中一个例子就是车道线检测。具体内容可以参考我之前写的一个回答 自动驾驶BEV感知有哪些让人眼前一亮的新方法?
所以,车道线检测其实是BEV感知诞生时就可以做的任务。除了车道线,BEV感知后来也被用来检测更多的地图元素,比如斑马线,道路边沿等,进而扩展到构建局部的语义地图。接下来,我也会按照这个顺序来介绍BEV对于地图元素感知算法。
3.1 车道线检测
深度学习出现之前,图像中的车道线一般是通过其边缘的灰度/颜色变化来检测,然后利用霍夫变换/RANSAC之类的方法拟合车道线方程,最后再用滤波的方法来输出平滑的车道线。这种方法需要的计算量较小,也不需要大量标注数据,但是包含大量人工设计的逻辑,可扩展性比较差,也无法适应复杂的路面状况。
深度学习出现之后,最直接的方法就是用图像实例分割来检测车道线,比如 LaneNet 。此外,还有一些其他的方案,比如把车道线参数化,然后用神经网络来估计这些参数,或者设定一些anchor lines,然后用神经网络预测真实车道线与这些anchor lines的offset。
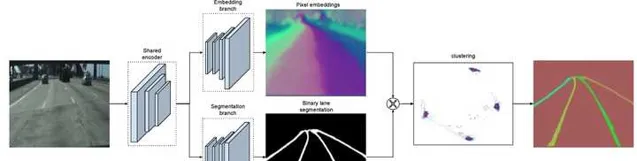
2D图像中检测到的车道线,还需要投影到车辆坐标系(一般就是BEV坐标),才能提供给下游的模块使用。这种2D检测+BEV投影的方式会带来较大的空间误差。在远距离区域,这个误差尤其严重。车道线在图像上偏一个像素,在BEV坐标下可能就会产生几米的偏差。BEV感知把图像特征映射到BEV空间,直接在BEV空间检测车道线,就可以充分利用神经网络的学习能力,来减小空间位置上的偏差。
与之前介绍的占据栅格和多目标跟踪任务一样,对于BEV车道线检测任务,BEV感知框架中的图像特征提取、视图转换和BEV特征提取模块都是可以和其它任务共用的。也就是说,像LSS/BEVDet/BEVFormer这些框架都也可以拿来做BEV车道线检测,我们只需要设计一个专门的车道线检测任务head即可。在这里,最核心的东西就是定义车道线的表示方法。与图像中的车道线检测类似,我们也可以用实例分割mask,anchor lines或者参数化曲线等方法来表示车道线。下面我们来看一下两个典型的方法。
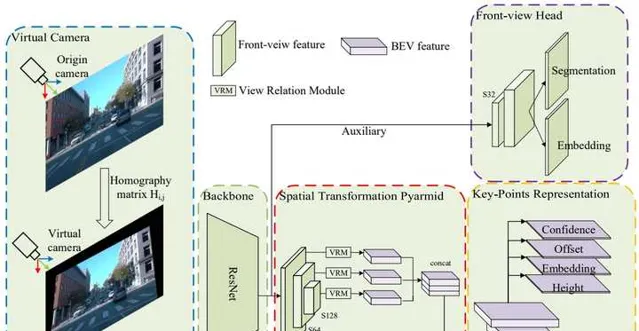
PersFormer 方法提出用anchor lines来表示车道线,每条anchor line由多个预设的点组成。anchor lines同时在2D图像坐标和3D世界坐标系中定义,并且具有对应关系。图像特征映射到BEV后,可以直接预测anchor lines的offset,使之与真值标注尽可能匹配。此外,PersFormer还增加了一个额外的BEV车道线分割loss,用来辅助训练。下图是PersFormer的整体结构,其中backbone和Perspective Transformer都是BEV感知的标准模块,所以算法的重点在于从BEV特征预测2D/3D车道线,以及损失函数的设计。

PersFormer的论文中还提出了一个大规模的车道线数据集, OpenLane 。该数据集基于Waymo Open Dataset来构建,包含了20万帧图像和88万条标注的车道线。此外,场景标签和距离自车最近的目标(CIPO)也进行了标注。车道线的标注在2D图像上进行,标注内容包含车道线类别,trackID,以及组成车道线的2D点集。

BEV-LaneDet 采用了网格结构来表示车道线。具体来说,自车前方的路面被划分为0.5m大小的网格,BEV特征最终会预测4个网格,分别用来表示车道线的置信度、在网格内的位置偏移(只有侧向),实例的embedding,以及网格内的平均高度。此外,BEV-LaneDet还采用了虚拟相机技术来降低相机内外参对结果的影响。训练集中所有图像的内外参求平均值,作为基准。在训练和推理阶段,所有图像都利用这个基准的内外参进行homograph投影,保证视角的一致性。
3.2 局部地图构建
曾经,自动驾驶系统非常的依赖高精度地图。原因也很好理解,那就是感知能力不行。不知道大家有没有类似的经验,当你在能见度比较低而且弯道较多的情况开车时,导航地图能让你提前知道前方道路的弯曲程度,这对你提前判断非常有帮助。自动驾驶系统也是一样,当感知模块能力比较弱的时候,如果有一个高精度地图可以准确的给出周围的道路信息(并且范围远超传感器的感知距离),那么感知模块就只需要关注动态障碍物的检测,难度也就降低了很多。
但是,这种方式显然扩展性和适应性都比较差。高精度地图的建立是一个费时费力的过程,时刻保持地图的鲜度也是一个基本不可能完成的任务。因此,当BEV范式大幅提升了感知模块的能力以后,利用感知模块在线构建高精度语义地图,就变的越来越有吸引力了。同时,像nuScenes和Argoverse2这种大规模的数据库,也都提供了高精度地图,经过处理以后就可以作为在线地图学习的真值。
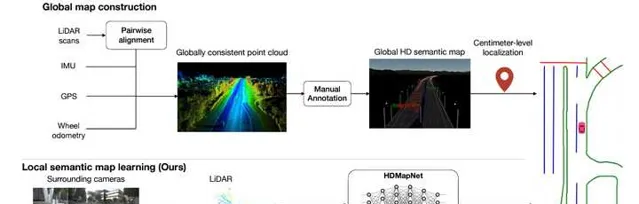
与BEV车道线检测网络一样,BEV地图构建网络的重点也在于地图的表示,以及如何用BEV特征来预测这种表示。其他模块,比如图像/点云特征提取,图像特征视角转换等,都可以用标准模块来实现。下面我们就来介绍一些典型的地图表示和预测方法。
HDMapNet 在BEV特征的基础上,预测得到三个网格类型的输出,分别对应Semantic Segmenation,Instance Embedding和Direction Prediction。前两部分跟基于实例分割的车道线检测方法没什么区别,Direction Prediction则给出了每个网格中地面元素的朝向。在训练过程中,真值也是按照这三部分的格式来生成的。而在推理过程中,三部分输出合到一起,通过聚类得到各个地面元素的实例,并通过方向信息的辅助将它们连成线条。文中的实验是在nuScenes数据库上做的,地面元素的类别只有三类:车道线,车道边沿,斑马线,分别可以用曲线或多边形来表示。
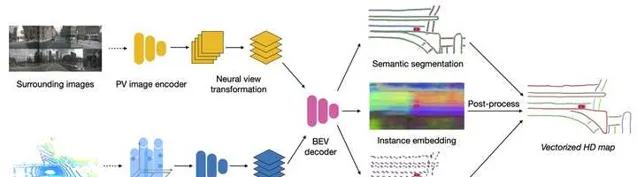
在HDMapNet中,神经网络只是给出了网格形式的输出,矢量形式的输出是通过后处理来完成的。对于局部地图构建来说,检测地图元素只是任务的一部分,更困难的任务是恢复这些元素之间的拓扑关系,而且这些操作尽量都要通过端到端的方式在网络中完成。
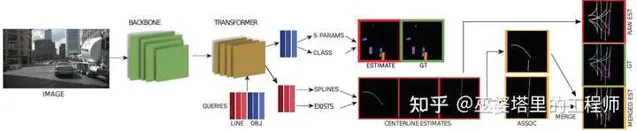
STSU 中提出用贝塞尔曲线来分段建模道路中心线,网络通过line query来输出多条贝塞尔曲线,同时也学习一个分类器,用于判断两条曲线是否是连接的。训练阶段,通过标注数据生成多段贝塞尔曲线,以及它们的邻接矩阵。在推理阶段,网络输出多条曲线,每条曲线都有附加的特征,可以通过训练阶段得到分类器来确定两条曲线是否应该连接。这样,最后就可以得到一组曲线来表示路网的结构。
VectorMapNet 采用polyline来表示地图元素,每个polyline就是一组有序的点集。这种表示方式避免了HDMapNet中稠密的网格表示,同时也比STSU中使用的贝塞尔曲线描述能力更强。该方法也采用query-based的方式,用N个element query来预测polyline。这与DETR中用N个object query预测目标框的原理是一样。每个element query包含k个key points,每个point用d维的参数向量表示。通过Transformer解码器得到key points之后,再用一个polyline generator模块对他们的位置进行细化,并连接成polyline。
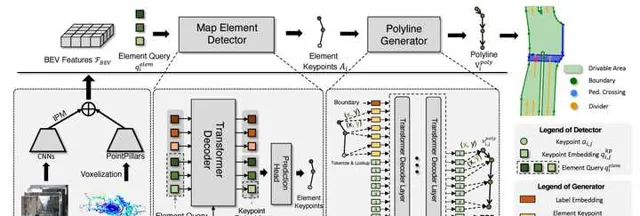
MapTR 采用polygon和polyline来分别表示闭合和开放的地面元素形状,比如斑马线是闭合形状,而车道线是开放形状。polyline和polygon本质上很类似,都可以形式化为有序的点集,如果polyline的起点和终点相同,那其实就是一个polygon。这种表示方式与VectorMapNet类似,但是MapTR考虑了点集的等价性。具体来说,如果polyline代表一个没有方向的车道线(比如区分正向和对向的车道线),那么点集的顺序并不重要。如下图左侧所示,polyline交换起点和终点,可以形成两种等价形式,它们都可以作为GT来跟网络的预测进行匹配。如下图右侧所示,对于polygon来说,除了顺序以外,起点和终点也不重要,也就是说每一个点都可以是起点,因此它的等价形式更多。
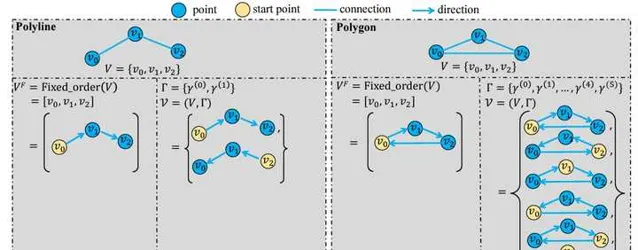
MapTR在训练中充分考虑这些等价性,并利用与DETR类似的框架并行的来预测多个polygon/polyline。因此,除了运行速度更快以外,MapTR预测地面元素的准确率也比VectorMapNet和HDMapNet更高。

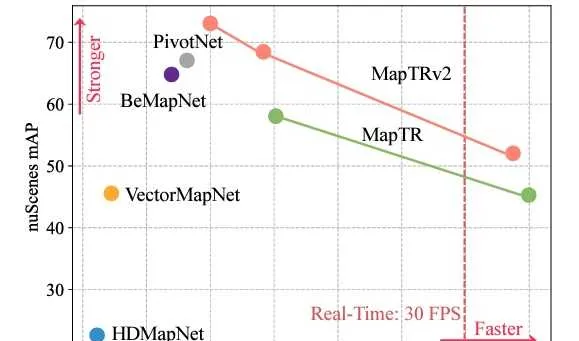
在MapTR的基础上, MapTRv2 做了两个扩展。一个是考虑车道中心线的方向信息,另一个是优化内存占用和降低计算量。
利用BEV感知构建在线地图的目的是降低对于离线高精度地图的依赖。但是,换个角度来想,如果在某个场景下,高精度地图是可用的,那么离线和在线的地图结合起来会不会更好呢?
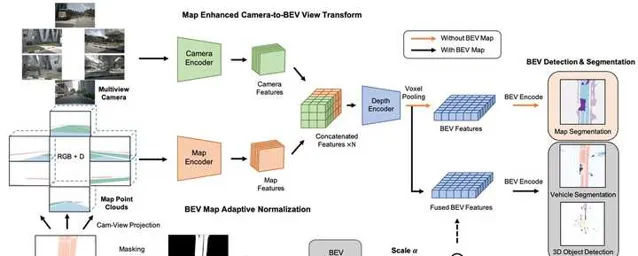
BEVMap 中提出将离线高精度地图从矢量形式(polygon)转换为网格形式,网格中编码了地图元素的类别以及空间信息。这些地图网格通过相机的内外参转换到图像视图,与原始的图像输入按照同样的方式进行特征提取。之后,图像特征和地图特征合并后,再转换到BEV视图,用于下游的地图分割、目标检测等任务。实验结果表明,增加了地图先验信息后,3D目标检测的准确率得到了提升,但不是非常显著。在nuScenes的3D检测任务上,NDS提升了1到2个百分点。
在实际的应用中,如果有正确的高精度地图,那肯定还是以这个地图为主。说白了,感知地图也是以离线高精度地图为真值来训练的。如果有真值,那还费力的做预测干吗呢?所以,更为现实的场景是,有高精度地图,但是地图可能比较老,不能完全对应当前的路况,或者说有些地图元素是缺失的,因为之前建图时没有考虑。在这种情况下,我们拿到的是一张没有那么「精确」的高精度地图,这时地图和感知融合就可以发挥作用了。
MapEX 对高精度地图的真值进行修改,模拟了地图元素缺失、位置不准以及地图过期三个场景,并设计了一个网络结构来融合来自感知和地图的信息。具体来说,高精度地图中的元素被形式化为polyline和点集,并以此为基础构建一组map query。这些query是non-learnable的,它们与传统的learnable的query一起,用来跟BEV特征交互(交叉注意力),预测地图元素。实验结果表明,即使高精度地图是不准确的,还是可以对预测结果提供非常大的帮助。但是,我们也要注意,这种不准确的高精度地图毕竟只是通过模拟得到的,实验的结论还需要审慎看待。举例来说,当删除掉地图中的人行道和车道线,只保留道路边沿,网络对于道路边沿预测的准确率几乎是100%(因为网络用真值作为输入),车道线的预测也有较大提升(因为车道线和道路边沿相关性较大),而对于人行道的预测只有非常小的提升(人行道和道路边沿相关性较小)。
4 预测和规划任务扩展
如上所述,BEV感知的一个优势就是可以跟下游任务(比如预测和规划)更好的连接,因为这些任务本身就是在BEV空间中进行的。那么很自然的,BEV的算法框架也可以用来去做预测和规划任务。更进一步,BEV框架统一了感知,地图,预测和规划,那基本就是一个端到端的系统了。这其实又回到了文章开头讨论的BEV和端到端的关系问题。本质上,端到端是实现自动驾驶的一种解决方案,或者说它是一个任务,而BEV只是实现端到端任务的一种思路。它们之间是隶属的关系,而不是互斥的关系。回到正题,下面我们就来介绍如何用BEV来实现预测和规划任务,进而扩展到端到端的任务。
作为视觉BEV感知的开山之作之一, LSS (Lift, Splat, Shoot)提出了用深度估计来实现2D/3D转换的方案。除此之外,可能很多人都忽略了,LSS中的shoot其实就是要在BEV特征之后做一个motion planning的任务。这里的planning被形式化为预测轨迹的置信度。具体来说,作者从真实驾驶数据中生成1000条自车轨迹作为模板,每条轨迹由多个采样点组成。BEV网络会生成一个cost map,简单说就是一个网格数据,网格里的值就是cost。每条轨迹上的点可以去相应的网格中获取cost值,所有点的cost相加后就得到了一条轨迹的cost。最后,cost最小的轨迹被选择用来规划自车的运动。
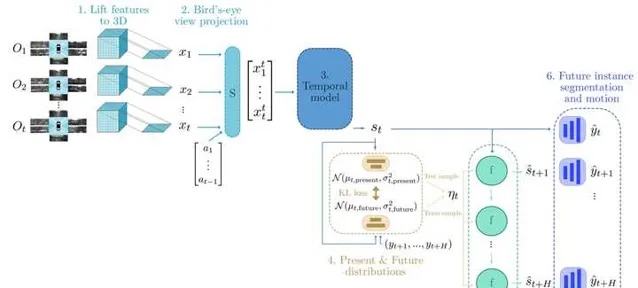
FIERY 提出了一种预测其他目标未来轨迹的方法。其中图像特征的视角变换,多帧数据的时序累积,都跟一般的视觉BEV感知方法没有太大区别。这里比较特别的是通过ConvGRU,以一种recursive的方法来预测未来每一个时刻目标的位置。这个任务被形式化为BEV视图下的实例分割,也就是说网络会预测未来每一个时刻的实例分割结果,并以网格的形式输出。未来多帧的实例分割结果组合起来后,我们就可以得到目标的轨迹。如果想要矢量化的表示,还需要一定的后处理步骤。
最后,我们来看一下 UniAD 这个端到端自动驾驶算法的开创性工作。简单来说,UniAD利用query(也就是transformer机制)把自动驾驶任务中的多个子模块串成一个大的网络,而网络学习的最终目的是planning。这些子模块包括目标跟踪(TrackFormer),地图元素(MapFormer),目标运动预测(MotionFormer),障碍物占据栅格预测(OccFormer)。每个模块的输出都用不同形式的query来建模,更新后query则作为key和value供下游子模块使用。整个网络的输入还是多张图像,BEV的标准操作(图像特征提取,视角变换,BEV特征提取)为后续模块提供BEV特征。从这个结构我们也可以看出,BEV只是实现端到端的一种方式。理论上说,我们也可以跳过BEV步骤,直接把2D图像特征送给下游模块,就像DETR中做的那样。
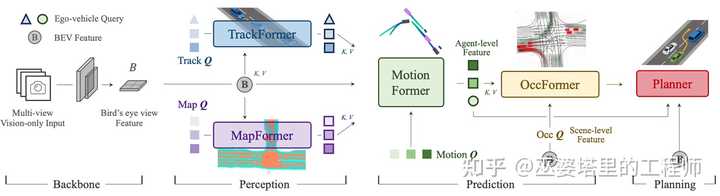
UniAD中的细节远不是几句话可以解释清楚的,本文的目的只是介绍BEV的扩展任务,所以这里只是简单描述一下它的框架。端到端方案是当前自动驾驶研究中的热点问题,专栏后续会退出文章来进行详细的探讨。
5 总结
总结一下,BEV方法的基本流程是传感器特征提取(图像或者点云),2D到3D视角转换(对于图像数据),BEV特征提取,以及各种任务头。用BEV框架来做各种扩展任务,其实就是在BEV特征后面附加各种任务头。目前,由于不同任务的输出格式由很大差异,目前任务头的设计比较倾向于采用基于query的方式。这种方式非常灵活,可以适应不同的输出格式,同时也可以用来串联多个不同的任务。







