據OpenAI官網,OpenAI第一個視訊生成模型Sora釋出,完美繼承DALL·E 3的畫質和遵循指令能力,能生成長達1分鐘的高畫質視訊。
AI想象中的龍年春節,紅旗招展人山人海。
有緊跟舞龍隊伍擡頭好奇官網的兒童,還有不少人掏出手機邊跟邊拍,海量人物角色各有各的行為。
一位時髦女士漫步在東京街頭,周圍是溫暖閃爍的霓虹燈和動感的城市標誌。
一名年約三十的太空人戴著紅色針織摩托頭盔展開冒險之旅,電影預告片呈現其穿梭於藍天白雲與鹽湖沙漠之間的精彩瞬間,獨特的電影風格、采用35公釐底片拍攝,色彩鮮艷。
豎屏超近景視角下,這只蜥蜴細節拉滿:
OpenAI表示,公司正在教授人工智慧理解和模擬運動中的物理世界,目標是訓練出能夠幫助人們解決需要與現實世界互動的問題的模型。在此,隆重推出文本到視訊模型——Sora。Sora可以生成長達一分鐘的視訊,同時保證視覺品質和符合使用者提示的要求。
如今,Sora正面向部份成員開放,以評估關鍵領域的潛在危害或風險。同時,OpenAI也邀請了一批視覺藝術家、設計師和電影制作人加入,期望獲得寶貴反饋,以推動模型進步,更好地助力創意工作者。OpenAI提前分享研究進展,旨在與OpenAI以外的人士合作並獲取反饋,讓公眾了解即將到來的AI技術新篇章。
Sora模型能夠生成包含多個角色、特定型別運動和主體及背景精確細節的復雜場景。該模型不僅能理解使用者在提示中所要求的內容,還能理解這些事物在現實世界中的存在方式。該模型對語言有深刻理解,能準確解讀提示,並生成表達豐富情感的引人入勝的角色。Sora還能在單個生成的視訊中建立多個鏡頭,使角色和視覺風格保持準確一致。
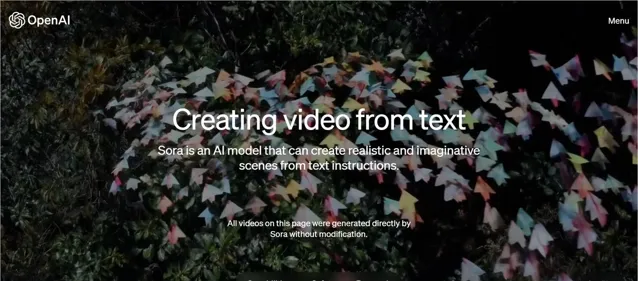
比如一大群紙飛機在樹林中飛過,Sora知道碰撞後會發生什麽,並表現其中的光影變化。
一群紙飛機在茂密的叢林中翩翩起舞,在樹林中穿梭,就像候鳥一樣。
Sora還可以在單個視訊中建立多個鏡頭,並依靠對語言的深入理解準確地解釋提示詞,保留角色和視覺風格。
對於Sora當前存在的弱點,OpenAI也不避諱,模型在準確模擬復雜場景的物理特性方面可能會遇到困難,也可能無法理解具體的因果關系例項。例如「五只灰狼幼崽在一條偏僻的碎石路上互相嬉戲、追逐」,狼的數量會變化,一些憑空出現或消失。
此外,模型還可能會混淆提示的空間細節,例如左右不分,並且在處理隨時間發生的事件的精確描述方面也可能存在困難,比如跟蹤特定的攝影機軌跡。
如提示詞「籃球穿過籃筐然後爆炸」中,籃球沒有正確被籃筐阻擋。
技術方面,目前OpenAI透露的不多,簡單介紹如下:
Sora是一種擴散模型,從雜訊開始,能夠一次生成整個視訊或擴充套件視訊的長度,
關鍵之處在於一次生成多幀的預測,確保畫面主體即使暫時離開視野也能保持不變。
與GPT模型類似,Sora使用了Transformer架構,有很強的擴充套件性。
在數據方面,OpenAI將視訊和影像表示為patch,類似於GPT中的token。
透過這種統一的數據表示方式,可以在比以前更廣泛的視覺數據上訓練模型,涵蓋不同的持續時間、分辨率和長寬比。
Sora建立在過去對DALL·E和GPT模型的研究之上。它使用DALL·E 3的重述提示詞技術,為視覺訓練數據生成高度描述性的標註,因此能夠更忠實地遵循使用者的文本指令。
除了能夠僅根據文本指令生成視訊之外,該模型還能夠獲取現有的靜態影像並從中生成視訊,準確地讓影像內容動起來並關註小細節。
該模型還可以獲取現有視訊並對其進行擴充套件或填充缺失的幀,請參閱技術論文了解更多資訊(晚些時候釋出)。
Sora是能夠理解和模擬現實世界的模型的基礎,OpenAI相信這一功能將成為實作AGI的重要裏程碑。
每日經濟新聞綜合OpenAI官網
每日經濟新聞











