原創 huacishu 圖靈基因 今天
收錄於話題 前沿分子生物學技術
撰文:huacishu
IF=27.601
推薦度:⭐⭐⭐⭐⭐
亮點:
1、作者概述了如何檢視現有的幾種單細胞RNA測序方法,並強調了這些方法在關於運算式變化的假設方面的差異。
2、作者還說明了他們的觀點如何有助於解決生物學上感興趣的問題。

美國芝加哥大學Matthew Stephens教授團隊在國際知名期刊
Nat Genet
線上發表題為「
Separating measurement and expression models clarifies confusion in single-cell RNA sequencing analysis
」的綜述論文。在典型的單細胞RNA測序數據集中,高比例的零導致了廣泛但不一致的術語使用,如空白和數據缺失。在這裏,作者認為這些術語中的大部份是無用的和令人困惑的,並概述了一些簡單的想法來幫助減少困惑。這些想法包括:觀察到的單細胞RNA測序計數反映了真實的基因表現水平胡測量誤差,仔細區分這些將有助於理清思路;方法開發應該從帕松測量模型開始,而不是更復雜的模型,因為它很簡單,通常與現有數據一致。本文概述了如何在這個框架內檢視現有的幾種方法,並強調了這些方法在關於運算式變化的假設方面的差異。作者還說明了他們的觀點如何有助於解決生物學上感興趣的問題。

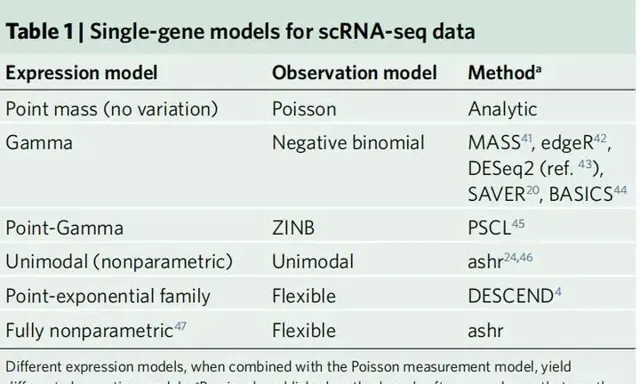
作者強調使用帕松模型特別適用於測量模型而不是觀測模型。事實上,許多論文已經證明,帕松觀測模型並不能捕獲觀測到的RNA序列數據的所有變化;因此,通常使用更靈活的觀測模型來捕捉額外的變化,例如負二項或零膨脹負二項(ZINB)觀測模型。這些觀測模型與帕松測量模型並不矛盾;實際上,在本文中作者將解釋負二項和ZINB觀測模型以及許多其他現有方法是如何透過將帕松測量模型與某些運算式模型相結合而自然產生的。表1給出了單基因表現模型的列表,以及對相應觀察模型進行統計推斷的一些已發表的方法。
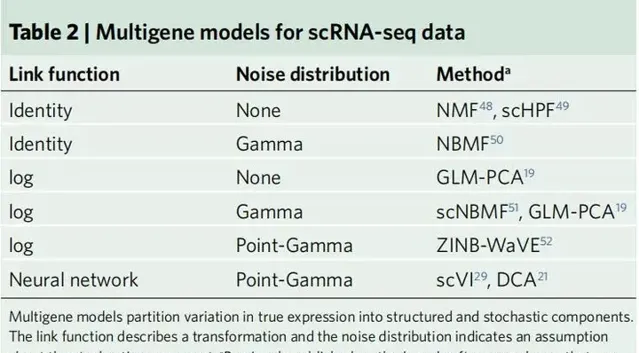
盡管事情不可避免地變得更加復雜,但是類似的想法也適用於多個基因的表達模型。一個多基因表現模型同時描述了細胞內不同基因表現水平胡不同細胞間基因表現水平的相關性。描述這些相關性的一種常見且有效的方法是使用低階模型,該模型直觀地假設相關性可以透過相對較少的模式(遠小於細胞或基因的數量)來捕獲。表2中給出了多基因表現模型的列表,以及對相應觀察模型實作統計推斷的一些已發表的方法。
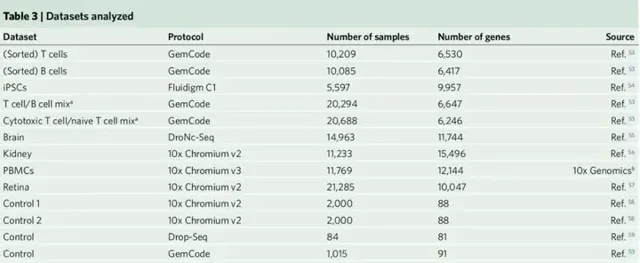
關於scRNA-seq數據是否由負二項觀測模型充分建模,或者是否有必要使用ZINB觀測模型存在相當大的爭論。一些論文得出結論,觀察到的scRNA-seq數據表現出多峰表達變異,這表明可能需要一個更復雜的觀察模型。在上述框架下,這些問題轉化為關於運算式模型:Gamma運算式模型是否足夠,或者是否有必要使用更復雜、甚至多模態的運算式模型?由於基因和數據集之間的表達差異可能不同,因此作者從一系列設定中分析數據集,包括分類細胞的同質集合、細胞系和異質組織。同時還建立了分選細胞的矽膠混合物作為高度異質表達模式的陽性對照(表3)。
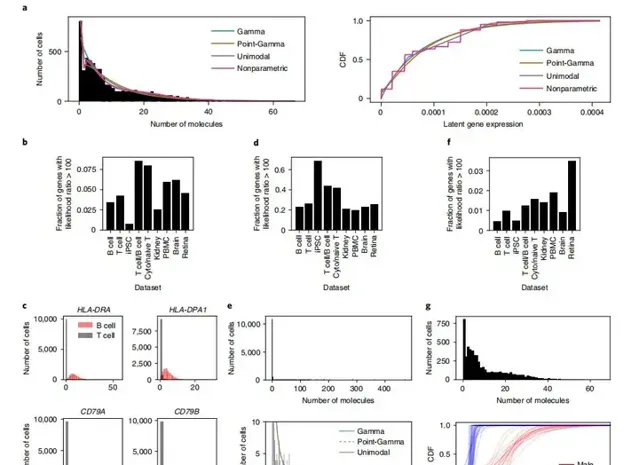
對於每個數據集中的每個基因,作者比較了幾種表達模型:伽瑪分布、點伽瑪分布、非參數單峰分布和完全非參數分布(圖1a)。因為這些比較涉及非參數族,所以獲取p值並不簡單,而且可能不合適,因為將這些模型中的任何一個指定為空運算式模型也是有問題的。因此,作者透過比較每個模型下數據的可能性來比較每個模型的支持度。首先,透過比較Gamma表達模型和點Gamma模型,作者評估了基因是否顯示了由於過多的零而導致的Gamma表達模型的證據。在作者研究的所有生物數據集中,只有一小部份基因(0.6–8.6%)顯示了支持點Gamma模型的有力證據(圖1b)。支持點Gamma表達模型的有力證據表明,這些基因包括分類的B細胞和T細胞合成混合物中的已知標記基因(圖1c),這為這種方法能夠找到這種模式提供了一個陽性對照。接下來,透過與非參數單峰表達模型的比較,評估基因是否有證據表明伽瑪表達模型存在其他型別的偏離。在這個比較中,更多的基因(20–69%)顯示了支持非參數單峰表達模型的有力證據(圖1d)。這些結果表明,無論是負二項模型還是ZINB觀察模型都不能捕捉到許多基因的表達變異。例如,在外周血單個核細胞(PBMCs)中,PPBP基因不僅表現出許多觀察到的零,而且還表現出許多小的非零觀察和大的觀察的長尾(圖1e)。Gamma分布和點Gamma分布都沒有足夠的靈活性來同時描述這兩個特征,從而解釋了非參數單峰模型更好擬合。最後,透過比較單峰表達模型和完全非參數列達模型,評估了數據是否顯示多峰表達變異的證據。在這個比較中,很少有基因(0.4–3.5%)顯示出完全非參數列達模型的有力證據(圖1f),這表明多峰表達變異可能比先前提出的更為罕見。作為陽性對照,RPS4Y1是一個Y染色體連鎖基因,由於來自男性和女性供體的誘導多能幹細胞(IPSC)中基因表現的不同分布,顯示出非參數列達模型優於單峰模型的壓倒性證據(圖1g)。來自女性供體的細胞被估計具有RPS4Y1的非零表達的一個可能原因是RPS4Y1與其同源物RPS4X之間的編碼序列的相關部份是相同的,並且一些讀取被錯誤地對映。
在這裏,作者描述了觀察到的scRNA-seq計數模型如何被有效地分為兩部份:測量模型(描述測量過程引入的變化)和表達模型(描述真實表達水平的變化)。作者認為一個簡單的帕松模型是測量模型的合理起點,許多現有的方法可以解釋為將帕松測量模型與不同的表達模型相結合。作者解釋了這些簡單的想法如何幫助澄清關於scRNA-seq數據中零的來源和解釋的混淆,並給出了嚴格的程式來詢問細胞間基因表現的變化。如何在scRNA-seq分析中使用這些思想?作者強調,明確區分測量、表達和觀察模型有助於減少混淆和誤解。特別是,無論是發展統計方法的個人還是分析數據的個人,都應在分析scRNA序列數據時明確對測量誤差和表達變異的假設。未來工作的一個重要領域是發展快速和準確的診斷方法,以評估這些假設是否被觀測數據所違反,以及分析結果是否對這些假設敏感。
教授介紹

美國芝加哥大學Matthew Stephens教授實驗室主要在統計學和遺傳學的交叉點上研究各種各樣的問題,大部份研究都涉及開發新的統計方法,其中許多方法都有一個非常重要的計算部份。由於數據集越來越大,他們的工作經常涉及現代的「高維統計」方法。經常廣泛地使用貝葉斯層次模型來跨數據集或采樣單元借用資訊。目前的研究領域包括:稀疏性、收縮率和錯誤發現率,特別是對於復雜的相互關聯的數據集;因子分析、降維和大共變異數矩陣的估計;聚類方法和歸納;多尺度和小波方法在基因組數據中的套用以及可復制研究與開放科學。
參考文獻
Sarkar A, Stephens M. Separating measurement and expression modelsclarifies confusion in single-cell RNA sequencing analysis. Nat Genet.2021;53(6):770-777. doi:10.1038/s41588-021-00873-4











