導讀: 小愛同學是小米公司開發的智慧語音系統,已廣泛套用在手機、手環、音箱、電視等電子產品中,並支持閑聊、問答、語音控制等多種語音互動場景。語音系統中語音內容辨識 ( ASR ) 的精準性,是影響智慧語音產品發展的關鍵制約因素,使用者query的文本,通常是由ASR系統將使用者的語音命令轉換而成,但由於技術上的原因,這些由ASR生成的文本可能包含錯誤,繼而導致後續的使用者意圖理解出現偏差。如何利用NLP技術對ASR的query文本進行預處理糾錯成了一個亟待解決的問題。
本次分享,將介紹小愛演算法團隊基於近年來流行的BERT預訓練模型在這個問題上所進行的一些技術探索,以及在業務場景中的落地情況,主要內容包括:
01ASR糾錯問題的介紹1. 語音互動流程

在分享語音糾錯的相關問題之前,先簡單介紹一下小愛同學語音使用流程:首先我們需要喚醒小愛同學,比如,手機按鍵或者語音喚醒,喚醒之後進入錄音模組,啟動錄音前開啟Voice Activity Detection ( VAD ) 狀態,檢測當前有沒說話聲音,如果沒有則忽略,如果有,會把語音記錄下來傳遞到下一個模組,就是最受關註的Automatic Speech Recognition ( ASR ),該模組負責把語音轉譯成文字。我們負責的是ASR接下來的一個模組,文本理解模組Natural Language Understanding ( NLU ),主要目的是試圖理解ASR轉換出的文本,準確辨識使用者的意圖,然後給出相應技能執行的方案,最後一步就是技能執行了。在這個語音互動流程中,前三步都涉及到語音相關的工作,很容易出現記錄噪音或者辨識錯誤等情況,例如誤操作喚醒錄入了噪音;或者語音記錄過程中,把某種聲音誤以為是人的聲音而記錄下來,在辨識時轉譯成了錯誤的文本。另外,即便是純凈的人說話的語音,ASR模型轉換過程仍然會出現一定的錯誤。 2. ASR錯誤的例子
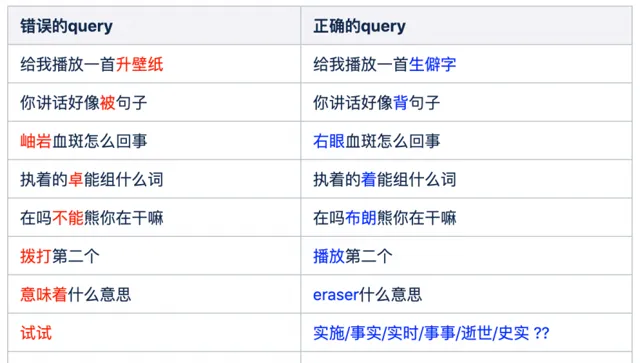
表格中展示的是ASR辨識過程中常見錯誤例子。使用者問"給我播放一首生僻字 ",辨識的文本結果為"給我播放一首升桌布",還有中文中夾帶英文的情況,如:"eraser什麽意思",辨識的文本結果為"意味著什麽意思"。透過分析這些錯誤的case發現,語音辨識過程對於發音因素類似的詞,辨識準確的難度比較大。而我們的工作目標是把ASR辨識後的錯誤query找出來,替換成正確的query。

此時我們需要思考,對於ASR辨識糾錯是否為良定義問題 ( well-posed )[1],良定義問題是說在當前給定資訊的條件下能解決的問題,或者說使用貝葉斯分類器 分類得到的準確率非常高。對於ASR的糾錯問題,從case中可以看出,要糾正這些query,有些根據句子的結構就可以糾正,比如,"你講話好像被句子",可以透過語法結構的分析知道"被"在此處是不合適的,應該是背誦的"背";而有些是需要知道一些背景知識,才能進行糾錯,比如"生僻字"是一首歌,"右眼血斑"是常識,"布朗熊 "是小愛同學業務的技能 ( 布朗熊跳個舞 ),甚至有些語法上沒有錯誤,需要根據原始的音訊才能糾正錯誤,如"播放第二個"與辨識的文本結果"撥打第二個",或者"eraser"辨識為"意味著";有些可能聽音訊也沒有用,對於中文有很多的發音聲調都相同的詞,需要結合當時環境的上下文情景才能確定是哪一個詞。所以糾錯需要結合很多的資訊,如果全部考慮知識、音訊、上下文環境,基本相當於重新做一個ASR辨識系統 。但ASR本身處理語音過程受限於一些記憶體、吞吐流量等物理條件,聲學模型 和語言模型很難有很大的處理量,綜合考慮ASR的語言模型還是基於傳統的n-gram模型。但是使用NLP技術 具有一些先天的優勢,能夠利用目前強大的預訓練模型,並且不需要音訊來進行糾錯。ASR糾錯與普通錯別字糾錯也是有區別的,普通錯別字糾錯是根據字形相似來糾錯,如"閥"和"閾"。而ASR糾錯是音似,發音相似導致難以辨識正確的內容,所以ASR糾錯和普通錯別字糾錯面臨的問題和數據分布是不同的。另外普通錯別字糾錯覆蓋的範圍也比ASR糾錯更廣一點,但這並不意味著普通錯別字糾錯可以用來ASR糾錯。"天下沒有免費的午餐",也就是說沒有一個模型能夠很好的套用在不同的數據分布上。比如文本"的"、"地"、"得"糾錯,假如句子中其他詞都是正確的,只有"的"需要糾正為"得",但是使用一個沒有結合先驗資訊 的普通模型來糾錯,很顯然容易把句中其他位置原本正確的詞糾正為錯誤的,從而影響模型的準確率。正確的做法是根據先驗條件 做出一個能適應當前數據分布的糾錯模型。對於ASR糾錯模型也一樣,發音相似是ASR糾錯的一個限制條件,我們需要把普通錯別字模型結合這個限制條件,來設計針對ASR辨識後的文本數據糾錯模型。 3. ASR糾錯問題設定 接著我們對ASR糾錯問題進行以下初步設定:
這些設定條件跟目前一些ASR糾錯文獻中設定條件一致。 02
糾錯相關工作
1. BERT模型簡介

BERT[2]是目前效果最好的預訓練語言表示模型,引入了雙向的Transformer-encoder結構,已訓練好的模型網路有12層BERT-small和24層的BERT-large 。BERT包含兩種訓練任務,一種是Masked Language Model ( MLM ),另一種是Next Sentence Prediction ( NSP )。BERT模型主要作為預訓練模型使用,提取特征獲得具有語意的詞向量表示,提升下遊任務的表現。
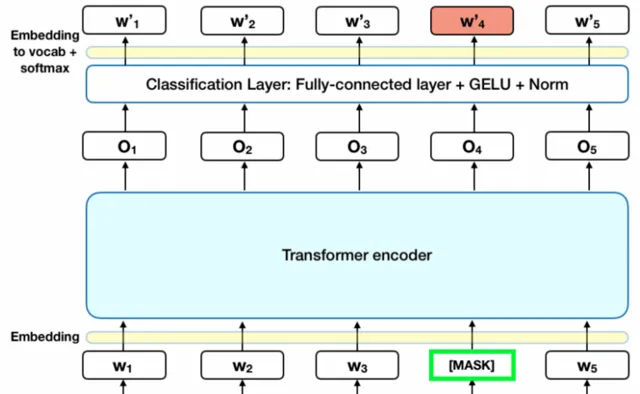
BERT模型中與ASR糾錯任務相關的是MLM部份, MLM訓練階段有 15% 的token被隨機替換為 [MASK] ( 占位符 ),模型需要學會根據 [MASK] 上下文預測這些被替換的token。例如對於輸入句子"明天武漢的 [MASK] 氣怎麽樣",模型需要預測出 [MASK] 位置原來的token是"天"。如果只利用MASK機制訓練存在一些遷移的問題,因為在其他任務中沒有MASK的情況,這樣就很難作為其他任務的預訓練任務,所以作者透過MASK的方式進行了最佳化。
MLM實際上包含了糾錯任務,所以原生的BERT就具備了糾錯能力。但是BERT的MASK位置是隨機選擇的15%的token,所以並不擅長偵測句子中出現錯誤的位置;並且BERT糾錯未考慮約束條件,導致準確率低,比如:"小愛同學今 [明] 天天氣怎麽樣",MASK的位置是"今", 那麽糾錯任務需要給出的結果是"今"。但是由於訓練預料中大多數人的query都是"明天天氣怎麽樣",這樣在沒有約束的條件下,大機率給出的糾正結果是"明",雖然句子結構是合理的,但結果顯然是不正確的。 2. ELECTRA模型
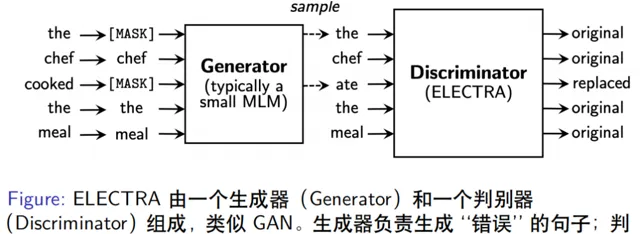
ELECTRA[3]模型由Standford 大學團隊提出,其模型結構由一個生成器和一個判別器組成,看起來與GAN結構類似但不屬於GAN模型。
ELECTRA模型的判別器雖然可以檢測錯誤,但模型設計不是為了糾錯,而是為了在有限計算資源的條件下能提取更好特征表示,進而得到更好的效果,文章中表示在GLUE數據集上表現明顯優於BERT。ELECTRA的一個變體ELECTRA-MLM模型,不再輸出0和1,而是預測每個MASK位置正確token的機率。如果詞表大小是10000個,那麽每個位置的輸出就是對應的一個10000維的向量分布 ,機率最大的是正確token的結果,這樣就從原生ELECTRA檢測錯誤變成具有糾錯功能的模型。 3. Soft-Masked BERT糾錯模型
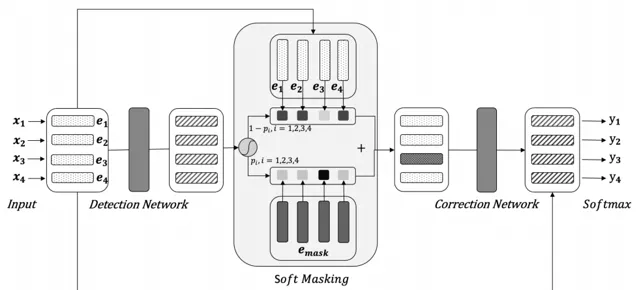
最近發表的一個糾錯模型是Soft-Masked BERT[4],該模型透過對搜集到的語料,進行同音字替換等簡單規則隨機生成錯誤樣本,然後得到錯誤-正確的樣本對作為訓練數據。該網路模型 串聯了一個檢測模型 ( BiGRU ) 和一個糾錯模型 ( BERT ),雙向的GRU模型輸出每個token位置是錯誤詞的機率,當錯誤機率為1時,退化為原生BERT模型糾錯。該模型的創新點在於BERT輸入的詞向量不是原始輸入的token,而是token的embbeding和 [MASK] 的embbeding的加權平均值,權重是BiGRU輸出序列中每個位置的錯誤機率,從而在MASK時起到soft-mask 的作用。舉個例子,假如GRU認為某個位置的詞輸出錯誤機率是1,則輸入到BERT的詞向量就是 [MASK] 的詞向量;而如果是檢測模型認為某個位置的詞是正確的,即錯誤機率是0,這時輸入到BERT模型的詞向量就是token的向量;但是如果檢測模型的某個位置輸出錯誤機率是0.5,此時輸入到BERT模型的詞向量為二者加權後的結果 ( (1-0.5)* token_embedding + 0.5*[MASK]_embedding )。不同於之前檢測器輸出0/1,只有被MASK和未被MASK的Hard-Mask方式,因此該模型稱為Soft-Mask BERT,文章指出這種方式糾錯比原生的BERT糾錯效果高出3%左右。但是我們的工作在論文之前,並未參考該模型,未來會根據實際情況考慮。關於糾錯模型的文獻就先介紹到這裏,接下來介紹我們的工作內容。
03
我們的工作
1. 模型結構
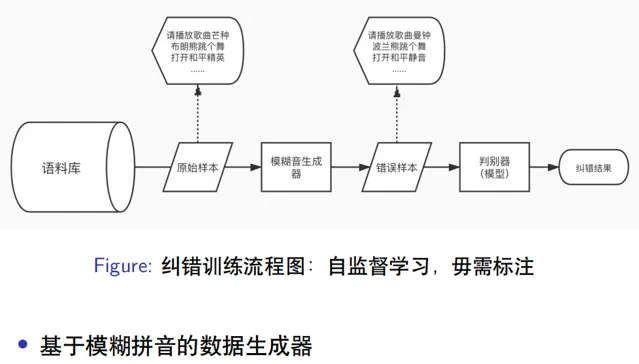
我們的糾錯模型結構也類似生成器和判別器的模式,如上圖所示。語料庫包括維基百科中文、知乎中文、爬取的一些新聞語料,以及小愛同學執行的使用者日誌,總共將近有1億條的數據,從語料庫中抽樣出原始樣本,類似"請播放歌曲芒種"、"布朗熊跳個舞"、"開啟和平精英"等等。我們開發了專門模擬ASR生成錯誤數據的模糊音生成器,基於模糊拼音來對原始樣本處理生成錯誤樣本,生成結果如"請播放歌曲曼鐘"、"波蘭熊跳個舞"、"開啟和平靜音"等等。構造好正確樣本和錯誤樣本的樣本對輸入到判別器模型 ,判別器進行端到端的糾錯,即給模型輸入錯誤樣本,模型輸出為正確的樣本。 2. 模糊音生成器

透過分析ASR錯誤樣本的規律,在模糊音生成器中定義了模糊等級和模糊候選集,如上圖所示。根據模糊音的相似性劃分為5個等級,等級越高,發音越不相似,比如level1是發音完全相同 ( "愛"和"艾" ),level2的發音相同,聲調不同 ( "幾"和"季" ),level3是常見的平卷舌和前後鼻音模糊 ( "shi"和"si","l"和"n" ),level4 的拼音編輯距離 為1,level5拼音的編輯距離大於1,基本上發音已經不一樣了。拼音的編輯距離計算采用的非標準拼音方案,如雖 ( "sui"使用"suei","sui"是縮寫形式 ),"四"的發音"si"使用"sI",由於"i"在"si"中和在"di"中發音是不同的,因此使用"I"來代替"i"在"si"中的發音。再比如"有" ( "you"使用"iou"代替 ) 是因為"y"並不是真正的聲母,當"i"作為聲母時用"y"替換"i",這裏相當於還原了這種實際發聲拼音規則,還有"挖" ( "wa"使用"ua" ),"w"作為聲母時真正的發音實際上是"u"。標準的拼音方案不能很好的體現漢字的發音相似問題,比如"挖"和"華"讀音很相似,如果使用標準拼音方案時,拼音的編輯距離為2 ( "wa","hua" ),而采用我們定義的非標註方案時,編輯距離為1 ( "ua","hua ),所以采用非標準拼音方案更能準確地描述ASR語音出現錯誤的規律,找到合適的編輯距離計算方案。

模糊音生成器的工作流程如上圖所示,輸入文本為"小愛同學請播放音樂",假設MASK位置隨機到"愛",模糊等級level=1時,發音與"愛"相同的候選集為{"哎","艾","礙","曖",...},然後基於n-gram語言模型在模糊候選集中選擇最可能的替代詞,如果計算的詞序列機率最大的是"艾",那麽"愛"被替換成了"艾",最後的輸出為"小艾 同學請播放音樂"。我們透過人工標記了一些ASR錯誤樣本的數據,研究了聲母和韻母的特征,例如平卷舌 ,前後鼻音等出現的辨識錯誤。人工標註的數量畢竟有限,所以根據掌握的規律,透過調整模糊音生成器的超參數 ( MASK的數量,fuzzy的比例等 ),使生成的錯誤樣本分布 盡可能接近真實ASR系統中錯誤樣本的數據分布,以便糾錯模型可以更容易地用於ASR辨識的糾錯任務中。 3. 糾錯判別器
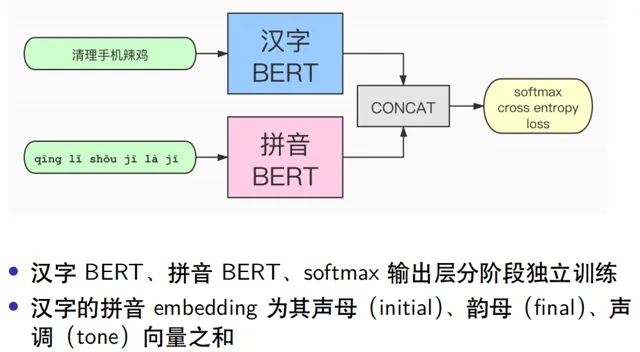
糾錯判別器結構如上圖所示,輸入數據為漢字和拼音的特征,其中漢字經過BERT預訓練模型得到漢字的詞向量,而拼音數據則是透過BERT模型重新訓練一個關於拼音數據的詞向量 ,二者拼接後經過Softmax層,計算交叉熵損失 。為什麽使用拼音的數據呢?這是因為正確的字發音一般比較相似,那麽可以透過拼音來縮小搜尋正確詞的範圍,所以拼音是一個重要的特征。並且透過嘗試後,拼音和漢字單獨訓練再拼接提取的特征優於其他組合方式,這種方式類似於Ensemble模型。先用漢字語料訓練一個端到端的糾錯模型BERT,再訓練一個拼音到漢字的解碼模型,兩個模型拼接後透過輸出層softmax訓練每個位置的交叉熵損失,這點不同於原生的BERT模型只計算MASK位置的損失,而是類似於ELECTRA模型的損失函式 。關於拼音特征的處理過程,比較合理的做法是將拼音拆分成聲母、韻母、聲調,根據發音特征來得到相似發音的embedding 表示向量,並且有相似發音的embedding向量 要盡可能接近。漢字的拼音表示只有有限個,所有聲母韻母組成的網格也只有幾百個,並且拼音的寫法變化也不多,所以拆分成聲母、韻母、聲調之後做embedding是合理的。如果直接對拼音做embedding的訓練,得到的拼音表示向量無法表示出相似的發音。 4. 評測集的表現
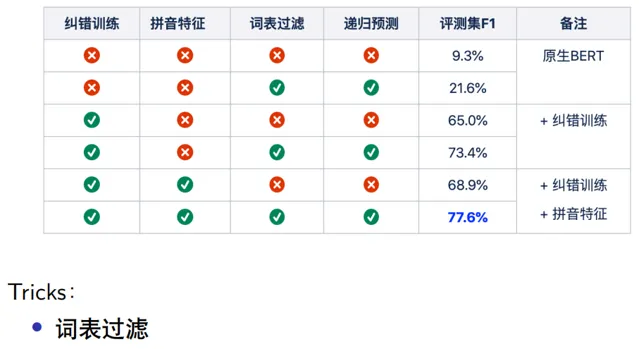
模型中使用到了兩個trick:
如果詞表很大,比如10000維,想要限制一下端到端糾錯模型在糾錯時的搜尋範圍,可以對詞表增加限制,比如只允許在過濾後的300甚至幾十個相似的詞語中選擇,理論上召回有所損失,但是糾正的準確率大大提升,並且這種過濾程度可以調整。實際測評中顯示,加入詞表過濾,顯著提升了模型的效果和效能。
BERT在糾錯過程中是一對一的糾錯,如果一個句子中有多個錯誤的位置,但是對於端到端輸入模型一次Feed Forward 過程可能只糾正了一個位置,若要整個句子實作糾錯,那麽需要把糾正後的結果放到句子中再次輸入模型,進行遞迴糾錯。如果兩次遞迴結果相同則停止遞迴糾錯,否則會遞迴糾錯最多3次。從結果中發現,原生BERT微調之後直接糾錯,模型評測指標為9.3%,加入詞表過濾和遞迴預測 後,f1提升到21.6%,加入糾錯訓練後f1大幅提升到65%,加入trick後,又提升到73.4%,再加入拼音特征數據,效果提升明顯,f1提升到77.6%。 5. 糾錯的表現
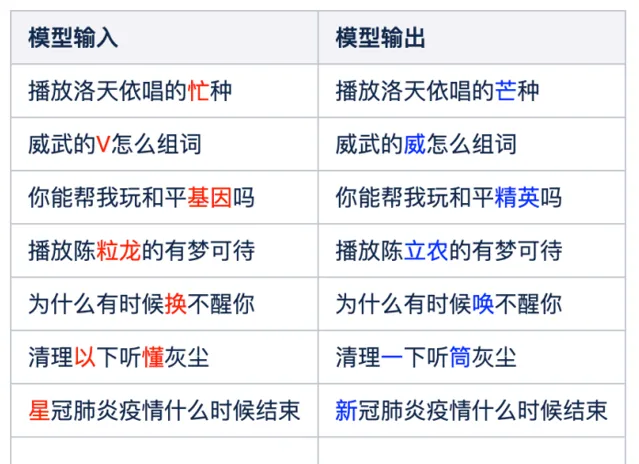
從表中糾錯的例子中可以看出,之前分析的ASR辨識錯誤型別的query,基本上能實作糾錯了,比如"播放洛天依唱的忙種"能夠糾正為"播放洛天依 唱的芒種","你能幫我玩和平基因嗎"糾正為"你能幫我玩和平精英嗎","清理一下聽懂灰塵"糾正為"清理一下聽筒灰塵"等雖然沒有引入知識庫,但是對於語料數據分布的頭部知識仍然是可以糾正的,比如"芒種"、"和平精英"、"新冠肺炎"等,在語料中的占比比較高,但是對於尾部的知識,該模型糾錯效果並不理想。
04
未來的方向

這三個方向是未來考慮的重點,另外還可以將模型中使用的N-gram語言模型替換成其他強語言模型,增加任務的難度,進而可能提高糾錯任務的表現。 今天的分享就到這裏了,謝謝大家!嘉賓介紹:

魏天聞
小米人工智慧部 | 小愛基礎演算法 團隊負責人
本科畢業於武漢大學數學系,博士畢業於法國里耳一大數學系,主要研究領域包括獨立成分分析 、非監督表示學習、語言模型等,有多篇論文發表於IEEE Trans. Information Theory, IEEE Trans. Signal Processing、ICASSP等知名學術期刊或會議上。魏天聞於2018年加入小米人工智慧部,目前主要負責小愛同學語言模型有關演算法研發與落地。
分享嘉賓:魏天聞 小米人工智慧部
編輯整理:李淑娜
內容來源:DataFunTalk











