作者|依婷
編輯|漠影
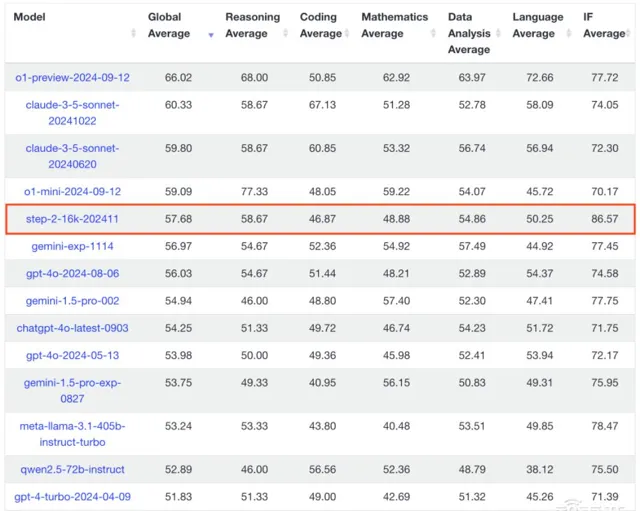
智東西11月20日報道,LLM基準測試計畫LiveBench官網最新榜單顯示,中國大模型「六小虎」之一階躍星辰的大語言模型step-2-16k-202411,總評分位列全球第五、國產第一。同時,在六類別任務中,step-2-16k-202411的指令跟隨(IF Average)評分排名第一,比OpenAI的o1-preview-2024-09-12更高。
▲LiveBench榜單總評分前15名
LiveBench計畫由Abacus.AI主導,圖靈獎得主、Meta首席AI科學家楊立昆(Yann Lecun)參與其中,因其每月更新問題、評分體系客觀,被業內稱為「最難糊弄的LLMs基準測試」。
成功挑戰LiveBench的step-2-16k-202411,是階躍星辰自研的萬億參數MoE大語言模型。在設計Step-2 MoE架構時,階躍星辰放棄upcycle(向上復用)路徑,選擇從頭開始訓練,透過部份專家共享參數、異構化專家設計等方式創新MoE架構設計。今年3月,Step-2預覽版釋出,成為國內第一個由創業公司釋出的萬億參數MoE大語言模型。
目前,階躍星辰已釋出包括萬億MoE大語言模型Step-2、多模態理解大模型Step-1.5V、影像生成模型Step-1X在內的Step系列模型 「全家桶」,以及C端套用「躍問」和「冒泡鴨」。
基準測試是大模型的「高考」,考試成績在很大程度上影響了大模型的套用和商業價值。如今基準測試五花八門,LiveBench的評分結果為什麽如此具有參考價值?行業日新月異,在眾多國產大模型中,為什麽階躍星辰得以闖入世界級賽場,和OpenAI、Anthropic同台競技?透過拆解LiveBench榜單以及階躍星辰的大語言模型Step-2,我們找到了答案。
一、國產大模型與OpenAI同台競技
今年6月中旬,LiveBench計畫正式釋出,計畫團隊在創始部落格中給它下了個定義——「具有挑戰性、無汙染的LLM基準測試(A Challenging, Contamination-Free LLM Benchmark)」,計畫參與方名單裏,楊立昆、紐約大學、輝達、南加州大學等在AI領域頗具話語權和關註度的主體赫然在列。

▲LiveBench官網部落格
除了諸多著名的參與方,LiveBench更受業界關註的特點是,在設計時考慮了測試集汙染問題,盡可能保證評分結果的客觀真實。具體而言:
1、它們根據最新釋出的數據集、arXiv論文、新聞報道和IMDb電影概述設計問題,每月更新題庫,以此來限制潛在的汙染,防止大模型在回答時作弊;
2、保證每個問題都有可驗證的、客觀真實的答案,可以對難題進行精確、自動評分,不透過LLM評分,避免落入LLM的判斷陷阱,如對自己答案的偏見以及對答案的錯判;
3、目前包含推理、編碼、數學、數據分析、語言理解、指令跟隨等六個類別、18項任務,並將隨著時間的推移釋出更新、更難的任務。
簡而言之,LiveBench每月都用全新題庫考驗各家大模型,並在無人工、無大模型參與評分的情況下進行更為準確、客觀的排名。
就是在這樣一個頗具權威性和公平性的基準測試中,階躍星辰的step-2-16k-202411位列全球第五,也是榜單前十中唯一一個國產大模型。
LiveBench榜單第一到第四名分別是o1-preview-2024-09-12、claude-3-5-sonnet-20241022、claude-3-5-sonnet-20240620、o1-mini-2024-09-12,被OpenAI和Anthropic兩家美國AI獨角獸占據,之後便是階躍星辰的step-2-16k-202411;谷歌的gemini-exp-1114排名第六位。
從任務類別來看,step-2-16k-202411在指令跟隨(IF,Instruction Following)方面以86.57的評分位列第一,排名第二的是谷歌的大模型gemini-1.5-flash-002,評分為84.55,在階躍星辰之後。
根據LiveBench介紹,指令跟隨類別包括四項子任務,即在遵循一個或多個指令,如字數限制或在答案中加入特定元素的基礎上,根據【衛報】的最新報道,解釋、簡化、總結或生成故事。step-2-16k-202411在該類別的高得分,展現了其在語言生成上對細節有超強的控制力,能夠更好地理解和遵循人類指令。
二、放棄捷徑,Step-2創新MoE架構從頭開始
階躍星辰Step-2的高排名源於團隊對演算法架構的創新。
今年3月,Step-2預覽版釋出,成為國內第一個由創業公司釋出的萬億參數模型;7月世界人工智慧大會上,Step-2正式釋出,當時在數理邏輯、編程、世界知識、指令跟隨等方面體感就全面逼近GPT-4。
具體而言,Step-2具備出色的理解能力,能夠從上下文中推斷出使用者的需求,精準捕捉使用者在模糊指令中的真實意圖,提供更準確、個人化的響應;
在知識覆蓋範圍和深度上,Step-2不僅能夠處理常見領域知識,還能深入理解和回答在特定領域或邊緣分布中的復雜問題;
在生成高品質、有創意的文字內容的同時,Step-2具備出色的細節控制能力,能夠根據使用者的指令對文本進行精確地調整和最佳化。比如在創作古詩詞時,對字數、格律、押韻、意境都可以做到精準把握。
研發階段,階躍星辰對演算法架構的創新成為Step-2的制勝法寶。
目前,訓練MoE模型主要有兩種方式——一是基於已有模型透過upcycle(向上復用)開始訓練,二是從頭開始訓練。前者對算力的需求低、訓練效率高,但上限低,如基於拷貝復制得到的MoE模型容易造成專家同質化嚴重;後者訓練難度高,但能獲得更高的模型上限。
階躍星辰選擇了第二條,也是一條更難的路。
在設計Step-2 MoE架構時,該公司團隊完全自主研發、從頭開始訓練模型,透過部份專家共享參數、異構化專家設計等方式創新MoE架構設計,讓Step-2中的每個「專家模型」都得到充分訓練,Step-2不僅總參數量達到了萬億級別,每次訓練或推理所啟用的參數量也超過了市面上的大部份Dense模型。
相比於Step-1千億參數大語言模型,Step-2的綜合能力提升了近50%。目前,Step-2已接入階躍星辰旗下效率工具「躍問」。開發者可以在階躍星辰開放平台,透過API接入使用 Step-2。
三、「最低調的學生」跑出高分,國產大模型未來可期
階躍星辰成立於2023年4月,但在2024年3月才帶著Step系列通用大模型正式面對公眾。它就像是班級裏那個最低調的學生,平日裏埋頭苦學,在考試的時候憑高分一鳴驚人。
目前,階躍星辰已對外釋出Step系列通用大模型矩陣,覆蓋從千億參數到萬億參數,從語言到多模態,從理解到生成的全面能力。
模型更新叠代的同時,產品套用也沒落下。今年9月,在多模態大模型Step-1.5V的支持下,躍問App上線「拍照問」,不僅能辨識圖片中的物體並轉譯成英文,還能幫助健身人士飯前算算卡路裏。由於該功能實在火爆,網路還有躍問10月前20天投流1500萬的傳言,但後續被辟謠。
目前,在全球AI賽場上,國產大模型仍然屈指可數,中國AI獨角獸們還有很多隱憂未解,階躍星辰的技術路徑或授權以為初創公司們提供一個參考樣本。











