如果你對數據分析感興趣,希望學習更多的方法論,希望聽聽經驗分享,
歡迎移步寶藏公眾號 「小火龍說數據」 ,無廣告、無軟文、純幹貨,更多精彩原創文章與你分享!
00 序言
在日常產品叠代過程中,我們常常需要去驗證某個功能、策略的改動是否符合預期,是否可以完全替代現有的方案。小流量實驗往往是最常用、最直接驗證因果的方式。然而有些時候,由於忘記開展實驗、實驗成本較高等因素,沒有對策略進行AB實驗,但又希望評估策略效果,這個時候,則可以透過其他因果推斷方式進行佐證。
因果推斷的基石在於盡量保障策略差異是唯一的變量,核心步驟涵蓋兩點:
其一:構造兩組相似的使用者群體,群體差異越小越好。
其二:度量策略對群體的影響程度,聚焦核心指標的變化。
以下幾類方式是因果推斷中常用到的,如下圖所示。

下面,將對每個模組的方式進行展開說明。
01 Matching
因果推斷的前提條件,是構造兩個近似完全一樣的樣本群體,一般情況下,樣本群體=使用者群體。保證使用者群體一致最直接的方式,則是一一匹配,即:保證微觀單體使用者一致,擴充套件到整體也是一致的。這種透過treated使用者去匹配no treated使用者的方式,稱之為Matching,常見的Matching方式有以下幾種,如下圖所示。
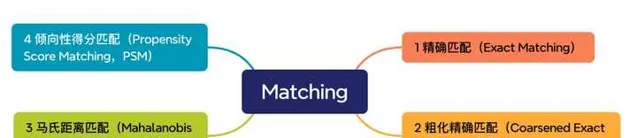
精確匹配(Exact Matching)
最理想的方式是對兩組單體使用者一一精準匹配,保障單體使用者特征完全一樣,例如:實驗組單體使用者「18歲+一線城市+男性+本科+互聯網行業」與對照組單體使用者「18歲+一線城市+男性+本科+互聯網行業」相匹配。
理論上,此種方式匹配出來的使用者最為精準,不過其存在一定的局限性。
一方面,需要兩組內有足夠多的群體用於匹配;
另一方面:適配維度不宜過多,過多的維度會導致很難匹配到完全一致的樣本。
粗化精確匹配(Coarsened Exact Matching,CEM)
同學們思考一下,如果是連續特征,要如何進行精確匹配呢?例如:收入、支出、開啟軟體次數等。涵蓋連續特征的使用者,找到相同的機率會大打折扣。
這裏,可以在精確匹配的基礎上做一點改動,將連續特征分段離散化,然後再進行精確匹配。例如:開啟軟體次數的範圍是0→+∞,可將連續變量分段成[0,5),[5,10),[10,+∞)等。
馬氏距離匹配(Mahalanobis Distance Matching,MDM)
雖然EM、CEM可以相對精準一一匹配使用者,然而隨著維度的增加,精準匹配使用者的可用性會逐步減弱。
面對這種情況,可以退而求其次,增加相容機制,透過計算距離的方式,近似匹配相似的使用者,如能精準匹配相同使用者,則距離為0;如不能精準匹配,則逐一選擇距離最近的使用者。
此種方式最大的局限性在於效率,假設實驗組M個使用者,對照組N個使用者,則其計算量為M×N,當樣本量與特征均較高時,該種方式的效率會非常低(同分類模型KNN原理一致)。
傾向性得分匹配(Propensity Score Matching,PSM)
PSM是在MDM方式上的一種最佳化,其本質是將高維特征對映到一維傾向分上,然後再在不同label中尋找相近的傾向分使用者。這裏的傾向分,代表了多維特征整體數值的表現,該值越接近,則兩樣本的整體特征越相似。
同樣,PSM也會有一定的局限性和弊端。
其一:對於樣本量有要求,如果樣本量過少,會導致匹配的樣本距離過遠,達不到真實的相似要求。
其二:對於模型的訓練要求較高,會出現兩使用者各特征並不相似,但傾向性分很相近的情況,即:資訊折損。
02 Weighting
Weighting的核心思想,是將實驗組與對照組使用者群體內各類人群比例,調整到同大盤一樣的標準,從宏觀上保證其樣本量的同質。
本質上,Matching是對樣本進行重采樣和丟棄,同Weighting的核心思想一致,其不一樣的地方主要體現在以下兩方面上。
其一: Matching是以treated群體為標桿去匹配no treated群體,驗證的是treatment給實驗組使用者帶來的影響;而Weighting是以大盤使用者為標桿去匹配群體,驗證的是treatment給大盤使用者帶來的影響。
其二: 由於Matching在重采樣中存在隨機性,因此魯棒性沒有Weighting強。
03 Regressing
Regressing同Matching、Weighting思路完全不同,不再為treated群體樣本一一匹配,而是透過預測來估計treated群體樣本落在對照組的指標表現情況。其將實驗組使用者指標Y,拆解為「協變量+treatment」,以此來計算實驗組樣本在對照組的量級,再透過計算差值得到策略對指標的影響程度。
04 Other Method
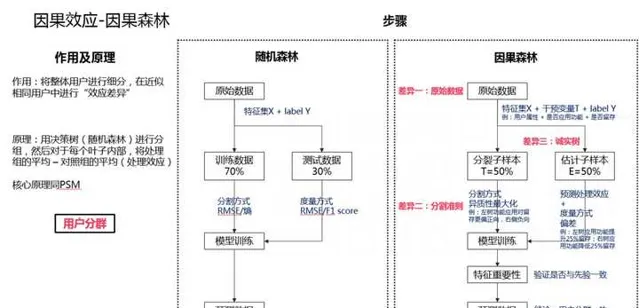
其他方式還有很多,如下圖所示。

其中套用較多的是雙重拆分法、因果森林。
雙重拆分法(Difference in Difference,DID)

因果森林
05 總結一下
可能有些同學會問,既然有這麽多種因果推斷的方式,那為什麽還要做AB實驗呢?
其實無論是哪種方式,均存在一定的假設和局限性。歸總來看,小流量實驗仍然是最科學、最直接的方式,因此,在有能力做AB實驗的前提下,優先透過此種方式進行驗證。
數據分析資料(獲取可戳連結):
面試輔導(獲取可戳連結):
以上就是本期的內容分享
如果你也對數據分析感興趣,那就來關註我吧,更多「原創」文章,與你分享!!
微信公眾號:小火龍說數據












