論文題目: CN-RMA: Combined Network with Ray Marching Aggregation for 3D Indoor Object Detection from Multi-view Images
作者:Guanlin Shen,Jingwei Huang等
作者機構:School of Software, Tsinghua University, China ,Tencent, China等
論文連結:https:// arxiv.org/pdf/2403.0419 8.pdf
程式碼連結:https:// github.com/SerCharles/C N-RMA
這篇論文介紹了一種名為CN-RMA的新方法,用於從多視角影像中檢測3D室內物體。該方法利用了3D重建網路和3D物體檢測網路的協同作用,透過重建網路提供的粗略距離函式和影像特征的投票,在解決影像和3D對應關系模糊性的挑戰上取得了成功。具體而言,透過射線行進為每條射線的采樣點分配權重,表示影像中一個像素對應的3D位置的貢獻,並透過預測的有符號距離確定權重,使影像特征只投票到重建表面附近的區域。該方法在ScanNet和ARKitScenes數據集上實作了最先進的效能。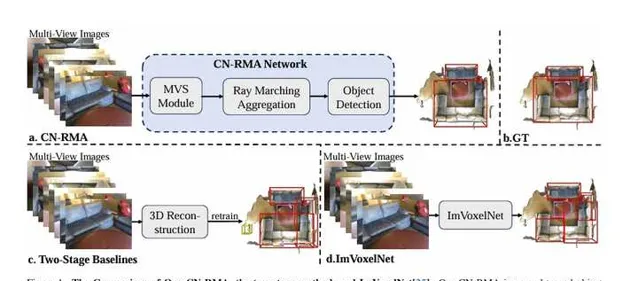
讀者理解:
本文介紹了一種名為CN-RMA的新方法,用於從多檢視影像中進行室內3D物體檢測。該方法透過引入一種名為Ray Marching Aggregation(RMA)的技術,能夠有效地將2D特征聚合到3D點雲中,並考慮了遮擋情況,從而在效能上超越了先前的方法。作者還對該方法進行了詳細的實驗驗證,並與其他方法進行了比較,結果表明CN-RMA在兩個數據集上均取得了優越的效能。
原文連結:清華最新! CN-RMA:CVPR'24 多視角3D室內物體檢測我認為這項研究在解決室內3D物體檢測問題上具有重要意義。透過有效地利用多檢視影像和引入遮擋感知的聚合技術,CN-RMA能夠更準確地檢測物體,這對於室內環境中的智慧機器人和自動駕駛等套用具有很大的潛在套用價值。作者提出的方法也為未來相關研究提供了新的思路和方法,有助於推動這一領域的發展。
1 引言
這篇論文提出了一種名為CN-RMA的新方法,用於從多視角影像中檢測3D物體。傳統方法是先從多視角影像中重建3D場景,然後從重建的點雲中進行物體檢測,但這種方法存在兩個階段之間缺乏連線性的問題。本文提出的方法透過將重建網路和檢測網路無縫結合,並引入遮擋感知的特征聚合模組,有效地解決了這一問題。具體而言,該方法首先使用多視角立體匹配(MVS)模組重建粗略的場景幾何,然後利用名為射線行進聚合(RMA)的遮擋感知聚合模組,在3D空間中聚合影像特征,並在重建表面附近提取具有聚合特征的點雲進行物體檢測。透過預訓練和微調整個網路,使其各元件協同工作,達到最佳效能。該方法在ScanNet和ARKitScenes數據集上取得了顯著的效能改進,包括[email protected]和[email protected]方面分別提高了3.2和3.0在ScanNet中,以及在ARKitScenes中分別提高了7.4和13.1。這表明了該方法在室內多視角影像中的3D物體檢測任務上取得了最先進的效能。
本文貢獻:
2 方法
2.1 問題表述
本研究旨在利用多視角影像及其相應的相機參數,在復雜的遮擋場景中實作精確的3D物體檢測。為此,提出了一個流程,透過結合MVS重建模組和3D檢測網路,並引入了遮擋感知的特征聚合方法,實作了該目標。流程包括以下步驟:
2.2 多視角立體匹配模組
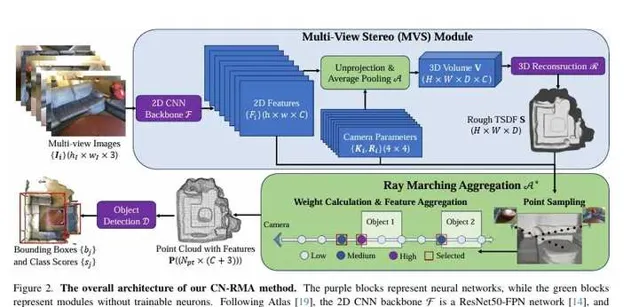
本節介紹了多視角立體匹配模組(MVS),旨在透過多視角影像和相應的相機參數實作精確的3D物體檢測。為此,使用Atlas作為MVS模組,它可以以端到端的方式訓練和使用來預測重建,包括一個2D骨幹和一個3D重建網路。具體步驟包括:
這種方法可以避免遺漏檢測,並在訓練中提高泛化能力。

2.3 射線行進聚合
本節介紹了射線行進聚合(RMA)方法,用於改進在重建階段透過直接平均提升的影像特征來預測3D特征體積的方法。由於影像特征可能會投票到未觀測到的空間,造成體積特征受到某些檢視的汙染,因此需要處理遮擋。為了提高魯棒性,引入了一種軟遮擋感知聚合方案RMA,靈感來自於NeRF和NeuS。具體而言,根據NeuS,作者根據TSDF計算體積密度。透過射線行進在每個像素的射線上采樣點,並根據NeRF累積透射率來計算每個點的不透明度。因此,可以透過加權平均影像特征來計算3D特征,權重由不同檢視的透射率確定。最終,提取接近重建表面的點和聚合特征,並將點雲傳遞給3D檢測模組進行物體檢測。
2.4 3D物體檢測網路
本節介紹了3D物體檢測網路,該網路接收重建的點雲和聚合特征P作為輸入,使用FCAF3D作為檢測網路。首先,將P轉換為稀疏體素,並傳遞給FCAF3D以預測每個體素的分類分數、邊界框回歸參數和3D中心度。檢測損失由焦點損失、IOU損失和二元交叉熵損失組成,用於監督網路的訓練。
2.5 訓練過程
本節討論了訓練過程。由於架構復雜,同時結合了MVS模組和檢測網路,因此從頭訓練可能導致過擬合。為了解決這個問題,采用了預訓練和聯合微調的方案。首先,對2D骨幹和3D重建網路進行預訓練,利用重建損失以充分利用3D幾何資訊。然後,凍結這些網路,進行3D檢測網路的預訓練,只考慮檢測損失。最後,透過聯合微調整個網路,平衡重建損失和檢測損失,以獲得最終的3D檢測結果。

3 實驗
實驗部份主要包括以下內容:
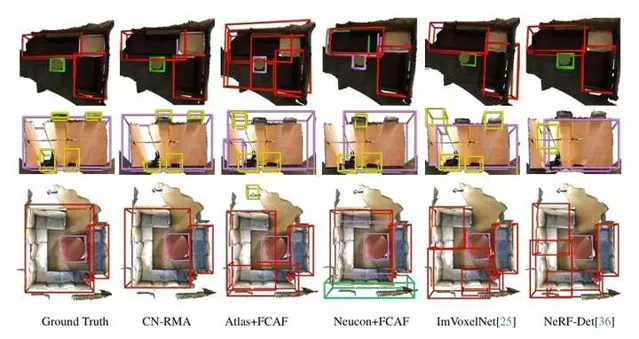
數據集、指標和基線方法:使用了兩個室內物體檢測數據集,分別是ScanNet和ARKitScenes。ScanNet包含1201個訓練掃描和312個測試掃描,檢測使用軸對齊邊界框(AABB);ARKitScenes包含4498個訓練掃描和549個測試掃描,檢測使用定向邊界框(OBB)。評估指標為[email protected]和[email protected]。基線方法包括ImVoxelNet、NeRFDet和ImGeoNet,以及兩階段基線方法,其中Atlas和NeuralRecon用於重建3D點雲,FCAF3D用於3D檢測。
實作細節:使用MMDetection3D框架實作CN-RMA方法,設定特征通道數為32,聚合方法的權重閾值為0.05,損失權重為0.5。在射線行進中,為每個像素采樣300個點,最大t設定為體積V的對角線長度。所有實驗在4個NVIDIA A6000 GPU上進行,批大小為1。
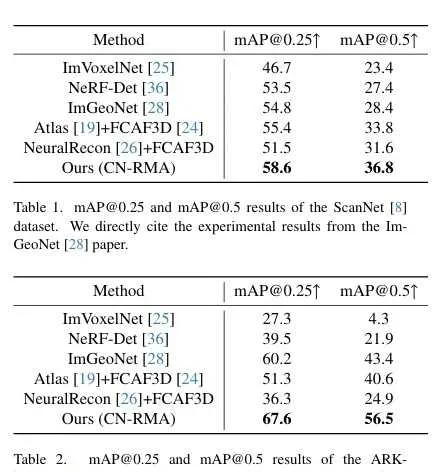
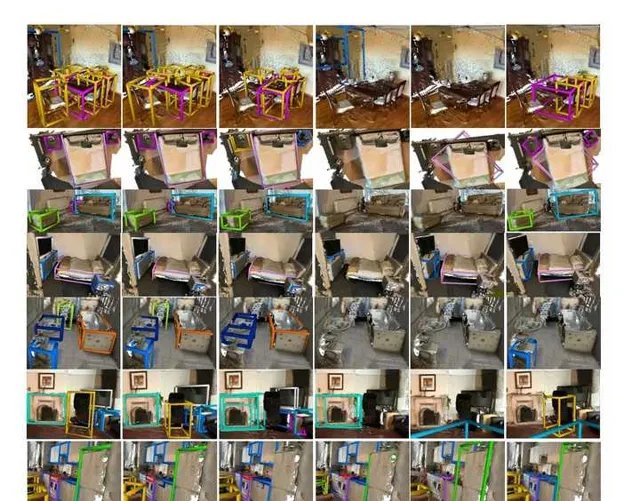
比較結果:在ScanNet和ARKitScenes數據集上,CN-RMA方法表現優異,[email protected]和[email protected]均優於其他方法。與ImGeoNet相比,在ScanNet上[email protected]提高了3.8,[email protected]提高了8.4,在ARKitScenes上[email protected]提高了7.4,[email protected]提高了13.1。與Atlas和FCAF3D組合的兩階段基線相比,在ScanNet上[email protected]提高了3.2,[email protected]提高了3.0,在ARKitScenes上[email protected]提高了16.3,[email protected]提高了15.9。
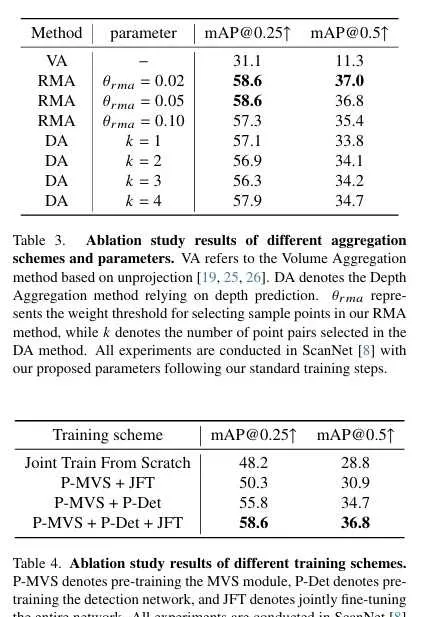
消融研究:對不同聚合方案和超參數進行了消融研究,結果表明RMA方法在選擇樣本點的權重閾值為0.05時表現最佳。另外,對不同訓練方案進行了消融研究,結果表明預訓練MVS模組和檢測網路,然後聯合微調整個網路可以取得最佳效能。
4 總結
本文介紹了一種新穎的從多檢視影像中進行室內3D物體檢測的方法CN-RMA。作者的方法超越了先前的最先進方法,並優於兩階段基線。作者還提出了一種有效的考慮遮擋的技術,透過粗糙的場景TSDF將2D特征聚合到3D點雲中,這對於將其整合到其他從多檢視影像中理解3D場景的任務中具有潛力。未來的工作應集中於探索進一步提高CN-RMA效能的技術,例如研究替代的聚合方案或整合額外的上下文資訊,這可能是有益的。作者期待透過解決這些限制並建立在我們的研究成果基礎上,進一步推動3D室內物體檢測和相關研究領域的進展。

移步公眾號「3D視覺工坊」第一時間獲取工業3D視覺、自動駕駛、SLAM、三維重建、最新最前沿論文和科技動態。
推薦閱讀
1、基於NeRF/Gaussian的全新SLAM演算法
2、移動機器人規劃控制入門與實踐:基於Navigation2
3、自動駕駛的未來:BEV與Occupancy網路全景解析與實戰
4、面向三維視覺的Python從入門到實戰
5、工業深度學習異常缺陷檢測實戰
6、Halcon深度學習計畫實戰系統教程










