或者這篇文章能給提問者一個新的思路,了解一下在自動駕駛領域,決策AI(RL)與SLAM的結合將會碰撞出什麽樣的火花~衷心希望能夠幫助到提問者。
以下是正文部份:
自動駕駛是一項人類憧憬已久的人工智慧技術。在許多科幻文藝作品中,自動駕駛都是未來人機共融世界中的「標配」。一百多年前的人們就已經在構想,未來世界完全不需要人類手動控制就可以馳騁在高速公路上的場景。

在學術界和工業界中,雖然自動駕駛已經被研究了數十年,但距離文藝作品中想象的套用能力,仍然有一定的距離。
究其原因,自動駕駛是一個多學科交叉的系統,其中的核心模組可大致劃分為三個模組: 感知、決策、和控制 ,而每個模組下都有許多細分的亟待解決的問題。
在感知模組中,空間位置的感知是自動駕駛車輛能夠實作自主運動的基石,其對應的學術問題於1986年被明確定義並提出,被稱為SLAM。
在決策型AI發展大行其道的當下,SLAM技術能為決策型AI帶來哪些耦合影響,二者在自動駕駛任務中的聯系和區別又有哪些呢,本文將簡單地介紹這些問題。
一、讓我們來談一談什麽是SLAM
從模組功能的角度來說,如果只想知道智慧體周圍有哪些物體和他們的位置,那麽只需要以深度學習為主要技術手段的 目標檢測或例項分割 就可以了。但如果還想要智慧體能夠 自主在環境中運動和避障 ,就需要使用SLAM技術了。
SLAM的全稱是simultaneous localization and mapping,即同步定位與建圖 ,它解決的是一個智慧體在未知環境當中 感知並定位 周圍環境和自身,並隨著自身運動逐漸掌握所在環境整體地圖的能力。
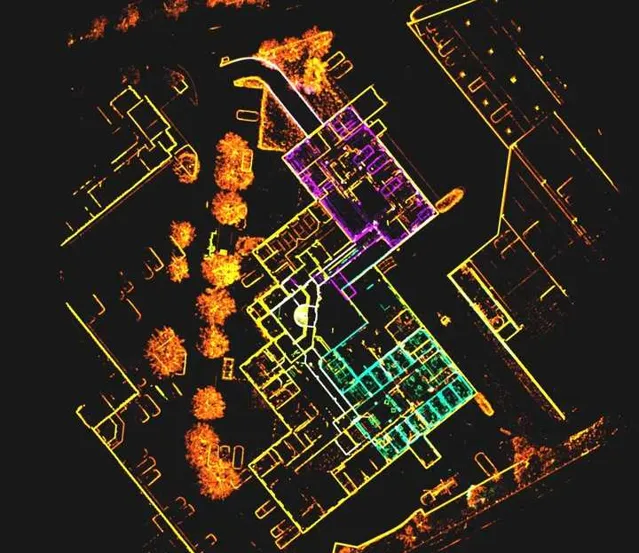
SLAM可以構建世界的3D環境模型,同時確認自身在環境中的位姿,它關註的是 空間幾何資訊 。這一過程類似於遊戲中的「開地圖」,一個被控制的單位不僅能感知到周圍的一圈地圖元素,在行進的過程中也把歷史資訊融入進來,畫成了一個「小地圖」。
對自動駕駛任務來說,雖然現在基於衛星定位的高精地圖導航可以做到對自車的精準定位,但限於 精度和網路傳輸問題 ,在駕駛的局部區域還是需要SLAM技術來為車輛的駕駛提供更精細的感知資訊。
目前SLAM演算法可以分為 跟蹤和建圖 兩個主要部份。
顧名思義, 跟蹤部份 主要負責以建立的環境模型或是歷史的傳感觀測為參考系,估計智慧體或車輛的位姿;而 建圖部份 則是使用已估計的位姿序列將環境的三維模型建立。

環境模型根據地圖的尺度絕對性可以劃分為 柵格地圖、拓撲地圖和米制地圖 ;根據環境資訊的表征層級可以劃分為物體(語意)級地圖和特征地圖,後者又可以根據點的稠密程度可以劃分為稀疏地圖和稠密地圖。目前SLAM演算法僅考慮自身的參考定位需求,往往僅構建稀疏點特征地圖。
傳統的SLAM演算法僅需將對輸入的傳感量測序列對映為位姿軌跡序列和環境模型即可。 但在實際套用中,人們發現某些運動過程不利於定位跟蹤,比如快速的旋轉運動;環境中的部份區域往往需要更完備地傳感觀測才能建立出滿足套用需求的環境模型;以及采集到的傳感數據並不能覆蓋整個需要探索感知的環境等等。
因此,有學者提出了 主動SLAM 的概念,即智慧體在進行SLAM的同時,根據當前定位和所建模型的不確定性,主動控制自身的運動以提高環境探索效率,定位和建模精度。就好比為了更好的探索未知的或不確定的環境,派一個「小弟」專門前去看看,對建圖問題的解決更加有益。
二、決策AI,全自動駕駛離不開的關鍵技術
決策AI是以 強化學習 為代表的,不同於感知型AI的新型人工智慧技術。強化學習是機器學習方法的一種,其基於本體於環境互動過程中獲得的反饋指導策略模型為前進演化方向。因此,強化學習一般用於處理決策規劃型的問題,比如代替遊戲玩家、控制智慧汽車、構建推薦系統等等。
標準化的強化學習演算法由 環境、狀態、行動、獎勵和智慧體 五個元素構成。
環境 是智慧體所處的空間; 狀態 是指智慧體進行決策時所需要的資訊集合,一般既包括智慧體所處環境的描述,也包括智慧體自身境況的描述,比如位置、速度等等; 行動 是智慧體所能和環境進行互動的方式,也可理解為所能選擇的決策集合; 獎勵 則是由環境對智慧體所選擇的行動給出的反饋。

隨著深度學習所展現出的強大的從高維數據中尋找到低維結構的能力,當前強化學習演算法所使用的模型一般為神經網路模型。於是強化學習也就變成了深度強化學習。
雖然強化學習已經被研究多年,但其距離實際套用依然有一定距離。以本文所關註的自動駕駛為例,自動駕駛車輛所搭載的傳感器一般以視覺系統為主。
然而,雖然從傳感到動作這種端到端的處理方式備受追捧,但是如果直接將原始獲得的視覺觀測影像作為強化學習的狀態輸入智慧體,往往並不能將模型訓練得多好。
這主要是由於視覺影像本身就處於 高維流形 上,視覺模型的訓練需要大量的數據,而強化學習方法的標簽比監督學習要稀疏的多。到目前為止,用強化學習方法從視覺影像中提取有價值的資訊並沒有完全解決,無論是是重建出影像所拍攝場景的三維模型,亦或是估計觀察到該幅影像所可能的空間位置。
即便是檢測影像中是否存在目標物體,在目標檢測各類榜單已經被刷爆的當下,采用強化學習,這種以環境反饋為為指引模型前進演化方向的學習方式下,依然困難重重。
三、決策AI與SLAM結合,會產生怎樣的火花
經過以上介紹,我們想到,是否可以利用SLAM這項成熟的技術與強化學習方法結合來更好的解決二者的問題呢?答案是肯定的,大體上來說,二者的結合在以下兩個層面可以發揮作用,為自動駕駛套用中的一些問題提供解決方案。
1. SLAM建模的環境可考慮作為強化學習的狀態輸入
為了應對前文所介紹的使用強化學習端到端地處理原始傳感數據遇到的問題,目前許多研究者已經轉向了多層次強化學習的構建。
如TRO20年的一篇研究[1]提出將智慧體的視覺導航解耦為兩個階段解決,第一階段使用目標網路,將視覺傳感觀測轉為所要運動到的目標點。而第二階段,則是使用探索網路,控制智慧體到達目標點。這樣就將原本狀態量中的高維影像矩陣對映為僅有幾位數值即可表征環境資訊和智慧體狀態資訊的地位向量。
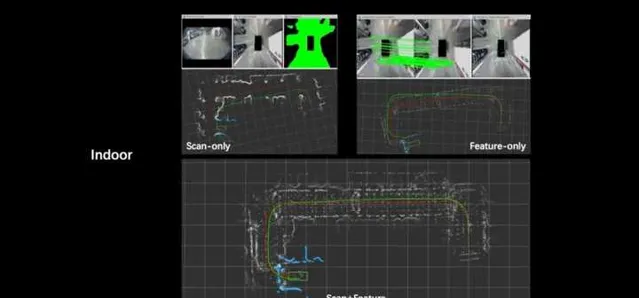
諸如此類的體系設計還有很多。然而使用網路對環境建模的方式看似「智慧「,但實際上效率較低,可解釋性也欠缺。在實際套用中的建模精度、路徑規劃安全性和可執行性都無法保證。
而SLAM模組已經具備解析地重建環境模型的能力。完全可以取代前文中第一階段的模型,完成任務的需求。
具體說來,可以設計相應的SLAM建圖模組,使得SLAM所建立的環境模型能夠標準化、統一地作為狀態集合中的子集,並被強化學習模組所直接使用。此外,強化學習在完成任務規劃決策時, 可以同時將自身定位和環境模型的不確定度納入考慮 (這些資訊也是SLAM演算法可以提供的)。這樣做也更加符合智慧體實際的傳感感知能力。
2.強化學習的動作選擇可提升SLAM建模環境的效率
目前主動SLAM所需要具備的智慧體探索路徑規劃和運動控制,仍然缺少好的解決思路。 強化學習作為決策模型中最具有智慧化潛質的一種,完全具備套用在主動SLAM中扮演規控大腦的能力。
Botteghi[2]已經在這個方向上做了探索,基於簡單的DQN和特別設計的獎勵函式,便提高了主動SLAM探索環境並建立模型的效率。
事實上,在SLAM建立未知環境的地圖時,智慧體的運動路徑不僅會影響其所建的環境地圖是否將整個環境都覆蓋,還會直接影響智慧體定位的精度,從而間接決定了環境重建的品質。

比如,在環境紋理稀疏時,處於轉彎角度較大的拐角時,甚至是相機視角狹窄的配置下,如果智慧體運動速度過快,往往都會導致特征點跟蹤遺失,從而使得整個SLAM演算法失效。
另外,對於SLAM演算法來說,如果能夠及時地構成運動路徑閉環,對於消除定位過程中的累積誤差,避免視點漂移都有極大的利好。
上述這些需求就不再是簡單的規劃位移級的路徑,而需要到速度級甚至是加速度級。而另一方面,目前尚沒有成熟的演算法能夠尋找到視覺觀測到基於其進行理想的SLAM任務所需要的運動狀態之間對映關系。但運動動作所導致的定位和建圖結果則能直接地提供反饋,而這恰恰符合強化學習所能解決的問題的特征。
OpenDILab目前就正在做一款自動駕駛領域的研究平台: DI-drive ,支持各種模仿學強化學習等決策演算法,支持 多模態型別的輸入輸出,支持高度客製的視覺化模組 ,為自動駕駛和決策 AI 搭建了至關重要的橋梁。DI-drive 嘗試構建了一些以俯檢視作為輸入狀態的決策AI駕駛環境,這與SLAM想要構建的環境模型與地圖理解有共同之處,可以作為SLAM與決策AI結合的一個切入點,歡迎大家體驗使用。


⭐️ 歡迎大家體驗DI-drive:
總結 可以想象,有了強化學習的參與,SLAM過程的定位會更精確,重建模型的品質更高;而有SLAM幫助解析的環境和智慧體自身訓練,由強化學習訓練得到的用於生成自動駕駛路徑規劃軌跡的模型訓練可以更簡單,也就更容易收斂,從而讓決策AI 能夠更高效地解決自動駕駛任務。
參考文獻
[1] Devo, Alessandro,et al. "Towards generalization in target-driven visual navigation by using deep reinforcement learning." IEEE Transactions on Robotics 36.5 (2020): 1546-1561.
[2] Botteghi,N.,et al. "Reinforcement learning helps slam: Learning to build maps." The International Archives of Photogrammetry, Remote Sensing and Spatial Information Sciences 43 (2020): 329-335.
✨營運:mugicaxu
✨排版:yicc












